공식 한국어 분석 플러그인 “노리”
얼마 전에 “어떤 한국어 분석기를 사용할까”라는 블로그 포스트를 발표한 적이 있습니다. 이 기사는 Elasticsearch 클러스터에 설치해서 한국어 지원을 강화할 수 있는 세 가지 서드파티 플러그인을 소개했습니다. 오늘 우리는 Elasticsearch 6.4.0에서 이 인기 있는 언어를 처리하는 동종 최고의 공식 플러그인 analysis-nori를 발표하게 되어 무척 기쁩니다. 이 블로그 포스트를 통해, 한국어 텍스트 분석을 처리하는 플러그인이 사용하는 새로운 루씬 모듈 “노리”의 배경에 대해 이야기하려고 합니다.
한국어 텍스트 나누기
한국어에서는 빈칸을 사용해서 어절(일련의 형태소의 모임. “문장 성분의 최소 단위로서 띄어쓰기의 단위가 된다(출처: 표준국어대사전)”)을 구분합니다. 예를 들어 "선생님께서"는 3개의 요소로 이루어진 어절입니다. "선생"은 명사, "님"은 높임을 나타내는 의존명사, "께서"는 주격조사로, "이/가"의 높임말입니다. 이들 개별 형태소를 자동으로 알아내는 것은 해당 언어의 어휘와 형태론에 대한 지식이 필요한 복잡한 작업입니다.
MeCab
언어에 존재하는 수많은 규칙과 예외사항으로 인해 규칙 기반 시스템을 개발하기란 매우 어려우므로 성공적인 한국어 형태소 분석기는 대부분 확률적 모델링을 사용합니다. 1998년에 한국 정부가 시작한 21세기 세종 프로젝트를 통해 대규모 한국어 말뭉치가 만들어졌습니다. 수년에 걸쳐 말뭉치가 발표된 덕에 한국어 형태소의 확률적 모델링이 보다 쉬워졌습니다. 오늘날 거의 대부분의 한국어 형태소 분석기는 21세기 세종 프로젝트에서 그 근원을 찾을 수 있습니다. mecab-ko-dic도 그 중 하나로, 21세기 세종 프로젝트에서 만들어진 말뭉치의 일부를 사용해서 한국어 형태론의 확률적 모델을 학습시킬 때, 유명한 오픈 소스 형태소 분석 엔진인 MeCab(“메카부”라고 읽습니다)를 사용합니다. MeCab는 원래 일본어를 나누기 위해 작성되었습니다. conditional random fields를 사용해서 주석 달린 말뭉치로부터 bigram 모델을 학습하는데, 이 모델에서 형태소 하나에서 다른 형태소로 이동하는 비용은 오직 이전 상태에 따라서 결정될 뿐, 언어에 따라 달라지지 않습니다. 따라서 일본어와 한국어를 분석하는 데 같은 엔진을 사용할 수 있습니다. 유일한 차이점은 사용하는 사전뿐입니다. 루씬에는 버전 3.6부터 일본어 형태소 분석기가 포함되어 있었습니다. 역시 MeCab로 만든 IPADIC 사전을 사용해서 일본어 형태소를 나누고 품사를 표시합니다. 두 사전 모두 같은 도구로 만들었기 때문에, 루씬의 일본어 분석기를 재사용해서 이 한국어 사전을 처리하는 것은 구미가 당기는 일이었습니다. 이 방법의 장점은 여러 해에 걸쳐 메모리 사용량과 속도 면에서 최적화된 견고한 분석기를 활용할 수 있다는 점입니다. 이렇게 해서 “노리”가 탄생했습니다. 일본어 분석기 코드를 가져와 독립된 한국어 분석기로 진화한 것입니다. (역자 주: 어원은 “놀이”입니다만 발음을 부드럽게 하기 위해 “노리”로 적었습니다.)
