- Elastic Security: other versions:
- Elastic Security overview
- What’s new in 8.8
- Upgrade Elastic Security to 8.8.2
- Post-upgrade steps (optional)
- Get started with Elastic Security
- Elastic Security system requirements
- Elastic Endgame requirements
- Spaces and Elastic Security
- Data views in Elastic Security
- Ingest data to Elastic Security
- Install and configure the Elastic Defend integration
- Elastic Endpoint requirements
- Configure offline endpoints and air-gapped environments
- Configure an integration policy for Elastic Defend
- Enable threat intelligence integrations
- Configure advanced settings
- Uninstall an endpoint
- Elastic Security UI
- Security Assistant
- Dashboards
- Explore
- Anomaly detection with machine learning
- Detections and alerts
- Create a detection rule
- Manage detection rules
- Monitor and troubleshoot rule executions
- Rule exceptions
- About building block rules
- Manage detection alerts
- Reduce notifications and alerts
- Visual event analyzer
- Query alert indices
- Tune detection rules
- Prebuilt rule changes per release
- Prebuilt rule reference
- A scheduled task was created
- A scheduled task was updated
- AWS CloudTrail Log Created
- AWS CloudTrail Log Deleted
- AWS CloudTrail Log Suspended
- AWS CloudTrail Log Updated
- AWS CloudWatch Alarm Deletion
- AWS CloudWatch Log Group Deletion
- AWS CloudWatch Log Stream Deletion
- AWS Config Resource Deletion
- AWS Configuration Recorder Stopped
- AWS Credentials Searched For Inside A Container
- AWS Deletion of RDS Instance or Cluster
- AWS EC2 Encryption Disabled
- AWS EC2 Full Network Packet Capture Detected
- AWS EC2 Network Access Control List Creation
- AWS EC2 Network Access Control List Deletion
- AWS EC2 Snapshot Activity
- AWS EC2 VM Export Failure
- AWS EFS File System or Mount Deleted
- AWS ElastiCache Security Group Created
- AWS ElastiCache Security Group Modified or Deleted
- AWS EventBridge Rule Disabled or Deleted
- AWS Execution via System Manager
- AWS GuardDuty Detector Deletion
- AWS IAM Assume Role Policy Update
- AWS IAM Brute Force of Assume Role Policy
- AWS IAM Deactivation of MFA Device
- AWS IAM Group Creation
- AWS IAM Group Deletion
- AWS IAM Password Recovery Requested
- AWS IAM User Addition to Group
- AWS KMS Customer Managed Key Disabled or Scheduled for Deletion
- AWS Management Console Brute Force of Root User Identity
- AWS Management Console Root Login
- AWS RDS Cluster Creation
- AWS RDS Instance Creation
- AWS RDS Instance/Cluster Stoppage
- AWS RDS Security Group Creation
- AWS RDS Security Group Deletion
- AWS RDS Snapshot Export
- AWS RDS Snapshot Restored
- AWS Redshift Cluster Creation
- AWS Root Login Without MFA
- AWS Route 53 Domain Transfer Lock Disabled
- AWS Route 53 Domain Transferred to Another Account
- AWS Route Table Created
- AWS Route Table Modified or Deleted
- AWS Route53 private hosted zone associated with a VPC
- AWS S3 Bucket Configuration Deletion
- AWS SAML Activity
- AWS STS GetSessionToken Abuse
- AWS Security Group Configuration Change Detection
- AWS Security Token Service (STS) AssumeRole Usage
- AWS VPC Flow Logs Deletion
- AWS WAF Access Control List Deletion
- AWS WAF Rule or Rule Group Deletion
- Abnormal Process ID or Lock File Created
- Abnormally Large DNS Response
- Accepted Default Telnet Port Connection
- Access of Stored Browser Credentials
- Access to Keychain Credentials Directories
- Access to a Sensitive LDAP Attribute
- Accessing Outlook Data Files
- Account Configured with Never-Expiring Password
- Account Discovery Command via SYSTEM Account
- Account Password Reset Remotely
- Account or Group Discovery via Built-In Tools
- AdFind Command Activity
- Adding Hidden File Attribute via Attrib
- AdminSDHolder Backdoor
- AdminSDHolder SDProp Exclusion Added
- Administrator Privileges Assigned to an Okta Group
- Administrator Role Assigned to an Okta User
- Adobe Hijack Persistence
- Adversary Behavior - Detected - Elastic Endgame
- Agent Spoofing - Mismatched Agent ID
- Agent Spoofing - Multiple Hosts Using Same Agent
- Anomalous Linux Compiler Activity
- Anomalous Process For a Linux Population
- Anomalous Process For a Windows Population
- Anomalous Windows Process Creation
- Apple Script Execution followed by Network Connection
- Apple Scripting Execution with Administrator Privileges
- Application Added to Google Workspace Domain
- Application Removed from Blocklist in Google Workspace
- Archive File with Unusual Extension
- At.exe Command Lateral Movement
- Attempt to Clear Kernel Ring Buffer
- Attempt to Create Okta API Token
- Attempt to Deactivate MFA for an Okta User Account
- Attempt to Deactivate an Okta Application
- Attempt to Deactivate an Okta Network Zone
- Attempt to Deactivate an Okta Policy
- Attempt to Deactivate an Okta Policy Rule
- Attempt to Delete an Okta Application
- Attempt to Delete an Okta Network Zone
- Attempt to Delete an Okta Policy
- Attempt to Delete an Okta Policy Rule
- Attempt to Disable Gatekeeper
- Attempt to Disable IPTables or Firewall
- Attempt to Disable Syslog Service
- Attempt to Enable the Root Account
- Attempt to Install Kali Linux via WSL
- Attempt to Install Root Certificate
- Attempt to Modify an Okta Application
- Attempt to Modify an Okta Network Zone
- Attempt to Modify an Okta Policy
- Attempt to Modify an Okta Policy Rule
- Attempt to Mount SMB Share via Command Line
- Attempt to Remove File Quarantine Attribute
- Attempt to Reset MFA Factors for an Okta User Account
- Attempt to Revoke Okta API Token
- Attempt to Unload Elastic Endpoint Security Kernel Extension
- Attempted Bypass of Okta MFA
- Attempted Private Key Access
- Attempts to Brute Force a Microsoft 365 User Account
- Attempts to Brute Force an Okta User Account
- Authorization Plugin Modification
- Azure AD Global Administrator Role Assigned
- Azure Active Directory High Risk Sign-in
- Azure Active Directory High Risk User Sign-in Heuristic
- Azure Active Directory PowerShell Sign-in
- Azure Alert Suppression Rule Created or Modified
- Azure Application Credential Modification
- Azure Automation Account Created
- Azure Automation Runbook Created or Modified
- Azure Automation Runbook Deleted
- Azure Automation Webhook Created
- Azure Blob Container Access Level Modification
- Azure Blob Permissions Modification
- Azure Command Execution on Virtual Machine
- Azure Conditional Access Policy Modified
- Azure Diagnostic Settings Deletion
- Azure Event Hub Authorization Rule Created or Updated
- Azure Event Hub Deletion
- Azure External Guest User Invitation
- Azure Firewall Policy Deletion
- Azure Frontdoor Web Application Firewall (WAF) Policy Deleted
