テキスト分類とは?
テキスト分類の定義
テキスト分類は機械学習の一種であり、テキストドキュメントや文章を規定のクラスまたはカテゴリーに分類します。テキストの内容と意味を分析してから、テキストラベル処理を利用して最も適切なラベルを適用します。
テキスト分類の実際の活用例としては、センチメント分析(レビューに込められたポジティブあるいはネガティブな感情を特定する)、スパム検出(例:迷惑メール検出)、トピック分類(例:関連するトピックでニュース記事をまとめる)などが挙げられます。テキスト分類を使うと、大量の非構造化テキストをコンピューターで理解および整理できるため、自然言語処理(NLP)では特に重要です。これにより、コンテンツフィルタリング、レコメンデーションシステム、顧客フィードバック分析などの作業を行いやすくなります。
テキスト分類の種類
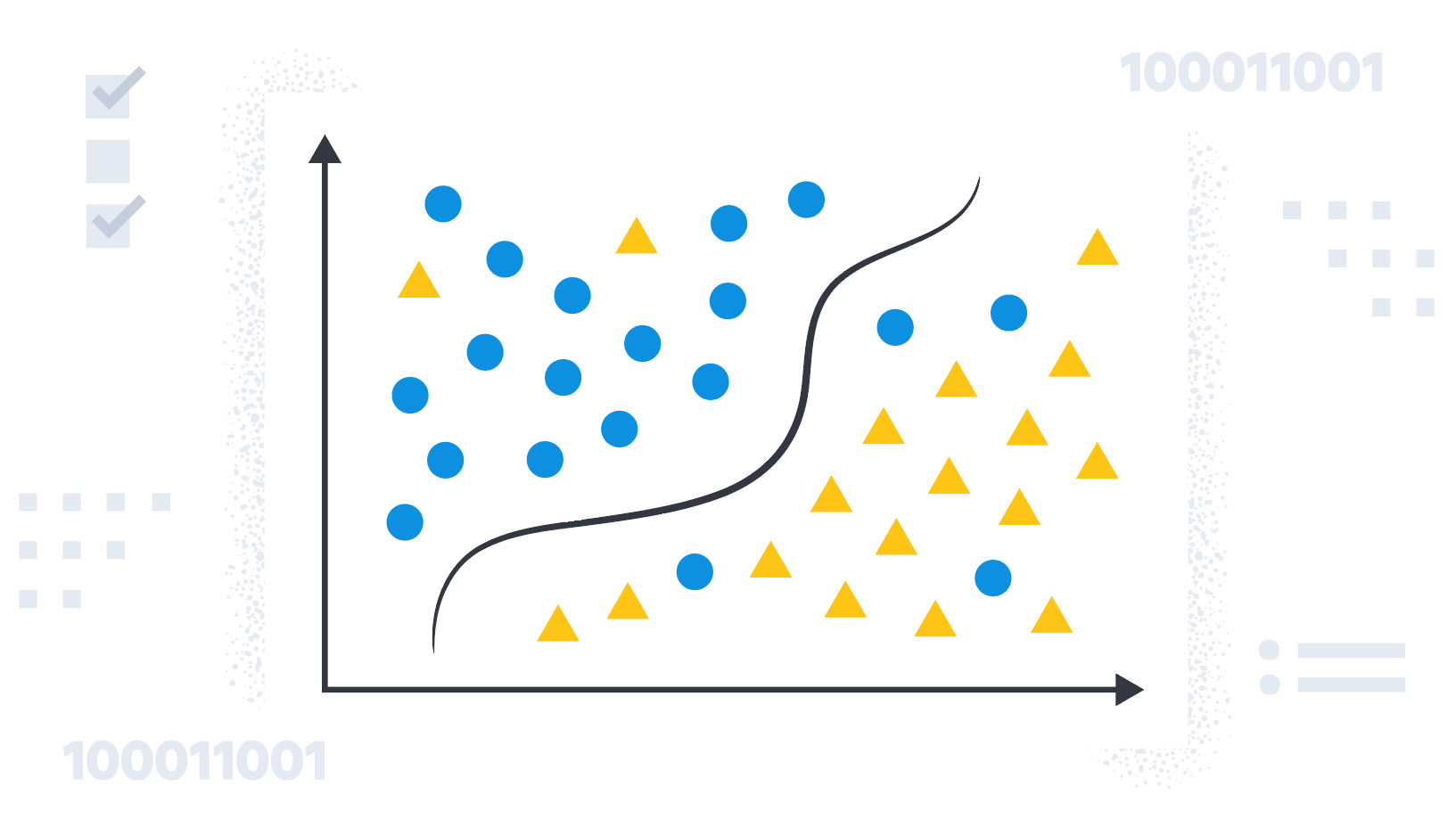
一般に目にする可能性があるテキスト分類の種類としては、以下のものがあります。
テキストセンチメント分析:テキストに込められているセンチメント(感情)を特定します。一般には、ポジティブ、ネガティブ、中立のいずれかに分類します。製品レビュー、ソーシャルメディアの投稿、顧客フィードバックの分析に使用されます。
有害性検出:テキストセンチメント分析に似ており、オンラインで使われる不快な言葉や有害な言葉を特定します。オンラインコミュニティのモデレーターが、オンラインでの議論やコメント、ソーシャルメディアの投稿などのデジタル環境において思いやりを確保するのに役立ちます。
意図認識:テキストセンチメント分析の一種であり、ユーザーにより入力されたテキストに込められている目的(または意図)を理解するために使用されます。多くのチャットボットやバーチャルアシスタントは、意図認識を使用してユーザーのクエリに応答しています。
二項分類:テキストを2つのクラスまたはカテゴリーのいずれかに分類します。よくある活用例としては、スパム検出が挙げられます。スパム検出では、メールやメッセージなどのテキストをスパムカテゴリーと正規カテゴリーのいずれかに分類し、有害と思われる一方的に送りつけられたコンテンツを自動的に除去します。
多項分類:テキストを3つ以上のクラスまたはカテゴリーのいずれかに分類します。ニュース記事、ブログ投稿、研究論文などのコンテンツの情報を整理、取得しやすくなります。
トピック分類:多項分類に似ており、ドキュメントや記事を規定のトピックまたはテーマでグループ分けします。たとえば、ニュース記事を政治、スポーツ、エンターテインメントなどのトピックに分類できます。
言語識別:テキストに使われている言語を特定します。複数の言語が使われる状況や、文字ベースのアプリケーションに役立ちます。
固有表現抽出:人名、組織名、場所の名前、日付など、テキスト内に登場する固有表現を識別、分類することに特化しています。
質問分類:予想される回答の種類に応じて質問を分類します。検索エンジンや質問応答システムに有用です。
テキスト分類のプロセス
テキスト分類のプロセスは、データ収集からモデルのデプロイまで、複数の手順に分かれています。以下に、各手順の概要を簡単に示します。