사전 압축
mecab-ko-dic 사전은 한국어를 형태학적으로 분석하는 모델을 정의합니다. MeCab에서 형태소 분석을 수행하는 데 필요한 정보를 담고 있는 서로 다른 파일들로 이루어져 있습니다. 최신판의 압축 해제 후 파일 크기는 219MB입니다. 이러한 텍스트 형태의 사전 데이터를 빠르게 검색하기 위해서, 짧은 시간에 메모리에 적재할 수 있도록 압축한 형태로 만드는 것이 새로운 한국어 모듈의 주요 도전이었습니다. 이를 위해 노리는 사전 원본을 바이너리 형태로 변환합니다. 변환은 오프라인에서 독립된 절차로 실시되며, 결과로 만들어지는 바이너리 사전은 모듈 안에 리소스로 추가됩니다. 이 변환은 모듈의 크기를 줄이기 위해 필요합니다. 루씬 모듈에 200MB 짜리 사전을 담은 채로 배포하고 싶지는 않기 때문입니다. 또한, 검색에 최적화된 포맷을 제공하기도 합니다. 형태소 분석을 하려면 입력 글자마다 사전을 찾아봐야 하므로, 효율적인 자료 구조가 필요합니다. 이제 원래의 사전을 이용해서, 같은 데이터를 담고 있지만, 보다 작고, 검색에 최적화된, 바이너리 버전을 만드는 과정을 알아보겠습니다.
* .csv file
어휘는 파일에 아래와 같이 쉼표로 구분된 값으로 저장됩니다.
도서관,1781,3535,2110,NNG,*,T,도서관,Compound,*,*,도서/NNG/*+관/NNG/*
처음 네 컬럼은 MeCab 형식의 공통 필드입니다. 첫 번째 컬럼은 단어(도서관)의 표층형(surface form)입니다. 그 다음은 이 단어의 좌문맥 ID(left context ID)와 우문맥 ID(right context ID), 마지막으로 단어의 비용(cost)입니다. MeCab는 bigram 언어 모델을 이용하므로 좌우문맥 ID를 사용해서 한 상태에서 다른 상태로 전이(transition)하는 비용을 계산합니다. 각 전이(좌에서 우)의 비용은 matrix.def 파일에 있습니다.
5번째 컬럼은 세종 말뭉치 분류에 따른 단어의 품사입니다. 전체 목록과 의미는 여기에 있는데, NNG는 일반 명사를 뜻합니다.
나머지 컬럼은 한국어와 mecab-ko-dic 형식 고유 특성(feature)입니다. 이 예에서, ‘도서관’은 “합성어”(compound. 다른 명사들로 이루어진 명사)로 간주되며, 마지막 컬럼은 분해된 모습(도서관(library) => 도서(book) + 관(house))을 보여줍니다.
노리가 입력을 분석할 때 가능한 모든 격자(lattice)를 만들기 위해 글자마다 이 사전을 찾아봐야 합니다.
사전을 효과적으로 찾아볼 수 있도록, 전체 어휘를 FST (finite state transducer)로 부호화하고, 이때 전이 레이블(transition label)은 사전 단어에 해당하는 한글 문자이고 출력은 특성 배열을 이용해서 단어의 표층형을 연관된 항목의 목록과 연결하는 ID입니다.
한글은 11,172자를 만들 수 있으므로 FST의 루트는 매우 빽빽하고 루트에서 멀어질 수록 매우 빠르게 성겨집니다. FST는 mecab-ko-dic에 포함된 811,757개의 단어를 171,397개의 노드(node)와 826,926개의 호(arc)를 이용해서 5.4MB 미만의 크기로 부호화합니다.
노리의 특성 배열은 고유한 바이너리 형식을 사용합니다. 원본 csv 파일의 각 항목을 평균 9바이트, 전체 7MB로 부호화합니다. 이런 압축은 한국어의 독특한 특성을 고려했기 때문에 가능했습니다. 예를 들어, 한국어에서 명사는 변하지 않습니다. 특정 합성어를 이루는 명사들을 저장하는 대신에 각 부분의 글자수를 부호화합니다. 위 예의 ‘도서관’은 분해해서, ‘도서’를 2로, ‘관’을 1로 부호화합니다. 합성어는 언제나 명사로 이루어지기 때문에, 각 부분의 품사도 생략할 수 있고 결국 16바이트를 2바이트로 줄일 수 있습니다.
Matrix.def
이 파일은 우문맥 ID와 좌문맥 ID 사이의 연결 비용(connection cost)을 담고 있습니다. 이들 비용은 학습 단계에서 MeCab로 계산되고 분석 때 가능한 분할의 비용을 계산하는 데 사용됩니다.