- Azure Full Network Packet Capture Detected
- Azure Global Administrator Role Addition to PIM User
- Azure Key Vault Modified
- Azure Kubernetes Events Deleted
- Azure Kubernetes Pods Deleted
- Azure Kubernetes Rolebindings Created
- Azure Network Watcher Deletion
- Azure Privilege Identity Management Role Modified
- Azure Resource Group Deletion
- Azure Service Principal Addition
- Azure Service Principal Credentials Added
- Azure Storage Account Key Regenerated
- Azure Virtual Network Device Modified or Deleted
- BPF filter applied using TC
- Base16 or Base32 Encoding/Decoding Activity
- Bash Shell Profile Modification
- Binary Content Copy via Cmd.exe
- Binary Executed from Shared Memory Directory
- Bitsadmin Activity
- Browser Extension Install
- Bypass UAC via Event Viewer
- Bypass UAC via Sdclt
- Chkconfig Service Add
- Clearing Windows Console History
- Clearing Windows Event Logs
- Cobalt Strike Command and Control Beacon
- Code Signing Policy Modification Through Built-in tools
- Code Signing Policy Modification Through Registry
- Command Execution via SolarWinds Process
- Command Prompt Network Connection
- Command Shell Activity Started via RunDLL32
- Component Object Model Hijacking
- Compression DLL Loaded by Unusual Process
- Conhost Spawned By Suspicious Parent Process
- Connection to Commonly Abused Free SSL Certificate Providers
- Connection to Commonly Abused Web Services
- Connection to External Network via Telnet
- Connection to Internal Network via Telnet
- Container Management Utility Run Inside A Container
- Container Workload Protection
- Control Panel Process with Unusual Arguments
- Creation of Hidden Files and Directories via CommandLine
- Creation of Hidden Launch Agent or Daemon
- Creation of Hidden Login Item via Apple Script
- Creation of Hidden Shared Object File
- Creation of Kernel Module
- Creation of SettingContent-ms Files
- Creation of a Hidden Local User Account
- Creation or Modification of Domain Backup DPAPI private key
- Creation or Modification of Root Certificate
- Creation or Modification of a new GPO Scheduled Task or Service
- Credential Acquisition via Registry Hive Dumping
- Credential Dumping - Detected - Elastic Endgame
- Credential Dumping - Prevented - Elastic Endgame
- Credential Manipulation - Detected - Elastic Endgame
- Credential Manipulation - Prevented - Elastic Endgame
- Cron Job Created or Changed by Previously Unknown Process
- CyberArk Privileged Access Security Error
- CyberArk Privileged Access Security Recommended Monitor
- DNS Tunneling
- DNS-over-HTTPS Enabled via Registry
- Default Cobalt Strike Team Server Certificate
- Delayed Execution via Ping
- Delete Volume USN Journal with Fsutil
- Deleting Backup Catalogs with Wbadmin
- Deprecated - Potential Reverse Shell via Suspicious Parent Process
- Direct Outbound SMB Connection
- Disable Windows Event and Security Logs Using Built-in Tools
- Disable Windows Firewall Rules via Netsh
- Disabling User Account Control via Registry Modification
- Disabling Windows Defender Security Settings via PowerShell
- Discovery of Domain Groups
- Discovery of Internet Capabilities via Built-in Tools
- Domain Added to Google Workspace Trusted Domains
- Downloaded Shortcut Files
- Downloaded URL Files
- Dumping Account Hashes via Built-In Commands
- Dumping of Keychain Content via Security Command
- Dynamic Linker Copy
- ESXI Discovery via Find
- ESXI Discovery via Grep
- ESXI Timestomping using Touch Command
- EggShell Backdoor Execution
- Elastic Agent Service Terminated
- Emond Rules Creation or Modification
- Enable Host Network Discovery via Netsh
- Encoded Executable Stored in the Registry
- Encrypting Files with WinRar or 7z
- Endpoint Security
- Enumerating Domain Trusts via DSQUERY.EXE
- Enumerating Domain Trusts via NLTEST.EXE
- Enumeration Command Spawned via WMIPrvSE
- Enumeration of Administrator Accounts
- Enumeration of Kernel Modules
- Enumeration of Kernel Modules via Proc
- Enumeration of Privileged Local Groups Membership
- Enumeration of Users or Groups via Built-in Commands
- Exchange Mailbox Export via PowerShell
- Executable File Creation with Multiple Extensions
- Executable File with Unusual Extension
- Execution from Unusual Directory - Command Line
- Execution from a Removable Media with Network Connection
- Execution of COM object via Xwizard
- Execution of File Written or Modified by Microsoft Office
- Execution of File Written or Modified by PDF Reader
- Execution of Persistent Suspicious Program
- Execution of an Unsigned Service
- Execution via Electron Child Process Node.js Module
- Execution via MS VisualStudio Pre/Post Build Events
- Execution via MSSQL xp_cmdshell Stored Procedure
- Execution via Microsoft DotNet ClickOnce Host
- Execution via TSClient Mountpoint
- Execution via Windows Subsystem for Linux
- Execution via local SxS Shared Module
- Execution with Explicit Credentials via Scripting
- Expired or Revoked Driver Loaded
- Exploit - Detected - Elastic Endgame
- Exploit - Prevented - Elastic Endgame
- Exporting Exchange Mailbox via PowerShell
- External Alerts
- External IP Lookup from Non-Browser Process
- External User Added to Google Workspace Group
- File Compressed or Archived into Common Format
- File Creation Time Changed
- File Creation, Execution and Self-Deletion in Suspicious Directory
- File Deletion via Shred
- File Made Executable via Chmod Inside A Container
- File Permission Modification in Writable Directory
- File Staged in Root Folder of Recycle Bin
- File Transfer or Listener Established via Netcat
- File and Directory Permissions Modification
- File made Immutable by Chattr
- File or Directory Deletion Command
- File with Suspicious Extension Downloaded
- Finder Sync Plugin Registered and Enabled
- First Time Seen AWS Secret Value Accessed in Secrets Manager
- First Time Seen Commonly Abused Remote Access Tool Execution
- First Time Seen Driver Loaded
- First Time Seen Google Workspace OAuth Login from Third-Party Application
- First Time Seen NewCredentials Logon Process
- First Time Seen Removable Device
- FirstTime Seen Account Performing DCSync
- Forwarded Google Workspace Security Alert
- Full User-Mode Dumps Enabled System-Wide
- GCP Firewall Rule Creation
- GCP Firewall Rule Deletion
- GCP Firewall Rule Modification
- GCP IAM Custom Role Creation
- GCP IAM Role Deletion
- GCP IAM Service Account Key Deletion
- GCP Logging Bucket Deletion
- GCP Logging Sink Deletion
- GCP Logging Sink Modification
- GCP Pub/Sub Subscription Creation
- GCP Pub/Sub Subscription Deletion
- GCP Pub/Sub Topic Creation
- GCP Pub/Sub Topic Deletion
- GCP Service Account Creation
