Fonctionnalités de la Suite Elastic
API pensées pour les développeurs, fonctionnalités de sécurité conçues pour les entreprises, Machine Learning et analyses de graphes… Voilà quelques-unes des fonctionnalités de la Suite Elastic (certaines initialement regroupées dans X-Pack) qui vous aident à ingérer, stocker, analyser, rechercher et visualiser tous types de données à grande échelle.
Gestion et opérations
Scalabilité et résilience
Monitoring
Gestion
Alerting
Sécurité de la Suite
Déploiement
Ingérer et enrichir
Sources de données
Enrichissement des données
Modules et intégrations
Stockage de données
Flexibilité
Sécurité
Rechercher et analyser
Recherche full-text
Machine Learning
Explorer et visualiser
Visualisations
Partager et collaborer
Elastic Maps
Elastic Logs
Elastic Metrics
Elastic Uptime
Elastic Security
Gestion et opérations
Gestion et opérations
Scalabilité et résilience
Ce n'est pas un hasard si, dès l'origine, nous avons opté pour un environnement distribué conçu pour rimer avec tranquillité d'esprit. Nos clusters évoluent en fonction de vos besoins – il suffit d'ajouter un nœud.
Clustering et haute disponibilité
Un cluster est un ensemble constitué d'un ou de plusieurs nœuds (serveurs). Il stocke toutes vos données et vous permet de centraliser l'indexation et la recherche des données sur l'ensemble des nœuds. Les clusters Elasticsearch sont dotés de partitions principales et de copies pour fournir un basculement en cas de panne d'un nœud. Lorsqu'une partition principale tombe en panne, la copie prend sa place.
Découvrir le clustering et la haute disponibilitéRécupération automatique de nœud
Lorsqu'un nœud sort du cluster pour n'importe quelle raison, intentionnelle ou non, le nœud maître réagit en remplaçant le nœud par une copie et en rééquilibrant les partitions. Ces actions ont pour but de protéger le cluster contre la perte de données en s'assurant que toutes les partitions sont entièrement répliquées aussi vite que possible.
En savoir plus sur l'attribution de nœudRééquilibrage automatique des données
Le nœud maître de votre cluster Elasticsearch décide automatiquement quelles partitions attribuer à quels nœuds, et quand déplacer les partitions entre les nœuds pour rééquilibrer le cluster.
Découvrir le rééquilibrage automatique des donnéesScalabilité horizontale
Plus vous utilisez Elasticsearch, plus il scale avec vous. Ajoutez plus de données, plus de cas d'utilisation, et lorsque vous commencez à manquer de ressources, ajoutez simplement un autre nœud à votre cluster pour augmenter sa capacité et sa fiabilité. Enfin, lorsque vous ajoutez plus de nœuds à un cluster, Elasticsearch attribue automatiquement des partitions copies pour que vous soyez préparé pour les événements futurs.
Découvrir la montée en charge horizontaleOpérations de rack
Vous pouvez utiliser des attributs de nœud personnalisés en tant qu'attributs d'opération pour permettre à Elasticsearch de prendre en compte la configuration de votre matériel physique lorsqu'il affecte des partitions. Si Elasticsearch sait quels nœuds se situent sur le même serveur physique, dans le même rack, ou dans la même zone, il peut distribuer la partition principale et les partitions répliquées pour minimiser le risque de perte de toutes les copies de partition en cas de panne.
Découvrir les opérations d'attributionRéplication inter-clusters
La fonctionnalité de réplication inter-clusters (CCR) permet de répliquer les index situés dans des clusters distants sur un cluster local. Cette fonctionnalité peut être utilisée dans des cas d'utilisation de production communs.
Découvrir la CCRReprise d'activité après sinistre : si un cluster principal tombe en panne, un cluster secondaire peut servir de sauvegarde "hot".
Proximité géographique : les lectures peuvent être servies localement et diminuer le temps de réponse du réseau.
Réplication inter-data center
Cela fait longtemps que la réplication inter-data center est une exigence des applications critiques d'Elasticsearch. Auparavant, Elasticsearch recourait à des technologies supplémentaires pour répondre à cette exigence. Grâce à la réplication inter-cluster d'Elasticsearch, vous n'avez pas besoin de technologies supplémentaires pour répliquer des données dans plusieurs data centers, régions ou clusters Elasticsearch.