手順1:データ収集
テキストラベル処理用に、対応カテゴリーが設定されたテキストドキュメントを収集します。
手順2:データの前処理
不要な記号の削除、小文字への変換、句読点などの特殊記号の処理を行い、テキストデータを整理し準備します。
手順3:トークン化
テキストをトークン(単語などの小さなまとまり)に分割します。トークン化することで、各部分が検索可能になり、一致やつながりを見つけやすくなります。ベクトル検索や、ユーザーの意図に応じた結果を返すセマンティック検索では、この手順が特に効果的です。
手順4:特徴量抽出
機械学習モデルで理解できる数値表現にテキストを変換します。一般的には、単語の登場頻度の計測する手法(Bag-of-Wordsとも呼ばれます)や、単語埋め込みにより単語の意味を記録する手法が使われます。
手順5:モデルトレーニング
整理と前処理が完了したデータを使って、機械学習モデルをトレーニングします。モデルに、テキストの特徴量とカテゴリーとの間にあるパターンや関係を学習させます。ラベル処理済みのサンプルを使用すると、テキストのラベル付けの規則をモデルに把握させられます。
手順6:テキストラベル処理
新しいデータセットを別途作成し、新しいテキストのラベル付けと分類を行います。このテキストラベル処理では、モデルに、データ収集の手順で得た規定のカテゴリーにテキストを分類させます。
手順7:モデル評価
トレーニングが完了したモデルについて、テキストラベル処理のパフォーマンスを詳細に調べ、初見のテキストをうまく分類できるか確認します。
手順8:ハイパーパラメーターの調整
モデル評価の結果に応じて、モデルの設定を調整しパフォーマンスを最適化します。
手順9:モデルのデプロイ
トレーニングと調整が完了したモデルを使用して、新規のテキストデータを適切なカテゴリーに分類します。
テキスト分類が重要である理由
テキスト分類が重要である理由は、コンピューターで大量のテキストデータを自動的に分類、理解できるようになることです。デジタル世界では、ひっきりなしに大量の文字情報を目にすることになります。たとえば、メールやソーシャルメディア、レビューなどです。テキスト分類を使用すると、これらの構造化されていないデータについて機械でテキストラベル処理を行い、意味のあるグループにまとめることができます。テキスト分類により、理解しにくいコンテンツを理解し、効率の向上、意思決定の促進、ユーザーエクスペリエンスの強化を実現できます。
テキスト分類のユースケース
テキスト分類は、専門性の高いさまざまな環境で利用されています。以下に、一般に目にする可能性のある実際のユースケースをいくつか示します。
- カスタマーサポートのチケットを自動で分類し、優先順位を設定して、解決に適したチームに振り分ける。
- 顧客のフィードバック、調査の回答、オンラインでの議論を分析し、市場のトレンドや顧客の好みを特定する。
- ソーシャルメディアでのメンションやオンラインレビューを追跡して、ブランドに対して抱かれている評価や心情を監視する。
- テキストラベルまたはタグを用いてWebサイトやeコマースプラットフォームのコンテンツを整理、タグ付けし、コンテンツを見つけやすくして、顧客のユーザーエクスペリエンスを高める。