- GCP Service Account Deletion
- GCP Service Account Disabled
- GCP Service Account Key Creation
- GCP Storage Bucket Configuration Modification
- GCP Storage Bucket Deletion
- GCP Storage Bucket Permissions Modification
- GCP Virtual Private Cloud Network Deletion
- GCP Virtual Private Cloud Route Creation
- GCP Virtual Private Cloud Route Deletion
- GitHub Owner Role Granted To User
- GitHub Protected Branch Settings Changed
- GitHub Repository Deleted
- Google Drive Ownership Transferred via Google Workspace
- Google Workspace 2SV Policy Disabled
- Google Workspace API Access Granted via Domain-Wide Delegation of Authority
- Google Workspace Admin Role Assigned to a User
- Google Workspace Admin Role Deletion
- Google Workspace Bitlocker Setting Disabled
- Google Workspace Custom Admin Role Created
- Google Workspace Custom Gmail Route Created or Modified
- Google Workspace Drive Encryption Key(s) Accessed from Anonymous User
- Google Workspace MFA Enforcement Disabled
- Google Workspace Object Copied from External Drive and Access Granted to Custom Application
- Google Workspace Password Policy Modified
- Google Workspace Restrictions for Google Marketplace Modified to Allow Any App
- Google Workspace Role Modified
- Google Workspace Suspended User Account Renewed
- Google Workspace User Organizational Unit Changed
- Group Policy Abuse for Privilege Addition
- Group Policy Discovery via Microsoft GPResult Utility
- Halfbaked Command and Control Beacon
- Hidden Files and Directories via Hidden Flag
- High Number of Okta User Password Reset or Unlock Attempts
- High Number of Process Terminations
- High Number of Process and/or Service Terminations
- Host Files System Changes via Windows Subsystem for Linux
- Hosts File Modified
- Hping Process Activity
- IIS HTTP Logging Disabled
- IPSEC NAT Traversal Port Activity
- Image File Execution Options Injection
- Image Loaded with Invalid Signature
- ImageLoad via Windows Update Auto Update Client
- Inbound Connection to an Unsecure Elasticsearch Node
- Incoming DCOM Lateral Movement via MSHTA
- Incoming DCOM Lateral Movement with MMC
- Incoming DCOM Lateral Movement with ShellBrowserWindow or ShellWindows
- Incoming Execution via PowerShell Remoting
- Incoming Execution via WinRM Remote Shell
- Indirect Command Execution via Forfiles/Pcalua
- Ingress Transfer via Windows BITS
- InstallUtil Activity
- InstallUtil Process Making Network Connections
- Installation of Custom Shim Databases
- Installation of Security Support Provider
- Interactive Exec Command Launched Against A Running Container
- Interactive Terminal Spawned via Perl
- Interactive Terminal Spawned via Python
- KRBTGT Delegation Backdoor
- Kerberos Cached Credentials Dumping
- Kerberos Pre-authentication Disabled for User
- Kerberos Traffic from Unusual Process
- Kernel Driver Load
- Kernel Load or Unload via Kexec Detected
- Kernel Module Load via insmod
- Kernel Module Removal
- Keychain Password Retrieval via Command Line
- Kirbi File Creation
- Kubernetes Anonymous Request Authorized
- Kubernetes Container Created with Excessive Linux Capabilities
- Kubernetes Denied Service Account Request
- Kubernetes Exposed Service Created With Type NodePort
- Kubernetes Pod Created With HostIPC
- Kubernetes Pod Created With HostNetwork
- Kubernetes Pod Created With HostPID
- Kubernetes Pod created with a Sensitive hostPath Volume
- Kubernetes Privileged Pod Created
- Kubernetes Suspicious Assignment of Controller Service Account
- Kubernetes Suspicious Self-Subject Review
- Kubernetes User Exec into Pod
- LSASS Memory Dump Creation
- LSASS Memory Dump Handle Access
- LSASS Process Access via Windows API
- Lateral Movement via Startup Folder
- Launch Agent Creation or Modification and Immediate Loading
- LaunchDaemon Creation or Modification and Immediate Loading
- Linux Group Creation
- Linux Restricted Shell Breakout via Linux Binary(s)
- Linux Secret Dumping via GDB
- Linux System Information Discovery
- Linux User Account Creation
- Linux User Added to Privileged Group
- Linux init (PID 1) Secret Dump via GDB
- Local Account TokenFilter Policy Disabled
- Local Scheduled Task Creation
- MFA Disabled for Google Workspace Organization
- MS Office Macro Security Registry Modifications
- MacOS Installer Package Spawns Network Event
- Malware - Detected - Elastic Endgame
- Malware - Prevented - Elastic Endgame
- Masquerading Space After Filename
- Memory Dump File with Unusual Extension
- Microsoft 365 Exchange Anti-Phish Policy Deletion
- Microsoft 365 Exchange Anti-Phish Rule Modification
- Microsoft 365 Exchange DKIM Signing Configuration Disabled
- Microsoft 365 Exchange DLP Policy Removed
- Microsoft 365 Exchange Malware Filter Policy Deletion
- Microsoft 365 Exchange Malware Filter Rule Modification
- Microsoft 365 Exchange Management Group Role Assignment
- Microsoft 365 Exchange Safe Attachment Rule Disabled
- Microsoft 365 Exchange Safe Link Policy Disabled
- Microsoft 365 Exchange Transport Rule Creation
- Microsoft 365 Exchange Transport Rule Modification
- Microsoft 365 Global Administrator Role Assigned
- Microsoft 365 Impossible travel activity
- Microsoft 365 Inbox Forwarding Rule Created
- Microsoft 365 Mass download by a single user
- Microsoft 365 Potential ransomware activity
- Microsoft 365 Teams Custom Application Interaction Allowed
- Microsoft 365 Teams External Access Enabled
- Microsoft 365 Teams Guest Access Enabled
- Microsoft 365 Unusual Volume of File Deletion
- Microsoft 365 User Restricted from Sending Email
- Microsoft Build Engine Started an Unusual Process
- Microsoft Build Engine Started by a Script Process
- Microsoft Build Engine Started by a System Process
- Microsoft Build Engine Started by an Office Application
- Microsoft Build Engine Using an Alternate Name
- Microsoft Exchange Server UM Spawning Suspicious Processes
- Microsoft Exchange Server UM Writing Suspicious Files
- Microsoft Exchange Transport Agent Install Script
- Microsoft Exchange Worker Spawning Suspicious Processes
- Microsoft IIS Connection Strings Decryption
- Microsoft IIS Service Account Password Dumped
- Microsoft Windows Defender Tampering
- Mimikatz Memssp Log File Detected
- Modification of AmsiEnable Registry Key
- Modification of Boot Configuration
- Modification of Dynamic Linker Preload Shared Object
- Modification of Dynamic Linker Preload Shared Object Inside A Container
- Modification of Environment Variable via Launchctl
- Modification of OpenSSH Binaries
- Modification of Safari Settings via Defaults Command
- Modification of Standard Authentication Module or Configuration