Découvrir la réplication inter-data centerGestion et opérations
Monitoring
Les fonctionnalités de monitoring de la Suite Elastic vous donnent une visibilité à 360 degrés sur son fonctionnement. Gardez un œil sur ses performances pour être sûr d'exploiter tout son potentiel.
Monitoring full-stack
Les fonctionnalités de monitoring de la Suite Elastic vous donnent un aperçu du fonctionnement d'Elasticsearch, de Logstash et de Kibana. L'ensemble des indicateurs de monitoring sont stockés dans Elasticsearch, ce qui vous permet de visualiser facilement les données de Kibana.
Découvrir le monitoring de la Suite Elastic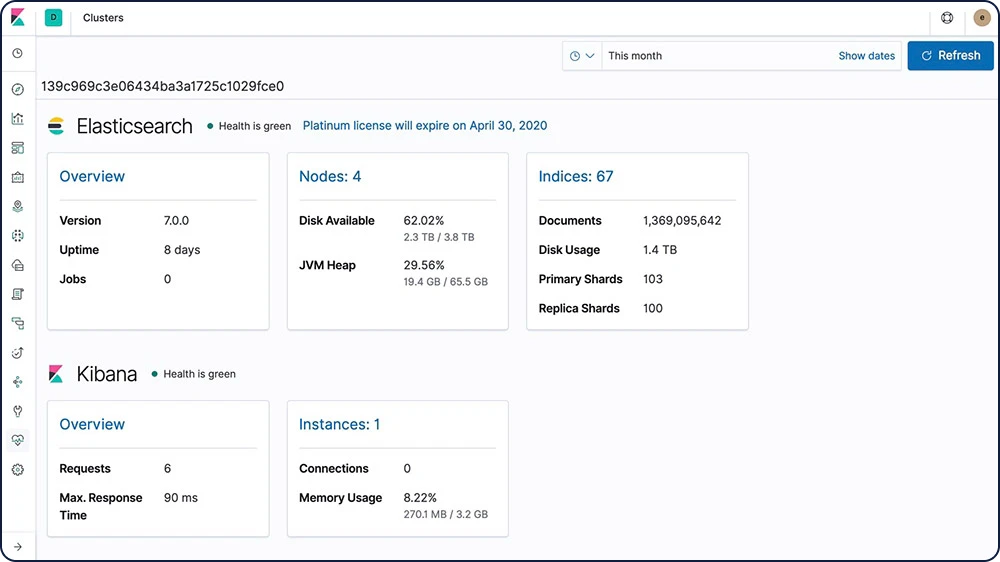
Monitoring multi-stack
Simplifiez votre charge de travail à l'aide d'un cluster de monitoring centralisé pour enregistrer, suivre et comparer l'état de santé et la performance de multiples clusters Elasticsearch.
Découvrir le monitoring multi-stackRègle de conservation configurable
Grâce à la Suite Elastic, vous pouvez contrôler la durée de conservation des données de monitoring. La durée par défaut est de 7 jours, mais vous pouvez définir celle que vous souhaitez.
Découvrir les règles de conservationAlertes automatiques concernant les problèmes de stack
Avec les fonctionnalités d'Alerting de la Suite Elastic, recevez des notifications automatiques lorsque des changements interviennent dans votre cluster (état du cluster, expiration de licence et autres indicateurs d'Elasticsearch, Kibana et Logstash, par exemple).
