새로 나온 이 영화 재미있을까? Elasticsearch의 supervised learning으로 예측해보자!
Elasticsearch 7.6의 Machine Learning에 classification 기능이 추가되었습니다. 기존의 anomaly detection과 달리 classification은 supervised machine learning으로, 주어진 데이터가 어느 범주에 속하는지 예측할 수 있습니다.
Classification에는 두 가지 종류가 있는데요, 어떤 영화가 액션 영화인지, 애니메이션인지, 코미디 영화인지 등 여러 범주 중 어디에 속하는지 예측하는 다중 클래스 분류(multi-class classification)와, 내가 좋아하는 영화에 속하는지, 그렇지 않은지를 예측하는 이진 분류(binary classification)가 있습니다. 이 글에서는 Elastic Stack 7.6.1에 추가된 이진분류에 대해 살펴보겠습니다.
이전에 자신이 좋아하고 싫어했던 영화의 특징을 미리 학습한 뒤 새로 나온 영화의 특징을 입력해서 자신이 좋아할지 싫어할지를 예측해 보겠습니다.
Deployment 생성
https://cloud.elastic.co에서 deployment를 만듭니다. Elastic Cloud는 14일간 무료로 사용하실 수 있습니다.
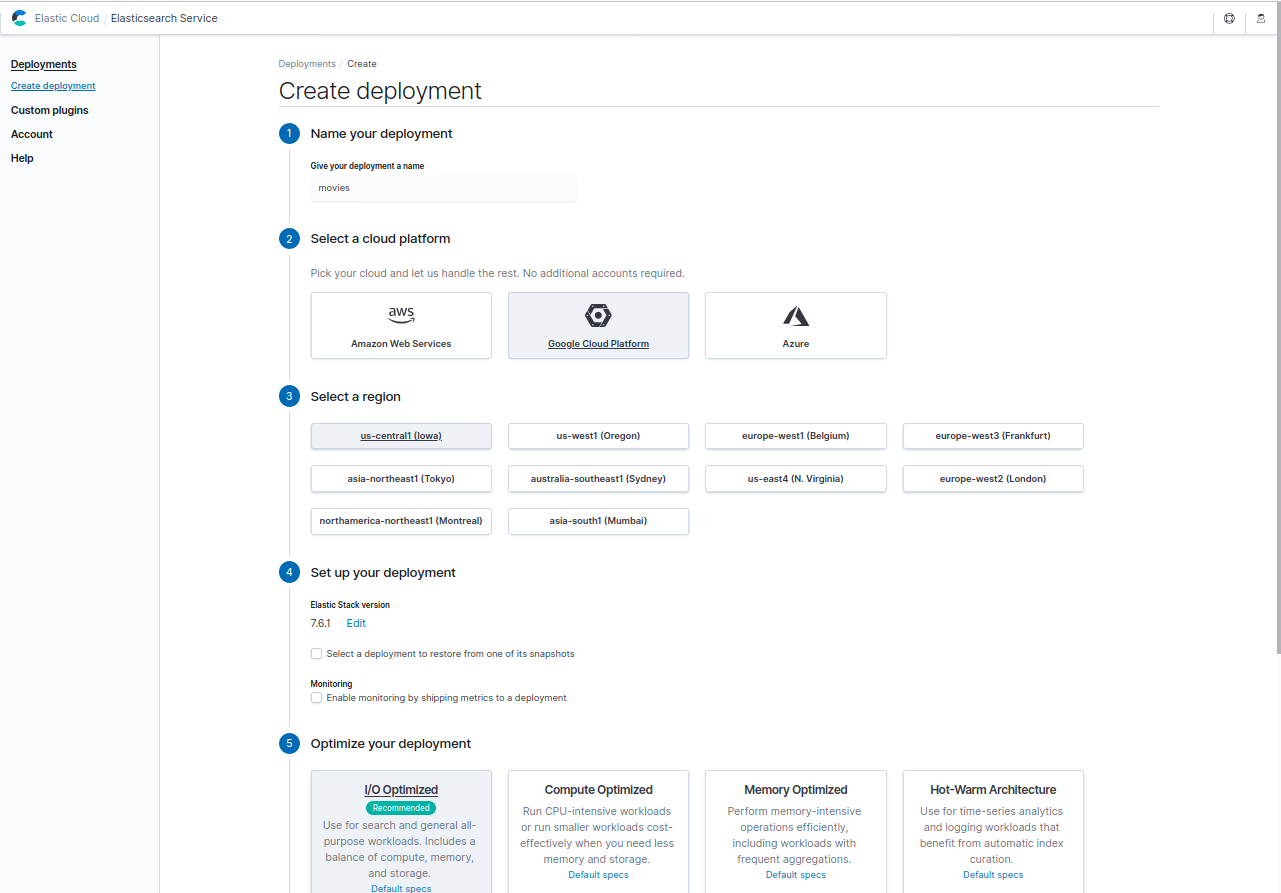
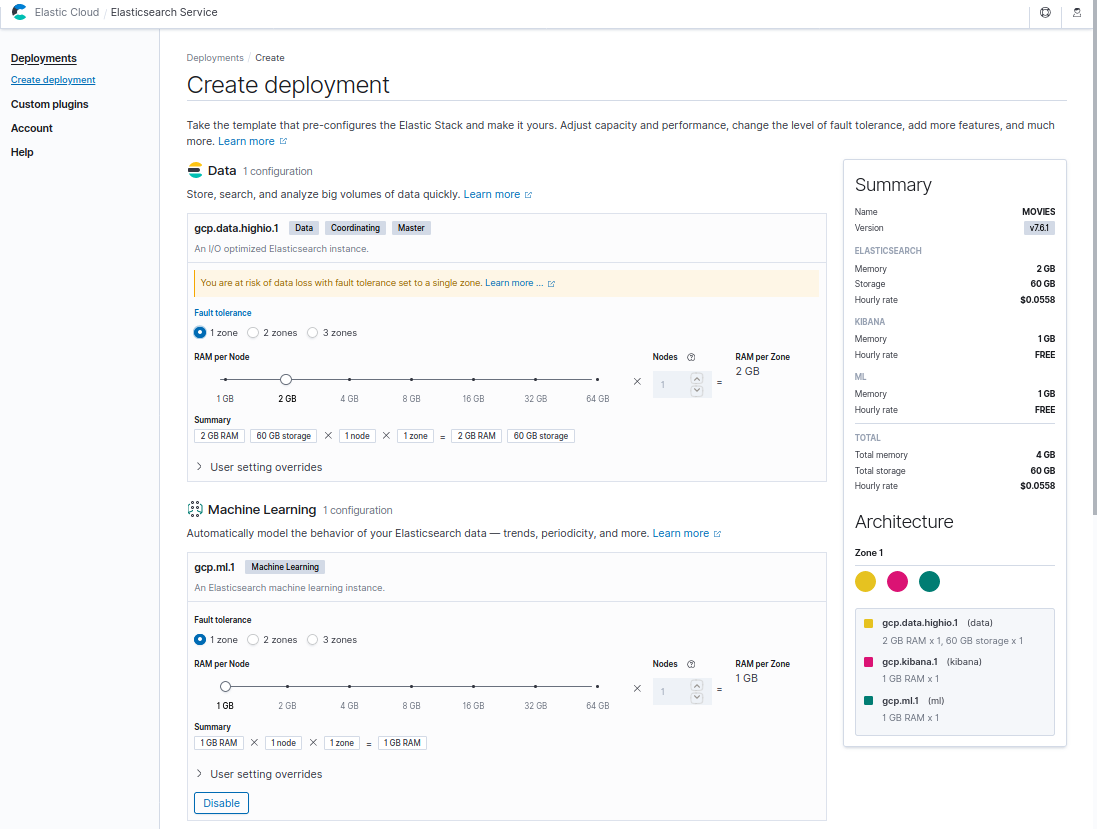
화면 하단의 Customize deployment 단추를 눌러 아래와 같이 Machine Learning 노드를 활성화한 뒤 Create deployment 단추를 눌러 deployment를 만듭니다. 구성에 대한 정보는 https://www.elastic.co/guide/en/cloud/current/ec-configure-settings.html를 참고하시기 바랍니다.