- Modification of WDigest Security Provider
- Modification of the msPKIAccountCredentials
- Modification or Removal of an Okta Application Sign-On Policy
- Mofcomp Activity
- Mounting Hidden or WebDav Remote Shares
- MsBuild Making Network Connections
- MsBuild Network Connection Sequence
- MsXsl Making Network Connections
- Mshta Making Network Connections
- Multi-Factor Authentication Disabled for an Azure User
- Multiple Alerts Involving a User
- Multiple Alerts in Different ATT&CK Tactics on a Single Host
- Multiple Logon Failure Followed by Logon Success
- Multiple Logon Failure from the same Source Address
- Multiple Vault Web Credentials Read
- My First Rule
- NTDS or SAM Database File Copied
- Namespace Manipulation Using Unshare
- Netcat Listener Established Inside A Container
- Netcat Listener Established via rlwrap
- Netsh Helper DLL
- Network Activity Detected via Kworker
- Network Activity Detected via cat
- Network Connection via Certutil
- Network Connection via Compiled HTML File
- Network Connection via MsXsl
- Network Connection via Recently Compiled Executable
- Network Connection via Registration Utility
- Network Connection via Signed Binary
- Network Logon Provider Registry Modification
- Network Traffic to Rare Destination Country
- Network-Level Authentication (NLA) Disabled
- New ActiveSyncAllowedDeviceID Added via PowerShell
- New GitHub App Installed
- New GitHub Owner Added
- New Systemd Service Created by Previously Unknown Process
- New Systemd Timer Created
- New or Modified Federation Domain
- Nping Process Activity
- NullSessionPipe Registry Modification
- O365 Email Reported by User as Malware or Phish
- O365 Excessive Single Sign-On Logon Errors
- O365 Exchange Suspicious Mailbox Right Delegation
- O365 Mailbox Audit Logging Bypass
- Office Test Registry Persistence
- Okta Brute Force or Password Spraying Attack
- Okta FastPass Phishing Detection
- Okta ThreatInsight Threat Suspected Promotion
- Okta User Session Impersonation
- OneDrive Malware File Upload
- Outbound Scheduled Task Activity via PowerShell
- Parent Process PID Spoofing
- Peripheral Device Discovery
- Permission Theft - Detected - Elastic Endgame
- Permission Theft - Prevented - Elastic Endgame
- Persistence via BITS Job Notify Cmdline
- Persistence via DirectoryService Plugin Modification
- Persistence via Docker Shortcut Modification
- Persistence via Folder Action Script
- Persistence via Hidden Run Key Detected
- Persistence via KDE AutoStart Script or Desktop File Modification
- Persistence via Login or Logout Hook
- Persistence via Microsoft Office AddIns
- Persistence via Microsoft Outlook VBA
- Persistence via PowerShell profile
- Persistence via Scheduled Job Creation
- Persistence via TelemetryController Scheduled Task Hijack
- Persistence via Update Orchestrator Service Hijack
- Persistence via WMI Event Subscription
- Persistence via WMI Standard Registry Provider
- Persistent Scripts in the Startup Directory
- Port Forwarding Rule Addition
- Possible Consent Grant Attack via Azure-Registered Application
- Possible FIN7 DGA Command and Control Behavior
- Possible Okta DoS Attack
- Potential Abuse of Repeated MFA Push Notifications
- Potential Admin Group Account Addition
- Potential Antimalware Scan Interface Bypass via PowerShell
- Potential Application Shimming via Sdbinst
- Potential Code Execution via Postgresql
- Potential Command and Control via Internet Explorer
- Potential Cookies Theft via Browser Debugging
- Potential Credential Access via DCSync
- Potential Credential Access via DuplicateHandle in LSASS
- Potential Credential Access via LSASS Memory Dump
- Potential Credential Access via Memory Dump File Creation
- Potential Credential Access via Renamed COM+ Services DLL
- Potential Credential Access via Trusted Developer Utility
- Potential Credential Access via Windows Utilities
- Potential Cross Site Scripting (XSS)
- Potential DLL Side-Loading via Microsoft Antimalware Service Executable
- Potential DLL Side-Loading via Trusted Microsoft Programs
- Potential DNS Tunneling via NsLookup
- Potential Defense Evasion via CMSTP.exe
- Potential Defense Evasion via PRoot
- Potential Disabling of AppArmor
- Potential Disabling of SELinux
- Potential Evasion via Filter Manager
- Potential Exploitation of an Unquoted Service Path Vulnerability
- Potential External Linux SSH Brute Force Detected
- Potential File Transfer via Certreq
- Potential Hidden Local User Account Creation
- Potential Hidden Process via Mount Hidepid
- Potential Internal Linux SSH Brute Force Detected
- Potential Invoke-Mimikatz PowerShell Script
- Potential JAVA/JNDI Exploitation Attempt
- Potential Kerberos Attack via Bifrost
- Potential LSA Authentication Package Abuse
- Potential LSASS Clone Creation via PssCaptureSnapShot
- Potential LSASS Memory Dump via PssCaptureSnapShot
- Potential Lateral Tool Transfer via SMB Share
- Potential Linux Backdoor User Account Creation
- Potential Linux Credential Dumping via Proc Filesystem
- Potential Linux Credential Dumping via Unshadow
- Potential Linux Hack Tool Launched
- Potential Linux Local Account Brute Force Detected
- Potential Linux Ransomware Note Creation Detected
- Potential Linux SSH X11 Forwarding
- Potential Linux Tunneling and/or Port Forwarding
- Potential Local NTLM Relay via HTTP
- Potential Malicious File Downloaded from Google Drive
- Potential Masquerading as Browser Process
- Potential Masquerading as Business App Installer
- Potential Masquerading as Communication Apps
- Potential Masquerading as System32 DLL
- Potential Masquerading as System32 Executable
- Potential Masquerading as VLC DLL
- Potential Meterpreter Reverse Shell
- Potential Microsoft Office Sandbox Evasion
- Potential Modification of Accessibility Binaries
- Potential Network Scan Detected
- Potential Network Scan Executed From Host
- Potential Network Share Discovery
- Potential Network Sweep Detected
- Potential Non-Standard Port HTTP/HTTPS connection
- Potential Non-Standard Port SSH connection
- Potential OpenSSH Backdoor Logging Activity
- Potential Outgoing RDP Connection by Unusual Process
- Potential Pass-the-Hash (PtH) Attempt
- Potential Password Spraying of Microsoft 365 User Accounts
- Potential Persistence Through MOTD File Creation Detected
- Potential Persistence Through Run Control Detected
- Potential Persistence Through init.d Detected
- Potential Persistence via Atom Init Script Modification
- Potential Persistence via Login Hook
- Potential Persistence via Periodic Tasks
- Potential Persistence via Time Provider Modification
- Potential Port Monitor or Print Processor Registration Abuse