계산 결과는 커다란 행렬에 저장됩니다. 좌문맥 ID 2690개, 우문맥 ID가 3815개이므로, 전체 행렬에는 10,262,350개의 셀이 있습니다. 원본 파일은 행렬을 삼중항(우문맥 ID, 좌문맥 ID, 비용)으로 부호화하여 도합 139MB에 이릅니다. 이 정보를 바이너리 사전에 추가하기 위해, 가변 길이 부호화 기법으로 압축하고 그 결과를 파일에 직렬화(serialize)합니다. 압축 결과, 크기는 12MB 미만이 됩니다. 하지만 행렬을 빠르게 검색해야 하므로 모듈이 시작할 때 행렬을 완전히 압축해제해서 전이 당 2바이트, 전체 20MB로 메모리에 로드합니다(비용은 16비트로 부호화됩니다).
이는 자바힙에 로드하기에는 상당히 큰 리소스이므로, 힙 바깥의 direct byte buffer에 로드합니다.
바이너리 사전의 최종 크기는 디스크에서 24MB입니다. 이 정도면 바이너리 형식이 검색에 최적화되어 있음을 고려할 때 만족스럽게 압축되었다고 생각합니다. 사전 크기를 줄이는 것은 중요합니다. RAM의 크기가 제한되어 있는 상황에서도 루씬의 한국어 모듈을 사용할 수 있기 때문입니다.
형태소 분석
mecab-ko-dic 사전에 나오는 어떤 단어든지 효율적으로 검색할 수 있는 구조의 바이너리 사전을 갖추었으니, 한국어로 작성된 어떤 입력이든 가장 그럴듯하게 분할(viterbi path)하도록, 텍스트를 Viterbi 알고리즘으로 분석할 수 있습니다. 아래 그림은 21세기 세종계획이라는 문장을 가지고 만든 viterbi lattice입니다.
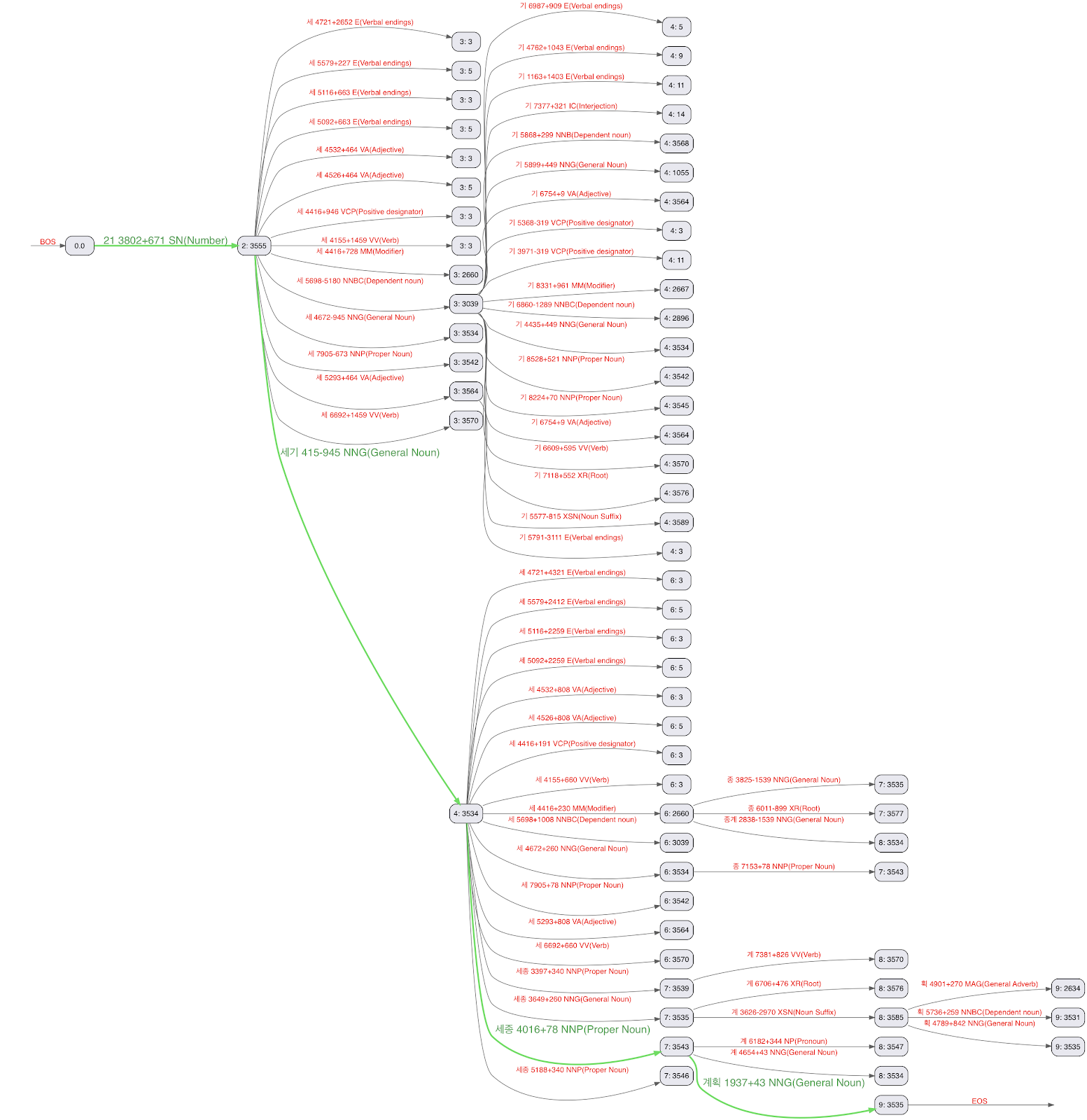
viterbi path 중 초록색이 노리가 출력하는 분할 결과입니다.
21 + 세기 (century) + 세종 (Sejong) + 계획 (Plan)