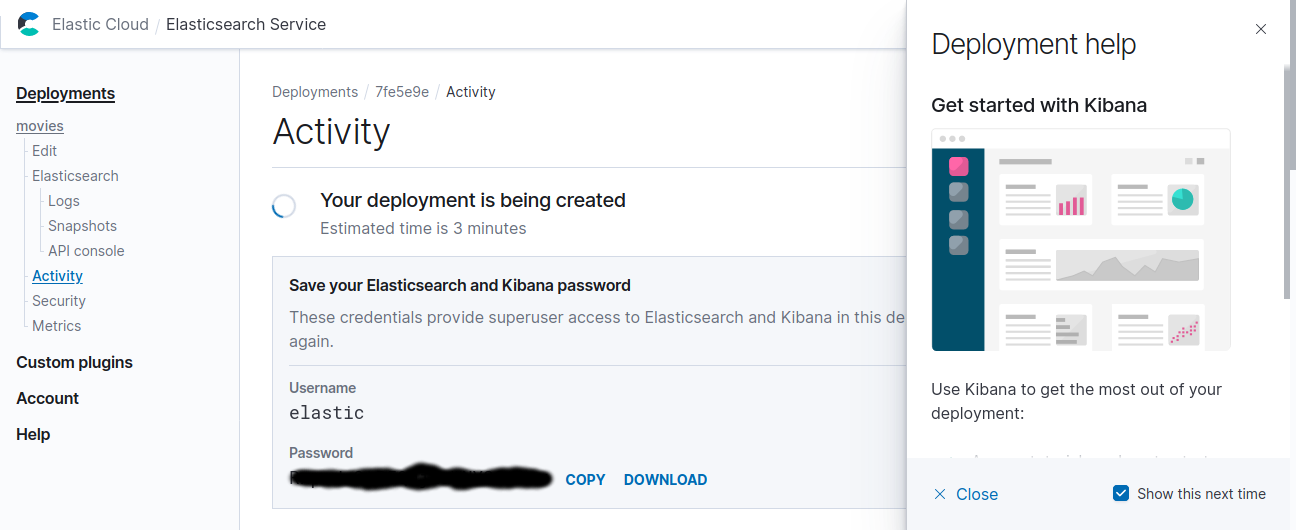
deployment를 생성하면 password가 부여되고,
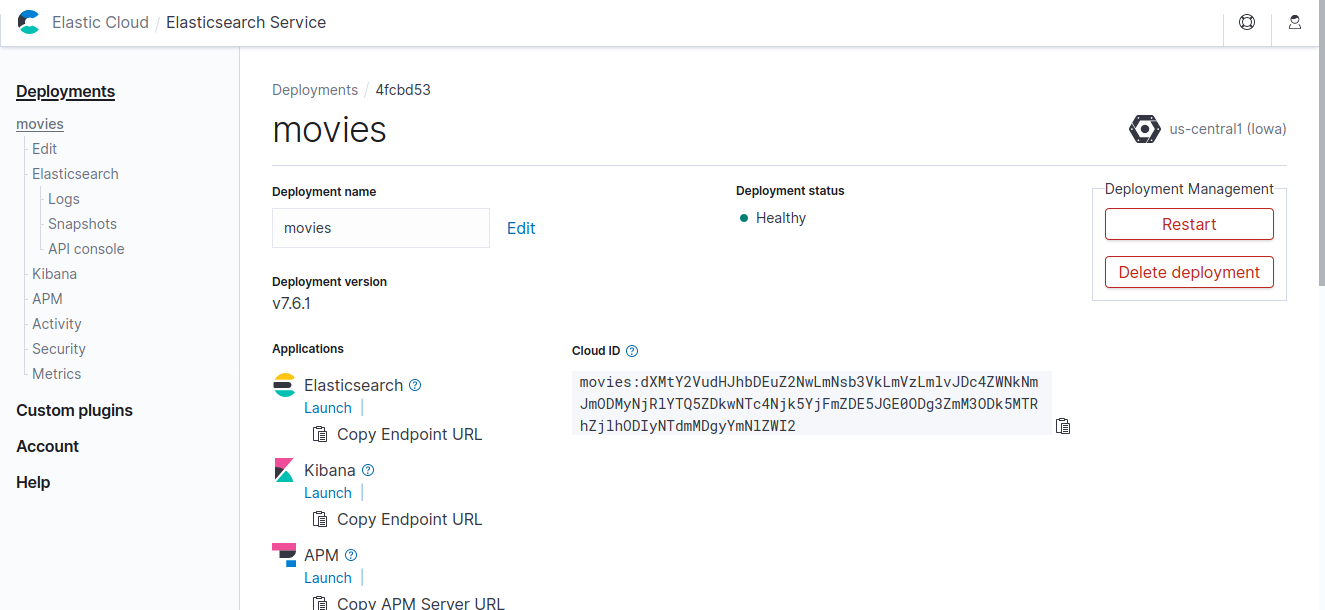
deployment가 생성되면 cloud_id가 부여됩니다.