- Potential PowerShell HackTool Script by Function Names
- Potential Privacy Control Bypass via Localhost Secure Copy
- Potential Privacy Control Bypass via TCCDB Modification
- Potential Privilege Escalation through Writable Docker Socket
- Potential Privilege Escalation via CVE-2023-4911
- Potential Privilege Escalation via Container Misconfiguration
- Potential Privilege Escalation via InstallerFileTakeOver
- Potential Privilege Escalation via OverlayFS
- Potential Privilege Escalation via PKEXEC
- Potential Privilege Escalation via Python cap_setuid
- Potential Privilege Escalation via Recently Compiled Executable
- Potential Privilege Escalation via Sudoers File Modification
- Potential Privilege Escalation via UID INT_MAX Bug Detected
- Potential Privileged Escalation via SamAccountName Spoofing
- Potential Process Herpaderping Attempt
- Potential Process Injection from Malicious Document
- Potential Process Injection via PowerShell
- Potential Protocol Tunneling via Chisel Client
- Potential Protocol Tunneling via Chisel Server
- Potential Protocol Tunneling via EarthWorm
- Potential Pspy Process Monitoring Detected
- Potential Remote Code Execution via Web Server
- Potential Remote Credential Access via Registry
- Potential Remote Desktop Shadowing Activity
- Potential Remote Desktop Tunneling Detected
- Potential Remote File Execution via MSIEXEC
- Potential Reverse Shell
- Potential Reverse Shell Activity via Terminal
- Potential Reverse Shell via Background Process
- Potential Reverse Shell via Java
- Potential Reverse Shell via Suspicious Binary
- Potential Reverse Shell via Suspicious Child Process
- Potential Reverse Shell via UDP
- Potential SSH-IT SSH Worm Downloaded
- Potential SYN-Based Network Scan Detected
- Potential Secure File Deletion via SDelete Utility
- Potential Shadow Credentials added to AD Object
- Potential Shadow File Read via Command Line Utilities
- Potential SharpRDP Behavior
- Potential Shell via Wildcard Injection Detected
- Potential Successful Linux FTP Brute Force Attack Detected
- Potential Successful Linux RDP Brute Force Attack Detected
- Potential Successful SSH Brute Force Attack
- Potential Sudo Hijacking Detected
- Potential Sudo Privilege Escalation via CVE-2019-14287
- Potential Sudo Token Manipulation via Process Injection
- Potential Suspicious Clipboard Activity Detected
- Potential Suspicious DebugFS Root Device Access
- Potential Suspicious File Edit
- Potential Unauthorized Access via Wildcard Injection Detected
- Potential Upgrade of Non-interactive Shell
- Potential Windows Error Manager Masquerading
- Potential curl CVE-2023-38545 Exploitation
- Potential macOS SSH Brute Force Detected
- Potentially Suspicious Process Started via tmux or screen
- PowerShell Invoke-NinjaCopy script
- PowerShell Kerberos Ticket Dump
- PowerShell Kerberos Ticket Request
- PowerShell Keylogging Script
- PowerShell Mailbox Collection Script
- PowerShell MiniDump Script
- PowerShell PSReflect Script
- PowerShell Script Block Logging Disabled
- PowerShell Script with Archive Compression Capabilities
- PowerShell Script with Discovery Capabilities
- PowerShell Script with Encryption/Decryption Capabilities
- PowerShell Script with Log Clear Capabilities
- PowerShell Script with Password Policy Discovery Capabilities
- PowerShell Script with Remote Execution Capabilities via WinRM
- PowerShell Script with Token Impersonation Capabilities
- PowerShell Script with Webcam Video Capture Capabilities
- PowerShell Share Enumeration Script
- PowerShell Suspicious Discovery Related Windows API Functions
- PowerShell Suspicious Payload Encoded and Compressed
- PowerShell Suspicious Script with Audio Capture Capabilities
- PowerShell Suspicious Script with Clipboard Retrieval Capabilities
- PowerShell Suspicious Script with Screenshot Capabilities
- Privilege Escalation via Named Pipe Impersonation
- Privilege Escalation via Rogue Named Pipe Impersonation
- Privilege Escalation via Root Crontab File Modification
- Privilege Escalation via Windir Environment Variable
- Privileged Account Brute Force
- Privileges Elevation via Parent Process PID Spoofing
- Process Activity via Compiled HTML File
- Process Created with an Elevated Token
- Process Creation via Secondary Logon
- Process Discovery Using Built-in Tools
- Process Discovery via Built-In Applications
- Process Execution from an Unusual Directory
- Process Injection - Detected - Elastic Endgame
- Process Injection - Prevented - Elastic Endgame
- Process Injection by the Microsoft Build Engine
- Process Started from Process ID (PID) File
- Process Termination followed by Deletion
- Processes with Trailing Spaces
- Program Files Directory Masquerading
- Prompt for Credentials with OSASCRIPT
- ProxyChains Activity
- PsExec Network Connection
- Python Script Execution via Command Line
- Query Registry using Built-in Tools
- RDP (Remote Desktop Protocol) from the Internet
- RDP Enabled via Registry
- RPC (Remote Procedure Call) from the Internet
- RPC (Remote Procedure Call) to the Internet
- Ransomware - Detected - Elastic Endgame
- Ransomware - Prevented - Elastic Endgame
- Rare AWS Error Code
- Rare User Logon
- Registry Persistence via AppCert DLL
- Registry Persistence via AppInit DLL
- Remote Computer Account DnsHostName Update
- Remote Desktop Enabled in Windows Firewall by Netsh
- Remote Execution via File Shares
- Remote File Copy to a Hidden Share
- Remote File Copy via TeamViewer
- Remote File Download via Desktopimgdownldr Utility
- Remote File Download via MpCmdRun
- Remote File Download via PowerShell
- Remote File Download via Script Interpreter
- Remote Logon followed by Scheduled Task Creation
- Remote SSH Login Enabled via systemsetup Command
- Remote Scheduled Task Creation
- Remote System Discovery Commands
- Remote Windows Service Installed
- Remote XSL Script Execution via COM
- Remotely Started Services via RPC
- Renamed AutoIt Scripts Interpreter
- Renamed Utility Executed with Short Program Name
- Roshal Archive (RAR) or PowerShell File Downloaded from the Internet
- SIP Provider Modification
- SMB (Windows File Sharing) Activity to the Internet
- SMTP on Port 26/TCP
- SSH Authorized Keys File Modification
- SSH Authorized Keys File Modified Inside a Container
- SSH Connection Established Inside A Running Container
- SSH Process Launched From Inside A Container
- SUID/SGUID Enumeration Detected
- SUNBURST Command and Control Activity
- Scheduled Task Created by a Windows Script
- Scheduled Task Execution at Scale via GPO
- Scheduled Tasks AT Command Enabled
- Screensaver Plist File Modified by Unexpected Process
- SeDebugPrivilege Enabled by a Suspicious Process