En savoir plus sur les alertes automatiques relatives aux stacks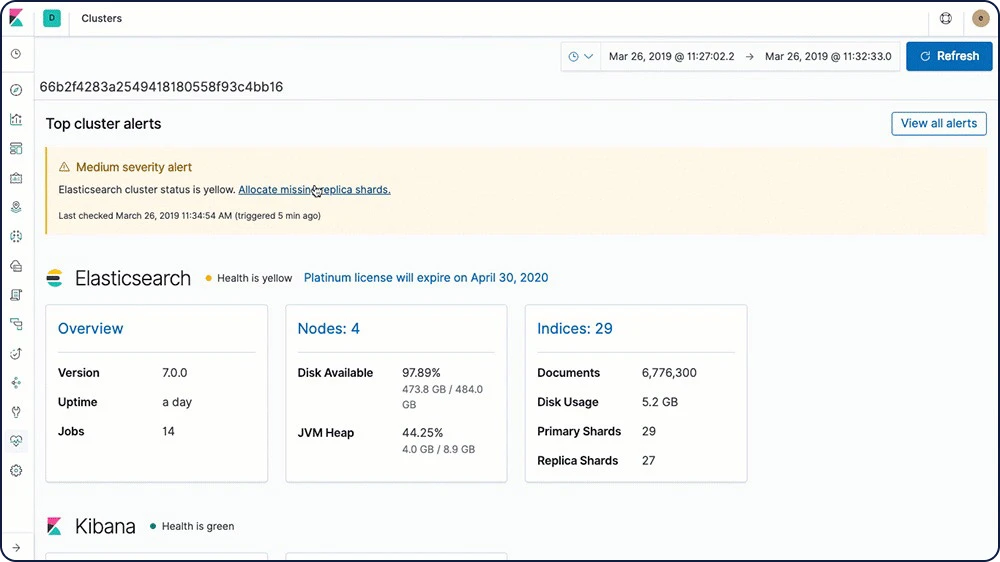
Gestion et opérations
Gestion
La Suite Elastic comprend différents outils de gestion, interfaces utilisateur et API, qui vous confèrent un contrôle total sur les données, les utilisateurs, les opérations de cluster, et plus encore.
Gestion du cycle de vie des index
La gestion du cycle de vie des index (ILM) permet à l'utilisateur de définir et d'automatiser des règles de contrôle de la durée pendant laquelle un index doit être utilisé dans les quatre phases, ainsi que les actions à effectuer dans l'index pendant chaque phase. Cela permet de mieux contrôler le coût des opérations, car on peut placer les données dans des niveaux de ressource différents.
Découvrir l'ILM"Hot" (brûlant) : fréquemment mis à jour et recherché
"Warm" (chaud) : toujours recherché, malgré l'absence de mise à jour
"Cold/Frozen" (froid/glacé) : aucune mise à jour et presque jamais recherché (la recherche est possible, mais plus lente)
"Delete" (supprimer) : l'index n'est plus nécessaire
Niveaux de données
Les niveaux de données constituent une approche formalisée pour répartir les données sur des nœuds hot, warm et cold. C'est un attribut de rôle de nœud qui définit automatiquement la stratégie de gestion du cycle de vie des index de vos nœuds. En attribuant des rôles hot, warm et cold aux nœuds, vous pouvez grandement simplifier et automatiser le processus de déplacement des données, et passer ainsi d'un stockage coûteux à hautes performances à un stockage économique aux performances inférieures, le tout, sans sacrifier la visibilité recherchée.
Découvrir les niveaux de données- Hot : données fréquemment mises à jour et interrogées sur l'instance la plus performante
Warm : données interrogées de temps à autre sur des instances un peu moins performantes
Cold : données en lecture seule, rarement interrogées ; réduction drastique du stockage sans perte de performances, permise par les snapshots interrogeables
Snapshot et restauration
Un instantané est une sauvegarde d'un cluster Elasticsearch en cours d'exécution. Vous pouvez créer un snapshot soit d'index individuels, soit de tout le cluster, et stocker ce snapshot dans un référentiel dans un système de fichier partagé. Des plug-ins qui prennent également en charge les référentiels distants sont disponibles.
Découvrir la fonction sauvegarder et restaurerSnapshots interrogeables
Avec les snapshots interrogeables, pas besoin de passer par une procédure de restauration longue et fastidieuse pour effectuer une recherche sur vos snapshots. Tout se fait en un claquement de doigts. En effet, pour traiter la requête, seuls les éléments nécessaires sont lus sur chaque snapshot. Par ailleurs, avec le niveau "cold", les snapshots interrogeables vous permettent de faire des économies sur vos coûts de stockage. Ils sauvegardent vos partitions répliquées dans des systèmes de stockage d'objets comme Amazon S3, Azure Storage ou Google Cloud Storage, tout en vous concédant un accès complet pour y faire vos recherches.