데이터 준비
영화진흥위원회 통합전산망을 이용하면 영화제목, 제작연도, 제작국가, 장르 등의 정보를 엑셀 파일로 다운로드 받을 수 있습니다. 그중 내가 본 영화만 남기고 내 마음에 들었는지를 표시하는 like 필드(좋아하면 1, 그렇지 않으면 0)를 추가한 뒤 csv 파일(movies.csv)로 저장합니다. 본 데이터를 학습하여 모델을 만들면, 새로운 영화의 제목, 제작연도, 제작국가, 장르 등에 따라 내가 좋아할지 안할지를 예측하는 시스템을 만들 수 있습니다.
korean_title,title,year,country,length,genre,like,director,company 메멘토,Memento,2000,미국,장편,스릴러,0,크리스토퍼 놀란, 해리포터와 아즈카반의 죄수,Harry Potter And The Prisoner Of Azkaban,2004,미국,장편,드라마,1,알폰소 쿠아론,워너브러더스사㈜ …
첫 줄에 필드이름을 넣어두면 아래와 같은 logstash.conf 파일을 이용해서 Elasticsearch에 넣을 수 니습니다. Elasticsearch output의 cloud_id에는 그림 4의 Cloud ID를, cloud_auth에 그림 3의 Password를 “elastic:<Password>” 형태로 적어줍니다.
input {
file {
path => "/home/kiju/github/7/logstash-7.6.1/movies.csv"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
csv {
autodetect_column_names => true
}
}
output {
elasticsearch {
cloud_id => "movies:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDc4ZWNkNmJmODMyNjRlYTQ5ZDkwNTc4Njk5YjFmZDE5JGE0ODg3ZmM3ODk5MTRhZjlhODIyNTdmMDgyYmNlZWI2"
cloud_auth => "elastic:<Password>"
index => "movie2"
}
}
csv filter에 "autodetect_column_names => true"를 설정했으므로 config/logstash.yml에 "pipeline.workers: 1"를 설정해 줍니다(https://www.elastic.co/guide/en/logstash/7.6/plugins-filters-csv.html#plugins-filters-csv-autodetect_column_names 참고).
Kibana Dev Tools를 이용하여 Elasticsearch에 아래와 같이 mapping을 만들어 준 뒤,
PUT movie2
{
"mappings": {
"properties": {
"korean_title": {
"type": "text"
},
"title": {
"type": "text"
},
"year": {
"type": "integer"
},
"country": {
"type": "keyword"
},
"length": {
"type": "keyword"
},
"genre": {
"type": "keyword"
},
"like": {
"type": "integer"
},
"director": {
"type": "keyword"
},
"company": {
"type": "keyword"
}
}
}
}
아래와 같이 Logstash를 실행시킵니다.
$ bin/logstash -f logstash.conf
데이터가 잘 입력되었는지 Elasticsearch에서 확인합니다.
GET movie2/_search
=>
{
...
"hits" : {
"total" : {
"value" : 211,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie2",
"_type" : "_doc",
"_id" : "BCqX2HABaohLi7nef_QH",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2020-03-14T10:29:31.761Z",
"korean_title" : "메멘토",
"genre" : "스릴러",
"title" : "Memento",
...
}
},
…
Classification
데이터가 준비되었으므로 Kibana에서 classification을 수행함으로써, 내가 좋아하는 영화를 예측하기 위한 모델을 만들어 보겠습니다.
아래 화면처럼 Kibana의 Machine Learning 메뉴에 추가된 Data Frame Analysis를 선택하고 Create analytics job 단추를 누릅니다. Job type으로 classification을 선택하고 Dependent variable에 예측대상인 like를 선택합니다. Excluded fields에 영화의 특성과 관계없는 필드들을 나열한다음 Create 단추를 누르고 뒤 이어 나타나는 Start 단추를 눌러 supervised learning을 실행합니다.