- Searching for Saved Credentials via VaultCmd
- Security Software Discovery using WMIC
- Security Software Discovery via Grep
- Segfault Detected
- Sensitive Files Compression
- Sensitive Files Compression Inside A Container
- Sensitive Keys Or Passwords Searched For Inside A Container
- Sensitive Privilege SeEnableDelegationPrivilege assigned to a User
- Service Command Lateral Movement
- Service Control Spawned via Script Interpreter
- Service Creation via Local Kerberos Authentication
- Service Disabled via Registry Modification
- Service Path Modification
- Service Path Modification via sc.exe
- Setcap setuid/setgid Capability Set
- Setuid / Setgid Bit Set via chmod
- SharePoint Malware File Upload
- Shared Object Created or Changed by Previously Unknown Process
- Shell Execution via Apple Scripting
- Shortcut File Written or Modified on Startup Folder
- Signed Proxy Execution via MS Work Folders
- SoftwareUpdate Preferences Modification
- SolarWinds Process Disabling Services via Registry
- Spike in AWS Error Messages
- Spike in Failed Logon Events
- Spike in Firewall Denies
- Spike in Logon Events
- Spike in Network Traffic
- Spike in Network Traffic To a Country
- Spike in Successful Logon Events from a Source IP
- Startup Folder Persistence via Unsigned Process
- Startup Persistence by a Suspicious Process
- Startup or Run Key Registry Modification
- Startup/Logon Script added to Group Policy Object
- Sublime Plugin or Application Script Modification
- Sudo Command Enumeration Detected
- Sudo Heap-Based Buffer Overflow Attempt
- Sudoers File Modification
- Suspicious .NET Code Compilation
- Suspicious .NET Reflection via PowerShell
- Suspicious Activity Reported by Okta User
- Suspicious Antimalware Scan Interface DLL
- Suspicious Automator Workflows Execution
- Suspicious Browser Child Process
- Suspicious Calendar File Modification
- Suspicious CertUtil Commands
- Suspicious Child Process of Adobe Acrobat Reader Update Service
- Suspicious Cmd Execution via WMI
- Suspicious Communication App Child Process
- Suspicious Content Extracted or Decompressed via Funzip
- Suspicious CronTab Creation or Modification
- Suspicious DLL Loaded for Persistence or Privilege Escalation
- Suspicious Data Encryption via OpenSSL Utility
- Suspicious Emond Child Process
- Suspicious Endpoint Security Parent Process
- Suspicious Execution from a Mounted Device
- Suspicious Execution via MSIEXEC
- Suspicious Execution via Microsoft Office Add-Ins
- Suspicious Execution via Scheduled Task
- Suspicious Execution via Windows Subsystem for Linux
- Suspicious Explorer Child Process
- Suspicious File Changes Activity Detected
- Suspicious File Creation in /etc for Persistence
- Suspicious HTML File Creation
- Suspicious Hidden Child Process of Launchd
- Suspicious Image Load (taskschd.dll) from MS Office
- Suspicious ImagePath Service Creation
- Suspicious Inter-Process Communication via Outlook
- Suspicious Interactive Shell Spawned From Inside A Container
- Suspicious JAVA Child Process
- Suspicious LSASS Access via MalSecLogon
- Suspicious Lsass Process Access
- Suspicious MS Office Child Process
- Suspicious MS Outlook Child Process
- Suspicious Managed Code Hosting Process
- Suspicious Microsoft 365 Mail Access by ClientAppId
- Suspicious Microsoft Diagnostics Wizard Execution
- Suspicious Mining Process Creation Event
- Suspicious Modprobe File Event
- Suspicious Module Loaded by LSASS
- Suspicious Network Activity to the Internet by Previously Unknown Executable
- Suspicious Network Tool Launched Inside A Container
- Suspicious PDF Reader Child Process
- Suspicious Portable Executable Encoded in Powershell Script
- Suspicious PowerShell Engine ImageLoad
- Suspicious Powershell Script
- Suspicious Print Spooler File Deletion
- Suspicious Print Spooler Point and Print DLL
- Suspicious Print Spooler SPL File Created
- Suspicious PrintSpooler Service Executable File Creation
- Suspicious Proc Pseudo File System Enumeration
- Suspicious Process Access via Direct System Call
- Suspicious Process Creation CallTrace
- Suspicious Process Execution via Renamed PsExec Executable
- Suspicious Process Spawned from MOTD Detected
- Suspicious RDP ActiveX Client Loaded
- Suspicious Remote Registry Access via SeBackupPrivilege
- Suspicious Renaming of ESXI Files
- Suspicious Renaming of ESXI index.html File
- Suspicious Script Object Execution
- Suspicious Service was Installed in the System
- Suspicious SolarWinds Child Process
- Suspicious Startup Shell Folder Modification
- Suspicious Symbolic Link Created
- Suspicious Sysctl File Event
- Suspicious System Commands Executed by Previously Unknown Executable
- Suspicious Termination of ESXI Process
- Suspicious Troubleshooting Pack Cabinet Execution
- Suspicious Utility Launched via ProxyChains
- Suspicious WMI Event Subscription Created
- Suspicious WMI Image Load from MS Office
- Suspicious WMIC XSL Script Execution
- Suspicious WerFault Child Process
- Suspicious Zoom Child Process
- Suspicious macOS MS Office Child Process
- Suspicious which Enumeration
- Svchost spawning Cmd
- Symbolic Link to Shadow Copy Created
- System Binary Copied and/or Moved to Suspicious Directory
- System Hosts File Access
- System Information Discovery via Windows Command Shell
- System Log File Deletion
- System Network Connections Discovery
- System Owner/User Discovery Linux
- System Service Discovery through built-in Windows Utilities
- System Shells via Services
- System Time Discovery
- SystemKey Access via Command Line
- TCC Bypass via Mounted APFS Snapshot Access
- Tainted Kernel Module Load
- Tampering of Bash Command-Line History
- Temporarily Scheduled Task Creation
- Third-party Backup Files Deleted via Unexpected Process
- Threat Intel Hash Indicator Match
- Threat Intel IP Address Indicator Match
- Threat Intel URL Indicator Match
- Threat Intel Windows Registry Indicator Match
- Timestomping using Touch Command
- Trap Signals Execution
- UAC Bypass Attempt via Elevated COM Internet Explorer Add-On Installer
- UAC Bypass Attempt via Privileged IFileOperation COM Interface
- UAC Bypass Attempt via Windows Directory Masquerading
- UAC Bypass Attempt with IEditionUpgradeManager Elevated COM Interface
- UAC Bypass via DiskCleanup Scheduled Task Hijack
- UAC Bypass via ICMLuaUtil Elevated COM Interface
- UAC Bypass via Windows Firewall Snap-In Hijack
- Unauthorized Access to an Okta Application
- Uncommon Registry Persistence Change
- Unexpected Child Process of macOS Screensaver Engine
- Unix Socket Connection
- Unsigned BITS Service Client Process
- Unsigned DLL Loaded by Svchost
- Unsigned DLL Loaded by a Trusted Process