- ソーシャルメディアなどのオンラインソースで、特定のキーワードや基準に基づいて営業の見込み客を特定する。
- 競合他社に対するレビューやフィードバックを分析して、その長所や短所を把握する。
- テキストラベルを使用し顧客をやり取りやフィードバックに基づいてセグメント分けし、各セグメントに合わせてマーケティング戦略やキャンペーンを作成する。
- テキストラベルのパターンと異常値に基づいて、財務システム内の不正なアクティビティや取引を検出する(異常検知)。
テキスト分類の手法とアルゴリズム
テキスト分類の手法とアルゴリズムには、以下のものがあります。
- Bag-of-Words(BoW):単語の順序は考慮せずに登場回数を計測するシンプルな手法です。
- 単語埋め込み:単語を数値表現に変換し多次元空間上にプロットするさまざまな手法により、単語間に存在する複雑な関係を明らかにします。
- 決定木:機械学習のアルゴリズムであり、決定ノードと葉から成る木のような構造を作成します。各ノードで単語の出現をテストし、木全体でテキストデータに潜むパターンを学習できます。
- ランダムフォレスト:複数の決定木を組み合わせて、テキスト分類の精度を高める手法です。
- BERT(Bidirectional Encoder Representations from Transformers):高度な変換器ベースの分類モデルであり、単語の文脈を把握できます。
- 単純ベイズ:あるドキュメントについて、そのドキュメント内の単語の登場頻度に基づいて特定のクラスに属する確率を計算します。それぞれの単語が各クラスに登場する確率を見積もり、ベイズ理論(確率論の基礎定理)に従ってこれらの確率を組み合わせ、予測を行います。
- SVM(サポートベクターマシン):二項分類と多項分類に使われる機械学習アルゴリズムです。高次の特徴量空間において、各クラスのデータポイントを最も適切に分離できる超平面を特定します。これにより、新しい初見のテキストデータについて正確な予測を行えます。
- TF-IDF(単語頻度・逆文書頻度):ドキュメントに登場する単語の重要度を、データセット全体と比較して測定する手法です。
テキスト分類の評価メトリック
テキスト分類の評価メトリックは、モデルのさまざまなパフォーマンスを測定するために使用されます。一般的な評価メトリックには以下のものがあります。
正解率
サンプル全体のうち、適切に分類できたサンプルの割合です。モデルの全般的な正確性を測定できます。
精度
陽性と予測されたすべてのサンプルに対する、正しく陽性と予測できたサンプルの割合です。陽性予測について、その予測が実際に正しかった数がわかります。
再現率(感度)
実際に陽性であるすべてのサンプルに対する、正しく陽性と予測できたサンプルの割合です。モデルでどれだけ適切に陽性を特定できるかを示します。
F1スコア
精度と再現率を組み合わせた組み合わせた調和値であり、不均衡なクラスに対するモデルの全般的なパフォーマンスを評価できます。
受信者動作特性曲線下面積(AUC-ROC)
モデルの各クラスを区別する性能をグラフで表したものです。特に二項分類で役立ちます。