가장 좋은 분할을 찾는 알고리즘은 보통 세 단계 과정을 거칩니다. 먼저 입력에서 다음 문장 경계를 찾습니다. 그 다음 이 문장의 모든 가능한 경로의 격자를 만들고 마지막으로 각 전이의 비용을 적용함으로써 최적의 경로(분할)를 계산합니다. 입력된 모든 문장이 처리될 때까지 이 단계들을 적용합니다. 단계들을 순차적으로 적용하면 느려질 수 있으므로, 노리는 다른 접근 방법, 즉 처리량에 최적화된 단일 단계를 사용합니다. 노리는 입력을 글자 단위로 처리하며 viterbi lattice를 바로바로 만듭니다. 비용도 각 글자 경계에서 가장 비용이 낮은 경로를 유지하기 위해 바로바로 계산됩니다. 예를 들어, 위 그림에서 경로 21 + 세 + 세는 21 + 세기의 비용이 더 낮음을 발견하자마자 제거됩니다. 각 경계의 끝(특정 상태에서 가능한 전이가 하나뿐일 때)이나 1024 글자를 현재 격자의 최적 분할을 출력한 다음 처리를 마치고 다음 문자 윈도우(character window)에서 재개합니다.
벤치마크
지금까지 노리가 어떻게 구현되었는지 살펴봤습니다. 이제 실제 사례에서 어떻게 동작하는지 알아보겠습니다. Rally를 이용해서 노리와 두 가지 유명한 커뮤니티 플러그인인 seunjeon(역자주: “슨전”이라고 읽습니다)과 arirang과 비교하는 작은 벤치마크를 만들었습니다. 벤치마크는 한국어 Wikipedia에서 추출된 413,985개의 문서를 8개의 클라이언트를 이용해서 단일 샤드에 인덱싱합니다. Seunjeon 플러그인도 mecab-ko-dic 사전을 이용하고 몇 가지 옵션을 이용해서 출력을 조절할 수 있습니다. 여기서는 최신 버전(6.1.1.1, 2018년 5월 29일 기준)과 플러그인이 제공하는 디폴트 분석기를 사용했고 압축 옵션을 사용해서(-Dseunjeon.compress=true), 그리고 사용하지 않고서(-Dseunjeon.compress=false) 테스트했습니다. Elasticsearch 구성은 두 가지로, 하나는 힙크기를 512m, 또 하나는 4G로 설정했습니다. 아리랑은 고유한 사전을 이용하고 옵션을 제공하지 않으므로 플러그인이 제공하는 디폴트 분석기를 사용했습니다. 아래 그림은 두 구성에서의 벌크 인덱싱 처리량의 중간값을 보여줍니다.