- Unsigned DLL Side-Loading from a Suspicious Folder
- Untrusted Driver Loaded
- Unusual AWS Command for a User
- Unusual Child Process from a System Virtual Process
- Unusual Child Process of dns.exe
- Unusual Child Processes of RunDLL32
- Unusual City For an AWS Command
- Unusual Country For an AWS Command
- Unusual DNS Activity
- Unusual Discovery Activity by User
- Unusual Discovery Signal Alert with Unusual Process Command Line
- Unusual Discovery Signal Alert with Unusual Process Executable
- Unusual Executable File Creation by a System Critical Process
- Unusual File Creation - Alternate Data Stream
- Unusual File Modification by dns.exe
- Unusual Hour for a User to Logon
- Unusual Linux Network Activity
- Unusual Linux Network Configuration Discovery
- Unusual Linux Network Connection Discovery
- Unusual Linux Network Port Activity
- Unusual Linux Process Calling the Metadata Service
- Unusual Linux Process Discovery Activity
- Unusual Linux System Information Discovery Activity
- Unusual Linux User Calling the Metadata Service
- Unusual Linux User Discovery Activity
- Unusual Linux Username
- Unusual Login Activity
- Unusual Network Activity from a Windows System Binary
- Unusual Network Connection via DllHost
- Unusual Network Connection via RunDLL32
- Unusual Network Destination Domain Name
- Unusual Parent Process for cmd.exe
- Unusual Parent-Child Relationship
- Unusual Persistence via Services Registry
- Unusual Print Spooler Child Process
- Unusual Process Execution Path - Alternate Data Stream
- Unusual Process Execution on WBEM Path
- Unusual Process Extension
- Unusual Process For MSSQL Service Accounts
- Unusual Process For a Linux Host
- Unusual Process For a Windows Host
- Unusual Process Network Connection
- Unusual Service Host Child Process - Childless Service
- Unusual Source IP for a User to Logon from
- Unusual Sudo Activity
- Unusual User Privilege Enumeration via id
- Unusual Web Request
- Unusual Web User Agent
- Unusual Windows Network Activity
- Unusual Windows Path Activity
- Unusual Windows Process Calling the Metadata Service
- Unusual Windows Remote User
- Unusual Windows Service
- Unusual Windows User Calling the Metadata Service
- Unusual Windows User Privilege Elevation Activity
- Unusual Windows Username
- User Account Creation
- User Added as Owner for Azure Application
- User Added as Owner for Azure Service Principal
- User Added to Privileged Group
- User account exposed to Kerberoasting
- VNC (Virtual Network Computing) from the Internet
- VNC (Virtual Network Computing) to the Internet
- Virtual Machine Fingerprinting
- Virtual Machine Fingerprinting via Grep
- Virtual Private Network Connection Attempt
- Volume Shadow Copy Deleted or Resized via VssAdmin
- Volume Shadow Copy Deletion via PowerShell
- Volume Shadow Copy Deletion via WMIC
- WMI Incoming Lateral Movement
- WMI WBEMTEST Utility Execution
- WMIC Remote Command
- WPAD Service Exploit
- WRITEDAC Access on Active Directory Object
- Web Application Suspicious Activity: POST Request Declined
- Web Application Suspicious Activity: Unauthorized Method
- Web Application Suspicious Activity: sqlmap User Agent
- Web Shell Detection: Script Process Child of Common Web Processes
- WebProxy Settings Modification
- WebServer Access Logs Deleted
- Werfault ReflectDebugger Persistence
- Whoami Process Activity
- Windows Account or Group Discovery
- Windows CryptoAPI Spoofing Vulnerability (CVE-2020-0601 - CurveBall)
- Windows Defender Disabled via Registry Modification
- Windows Defender Exclusions Added via PowerShell
- Windows Event Logs Cleared
- Windows Firewall Disabled via PowerShell
- Windows Installer with Suspicious Properties
- Windows Network Enumeration
- Windows Registry File Creation in SMB Share
- Windows Script Executing PowerShell
- Windows Script Interpreter Executing Process via WMI
- Windows Service Installed via an Unusual Client
- Windows Subsystem for Linux Distribution Installed
- Windows Subsystem for Linux Enabled via Dism Utility
- Windows System Information Discovery
- Windows System Network Connections Discovery
- Windows User Account Creation
- Wireless Credential Dumping using Netsh Command
- Zoom Meeting with no Passcode
- Downloadable rule updates
- Update v0.13.1
- Update v0.13.2
- Update v0.13.3
- Update v0.14.1
- Update v0.14.2
- Update v0.14.3
- Update v1.0.2
- Update v8.1.1
- Update v8.2.1
- Update v8.3.1
- Update v8.3.2
- Update v8.3.3
- Update v8.3.4
- Update v8.4.1
- Update v8.4.2
- Update v8.4.3
- Update v8.5.1
- Update v8.6.1
- Update v8.7.1
- Update v8.8.1
- Update v8.8.2
- Update v8.8.3
- Update v8.8.4
- Update v8.8.5
- Update v8.8.6
- Update v8.8.7
- Update v8.8.8
- Update v8.8.9
- Update v8.8.10
- Update v8.8.11
- Update v8.8.12
- Update v8.8.13
- Update v8.8.14
- Update v8.8.15
- Cloud native security
- Investigate
- Osquery
- Endpoint management
- Elastic Security APIs
- Detections API
- Exceptions API
- Create exception container
- Create exceptions used by multiple rules
- Create shared exception list
- Find exception containers
- Find exception items
- Get exception container
- Get exception item
- Import exception list
- Export exception list
- Update exception container
- Summary exception container
- Update exception item
- Delete exception container
- Delete exception item
- Lists index endpoint
- Lists API
- Detection Alerts Migration API
- Timeline API
- Get Timelines or Timeline templates
- Get Timeline / Timeline template by savedObjectId
- Get Timeline template by templateTimelineId
- Create Timeline or Timeline template
- Update Timeline or Timeline template
- Add a note to an existing Timeline
- Pin an event to an existing Timeline
- Delete Timelines or Timeline templates
- Import timelines and timeline templates
- Cases API
- Actions API (for pushing cases to external systems)
- Endpoint management API
- Elastic Security fields and object schemas
- Troubleshooting
- Technical preview
- Release notes
Detection rules
editDetection rules
editThis topic covers common troubleshooting issues when creating or managing detection rules.
Machine learning rules
editMachine learning rule is failing and a required machine learning job is stopped
If a machine learning rule is failing, check to make sure the required machine learning jobs are running and start any jobs that have stopped.
-
Go to Manage → Rules, then select the machine learning rule. The required machine learning jobs and their statuses are listed in the Definition section.
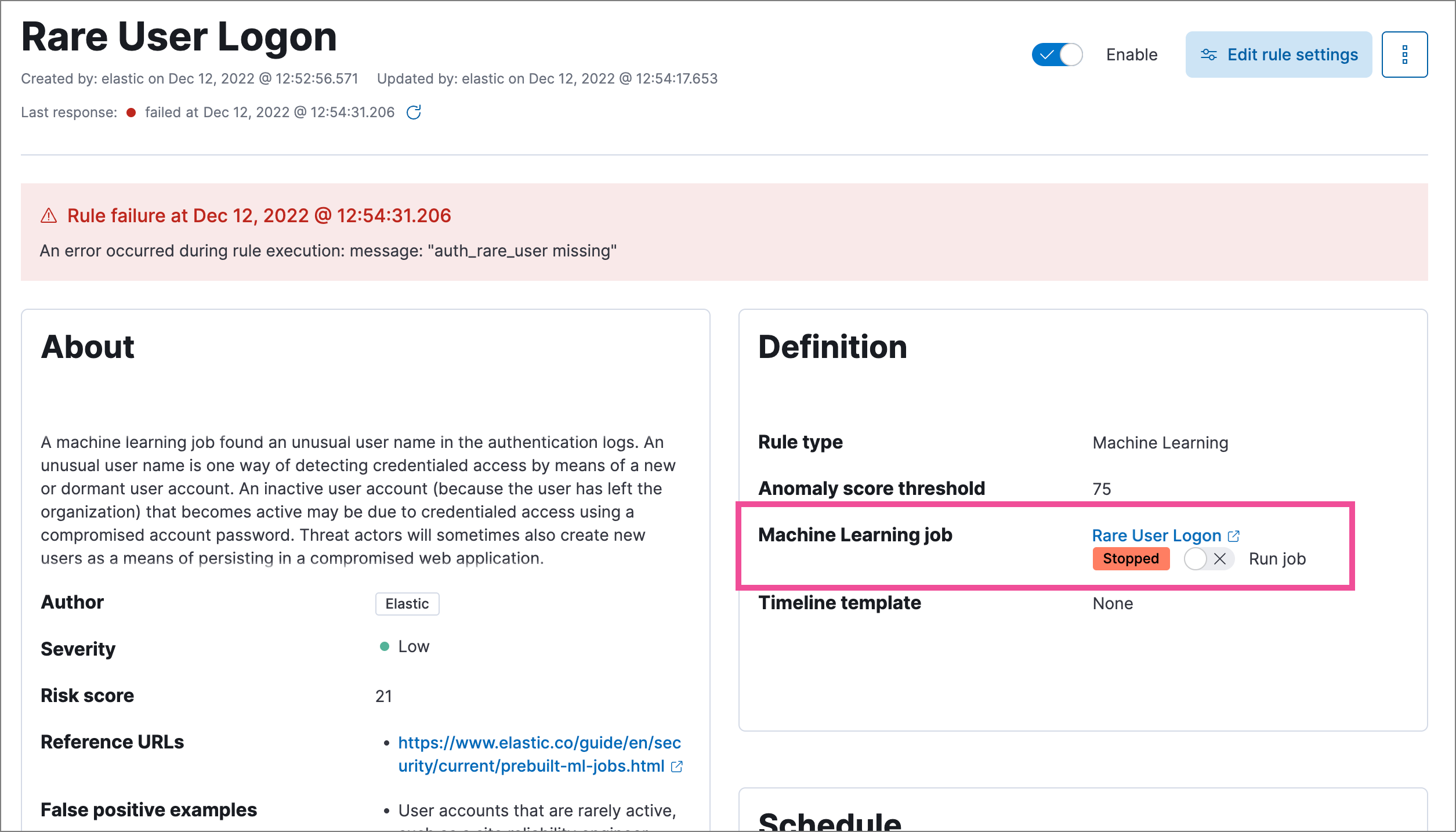
- If a required machine learning job isn’t running, turn on the Run job toggle next to it.