混同行列
真陽性、真陰性、偽陽性、偽陰性の数をまとめた表です。モデルのパフォーマンスを詳しく知ることができます。
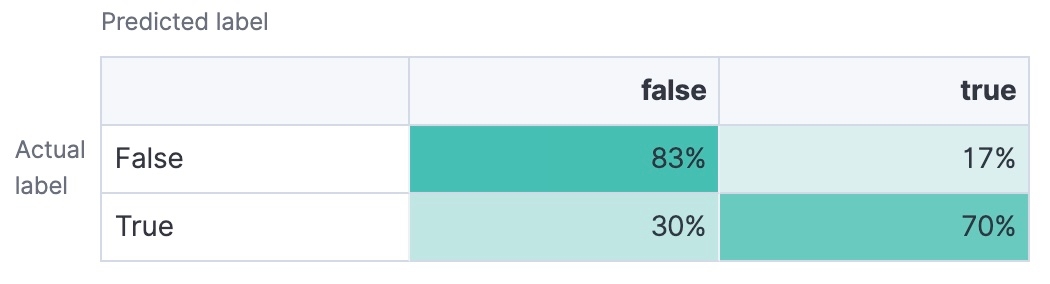
結局のところ、目指すべきは、ニーズに応じて正解率、精度、再現率、F1スコアが高いテキスト分類モデルを選択することです。また、AUC-ROCと混同行列を参考にすると、モデルが各分類のしきい値を適切に処理できるかどうかを把握し、モデルのパフォーマンスに対する理解を深められます。
テキスト分類の今後の動向
テキスト分類の今後の動向は、オープンなAIから業界ごとのツールまで多岐にわたります。機械学習の発展に伴い、テキスト分類の可能性も広がっていくでしょう。たとえば、最先端のツールやテクノロジーは、普及が進むにつれて多様化も求められます。近い将来には、現在グローバルアプリケーションで必要性が高まっている多言語対応に応え、多言語テキスト分類が開発され、1つのデータセットで複数の言語を効果的に分析できるようになると考えられます。また、法務、医療、金融などの業界に合わせて専門性の高い(したがって正確性も高い)分類を行わせるモデルのトレーニングが進んでいることから、分野特化のテキスト分類も近々登場するでしょう。
もちろん、テキスト分類の動向は、新しいAI機能にも影響します。AIアプリケーションの利用が広がるにつれ、透明性があり解釈可能なテキスト分類モデルを求める声が高まっています。説明可能なAIを実現するには、モデルの予測の根拠を理解できる説明可能な手法を組み込まなくてはなりません。
CNN(畳み込みニューラルネットワーク)、RNN(回帰型ニューラルネットワーク)、ハイブリッドモデルなどの深層学習モデルは、テキスト分類にニューラルネットワークのアーキテクチャを応用したものです。CNNは画像処理が主な用途であり、RNNは系列データを処理するためのものですが、どちらもテキストのパターンを適切に把握できることが実証されています。ハイブリッドモデルは、複数のアーキテクチャ(CNNやRNNのほか、BERTなどの変換器ベースのモデル)を組み合わせ、複数の手法の長所を活かしてより適切にテキスト分類を行うものです。
また、今後の研究では、従来よりも少ないラベル付きサンプルでテキスト分類モデルの学習を行えるようにする手法(フューショット学習)や、トレーニング中に初見のクラスでテキスト分類を行う手法(ゼロショット学習)の検討も進むでしょう。どちらの手法も、大規模なラベル付きデータセットに対する依存を大きく減らし、拡張性が高く新しいテキストにも適応しやすいテキスト分類を実現できると期待されています。
Elastiでのテキスト分類
Elasticの検索ソリューションでは、他の多くの自然言語処理機能とともにテキスト分類にも対応しています。Elasticsearchでは、構造化されていないテキストの分類から情報の抽出、抽出した情報のビジネスニーズに合わせた活用までを素早く、簡単に行えます。
目的が検索、オブザーバビリティ、セキュリティのいずれであっても、Elasticなら、ビジネスに合わせてテキスト分類を活用し、情報を効率的に抽出、整理できます。