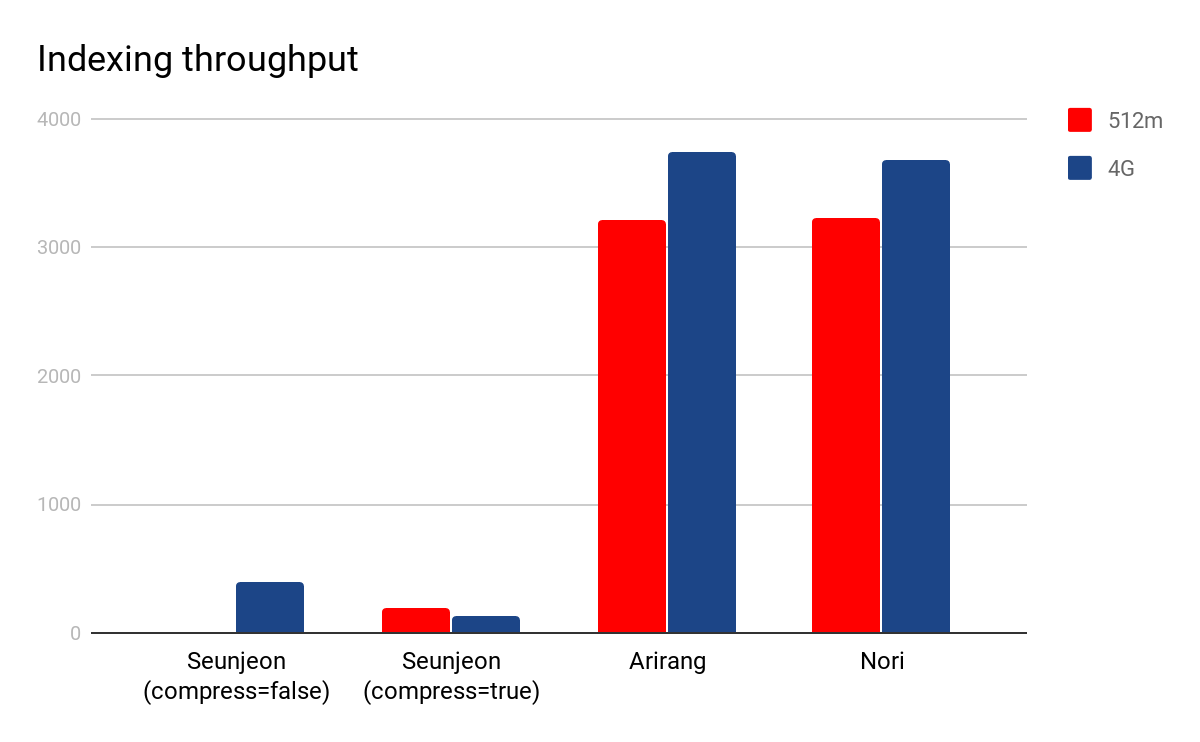
노리와 아리랑은 초당 3000개 이상의 문서를 인덱싱하는 비슷한 성능을 보였습니다. 하지만 아리랑 플러그인은 오프셋 설정 오류가 있어 말뭉치의 10%를 인덱싱하지 못했습니다. Seunjeon 플러그인은 압축하지 않았을 때 최고 초당 400개의 문서를 인덱싱했지만 512m 노드에서 실행했을 때 몇 차례 OutOfMemoryError를 내며 크래시(crash)했습니다. 이로 인해 위 그림에는 해당 구성의 결과가 빠져 있습니다. 압축을 하면 512m 구성에서도 실행되는데 초당 130개 문서를 인덱싱하여 아리랑과 노리보다 거의 30배 느렸습니다.
Conclusion
지금까지 루씬 7.4.0에 추가된 빠르고 가벼운 한국어 분석기, 노리를 소개했습니다. 우리는 루씬과 Elasticsearch에서 언어 지원을 향상시키기 위해 최선을 다하고 있으며, 노리는 그 좋은 예입니다. 자연어 처리는 종점이 아니라 여정이므로, 계속 지켜봐 주시기 바랍니다. 앞으로 더 많은 개선이 이루어질 것입니다. 그 동안 노리에 대한 Elasticsearch 문서를 통해 새로운 플러그인에 대해 더 많이 배우고 최신 버전의 Elasticsearch를 다운로드하여 직접 시험해 보시기 바랍니다!