- Rerun the machine learning detection rule.
Indicator match rules
editRules are failing due to number of alerts
If you receive the following rule failure: "Bulk Indexing of signals failed: [parent] Data too large", this indicates that the alerts payload was too large to process.
This can be caused by bad indicator data, a misconfigured rule, or too many event matches. Review your indicator data or rule query. If nothing obvious is misconfigured, try executing the rule against a subset of the original data and continue diagnosis.
Indicator match rules are timing out
If you receive the following rule failure: "An error occurred during rule execution: message: "Request Timeout after 90000ms", this indicates that the query phase is timing out. Try refining the time frame or dividing the data defined in the query into multiple rules.
Indicator match rules are failing because the maxClauseCount limit is too low
If you receive the following rule failure: Bulk Indexing of signals failed: index: ".index-name" reason: "maxClauseCount is set to 1024" type: "too_many_clauses", this indicates that the limit for the total number of clauses that a query tree can have is too low. To update your maximum clause count, increase the size of your Elasticsearch JVM heap memory. 1 GB of Elasticsearch JVM heap size or more is sufficient.
General slowness
If you notice rule delays, review the suggestions above to troubleshoot, and also consider limiting the number of rules that run simultaneously, as this can cause noticeable performance implications in Kibana.
Rule exceptions
editNo autocomplete suggestions
When you’re creating detection rule exceptions, autocomplete might not provide suggestions in the Value field if the values don’t exist in the current page’s time range.
You can resolve this by expanding the time range, or by configuring Kibana’s autocomplete feature to get suggestions from your full data set instead. Go to Kibana → Stack Management → Advanced Settings, then turn off autocomplete:useTimeRange.
Turning off autocomplete:useTimeRange could cause performance issues if the data set is especially large.
Warning about type conflicts and unmapped fields
A warning icon (![]() ) and message appear for fields with type conflicts across multiple indices or are unmapped fields. You can learn more about the conflict by hovering over the field. After you select it, the warning message appears beneath the field.
) and message appear for fields with type conflicts across multiple indices or are unmapped fields. You can learn more about the conflict by hovering over the field. After you select it, the warning message appears beneath the field.
A field can have type conflicts and be unmapped in specified indices.
Fields with conflicting types
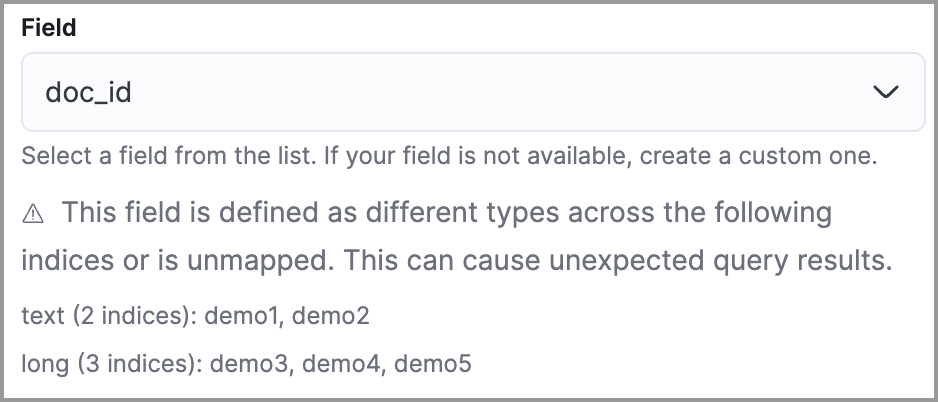
editType conflicts occur when a field is mapped to different types across multiple indices. To resolve this issue, you can create new indices with matching field type mappings and reindex your data. Otherwise, use the information about a field’s type mappings to ensure you’re entering compatible field values when defining exception conditions.
In the following example, the selected field has been defined as different types across five indices.
Unmapped fields
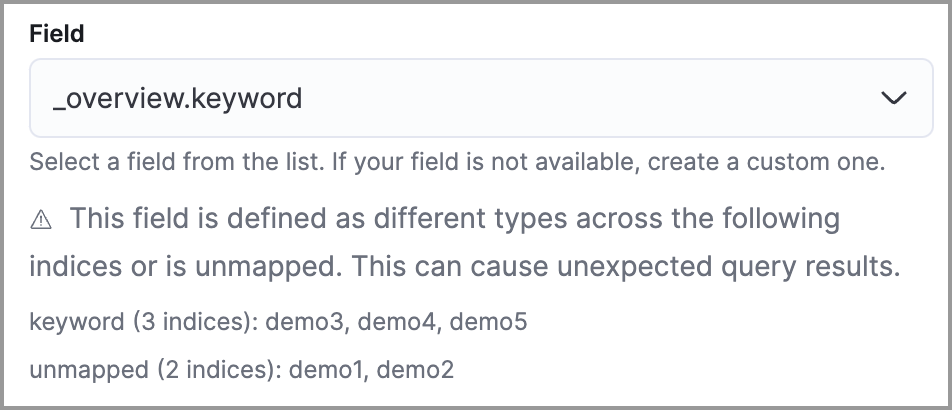
editUnmapped fields are undefined within an index’s mapping definition. Using unmapped fields to define an exception can prevent it from working as expected, and lead to false positives or unexpected alerts. To fix unmapped fields, add them to your indices' mapping definitions.
In the following example, the selected field is unmapped across two indices.
On this page