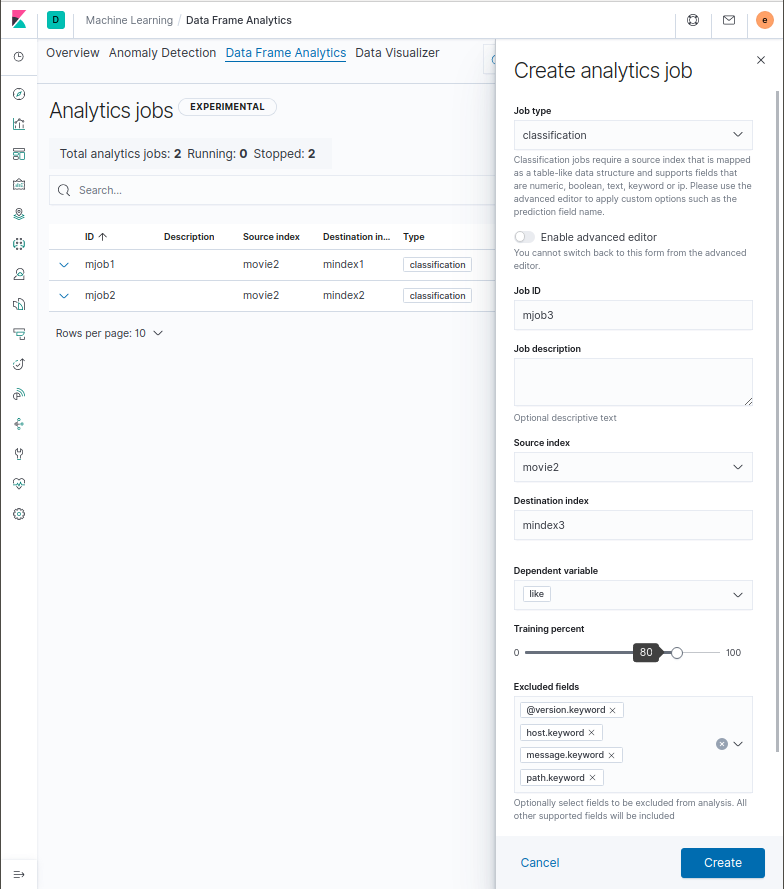
Close 단추를 눌러 오른쪽 화면을 닫고 Job의 Progress가 100%가 되면 inference를 이용해서 새로운 영화가 내 마음에 들 지 예측해볼 수 있습니다.
Inference
먼저 GET _ml/inference/_all 명령으로 mjob3 실행결과로 만들어진 model의 ID를 찾습니다. model_id는 job 이름에 timestamp가 붙은 형태(mjob3-1584187672850)입니다.
GET _ml/inference/_all
=>
{
...
{
"model_id" : "mjob3-1584187672850",
"created_by" : "_xpack",
"version" : "7.6.1",
"description" : "",
"create_time" : 1584187672850,
"tags" : [
"mjob1"
],
…
다음으로 ingest pipeline을 이용해서 inference processor를 실행합니다. 궁금한 영화에 대한 정보를 simulate pipeline API에 document로 제공하면 아래와 같이 predicted_value가 1이면 좋아할 가능성이 높고, 0이면 그렇지 않을 것으로 예상됨을 알 수 있습니다.
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "mjob3-1584187672850",
"inference_config": {
"classification": {}
},
"field_mappings": {}
}
}
]
},
"docs": [
{
"_source": {
"korean_title": "구름빵 - 하늘에서 내려온 선물",
"title": "Cloud Bread - The Day The Laundry Flew Off In The Wind",
"year": 2010,
"country": "한국",
"length": "장편",
"genre": "애니메이션",
"director": "장재운"
}
},
{
"_source": {
"country": "한국",
"year": "'2008",
"director": "김한민",
"length": "장편",
"title": "Handphone",
"korean_title": "핸드폰",
"genre": "스릴러"
}
}
]
}
=>
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"korean_title" : "구름빵 - 하늘에서 내려온 선물",
"country" : "한국",
"year" : 2010,
"director" : "장재운",
"length" : "장편",
"genre" : "애니메이션",
"title" : "Cloud Bread - The Day The Laundry Flew Off In The Wind",
"ml" : {
"inference" : {
"predicted_value" : "1",
"model_id" : "mjob3-1584187672850"
}
...
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"korean_title" : "핸드폰",
"country" : "한국",
"year" : "'2008",
"director" : "김한민",
"length" : "장편",
"genre" : "스릴러",
"title" : "Handphone",
"ml" : {
"inference" : {
"predicted_value" : "0",
"model_id" : "mjob3-1584187672850"
}
...
]
}
정말 맞을까?
Elasticsearch의 예측에 따르면, 나는 "구름빵 - 하늘에서 내려온 선물"을 좋아할 가능성이 높고 "핸드폰"은 그렇지 않을 것으로 보입니다. 코로나19로 인해 집에 머물고 있는 아이들과 함께 "구름빵 - 하늘에서 내려온 선물"을 보기로 했고, 덕분에 즐거운 시간을 보낼 수 있었습니다.
여러분도 해 보세요
지금까지 Elasticsearch 7.6에 추가된 classification 기능을 이용해서 아직 보지 않은 영화가 마음에 들지 안들지를 예측해 보았습니다. 이 외에도 부품의 불량 여부, 대출 적격성, 암 발생 여부 등을 예측하는 데 사용할 수 있습니다. 참고로, 제가 테스트에 사용한 자료는 https://github.com/kiju98/ml/raw/master/logstash.zip에 있습니다.