En savoir plus sur les snapshots interrogeablesGestion du cycle de vie des snapshots
En tant que gestionnaires de snapshots d'arrière-plan, les API "Snapshot Lifecycle Management" (SLM) permettent aux administrateurs de définir la fréquence à laquelle sont effectués les snapshots d'un cluster Elasticsearch. Grâce à l'interface utilisateur SLM dédiée, les utilisateurs peuvent configurer les règles de conservation applicables à SLM, mais aussi créer, planifier et supprimer automatiquement des snapshots. Cela assure que pour un cluster donné, les sauvegardes nécessaires sont effectuées à une fréquence suffisante pour permettre une restauration conforme aux SLA du client.
Découvrir le SLMRestaurations par les pairs basées sur des snapshots
Grâce à cette fonctionnalité, Elasticsearch est en mesure de récupérer des réplicas et de déplacer les principales partitions provenant d'un snapshot récent lorsque les données sont disponibles. Ainsi, les coûts d'exploitation diminuent pour les clusters exécutés dans un environnement où les frais de transfert des données entre les nœuds sont supérieurs à ceux générés par la récupération des données à partir d'un snapshot.
En savoir plus sur les restaurations par les pairs basées sur des snapshotsCumul de données
Conserver les données historiques pour les analyser est extrêmement utile, mais il s'agit de quelque chose qu'on évite souvent en raison du coût financier associé à l'archivage de quantités astronomiques de données. Par conséquent, les périodes de conservation sont influencées par les réalités financières plutôt que par l'utilité d'avoir à disposition une quantité importante de données historiques. La fonctionnalité de cumul vous donne le moyen de résumer et stocker les données historiques pour pouvoir les analyser, mais pour seulement une fraction du coût de stockage des données brutes.
Découvrir les cumuls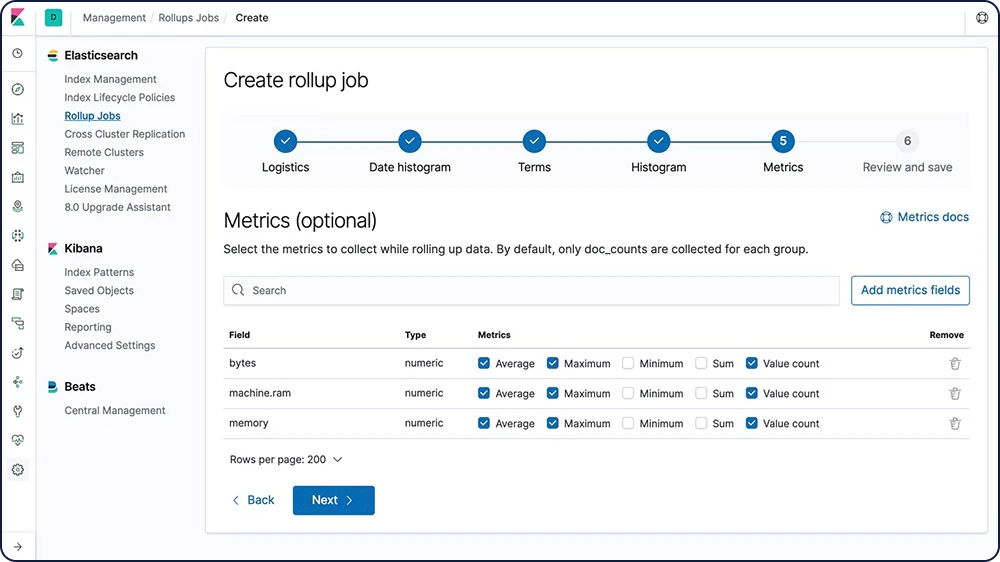
Flux de données
Avec les flux de données, vous ingérez, recherchez et gérez des données de séries temporelles générées en continu. Pratique !
En savoir plus sur les flux de donnéesOutils CLI
Elasticsearch fournit plusieurs outils qui permettent de configurer la sécurité et de réaliser d'autres tâches par le biais de lignes de commande.
Explorer les outils CLIInterface utilisateur de l'assistant de mise à niveau
L'interface utilisateur de l'assistant de mise à niveau vous aide à préparer votre mise à niveau vers la version la plus récente de la Suite Elastic. Dans l'interface utilisateur, l'assistant identifie les paramètres dépréciés dans votre cluster et dans vos index et vous guide tout au long du processus de résolution de problèmes, y compris la réindexation.
Découvrir l'assistant de mise à jour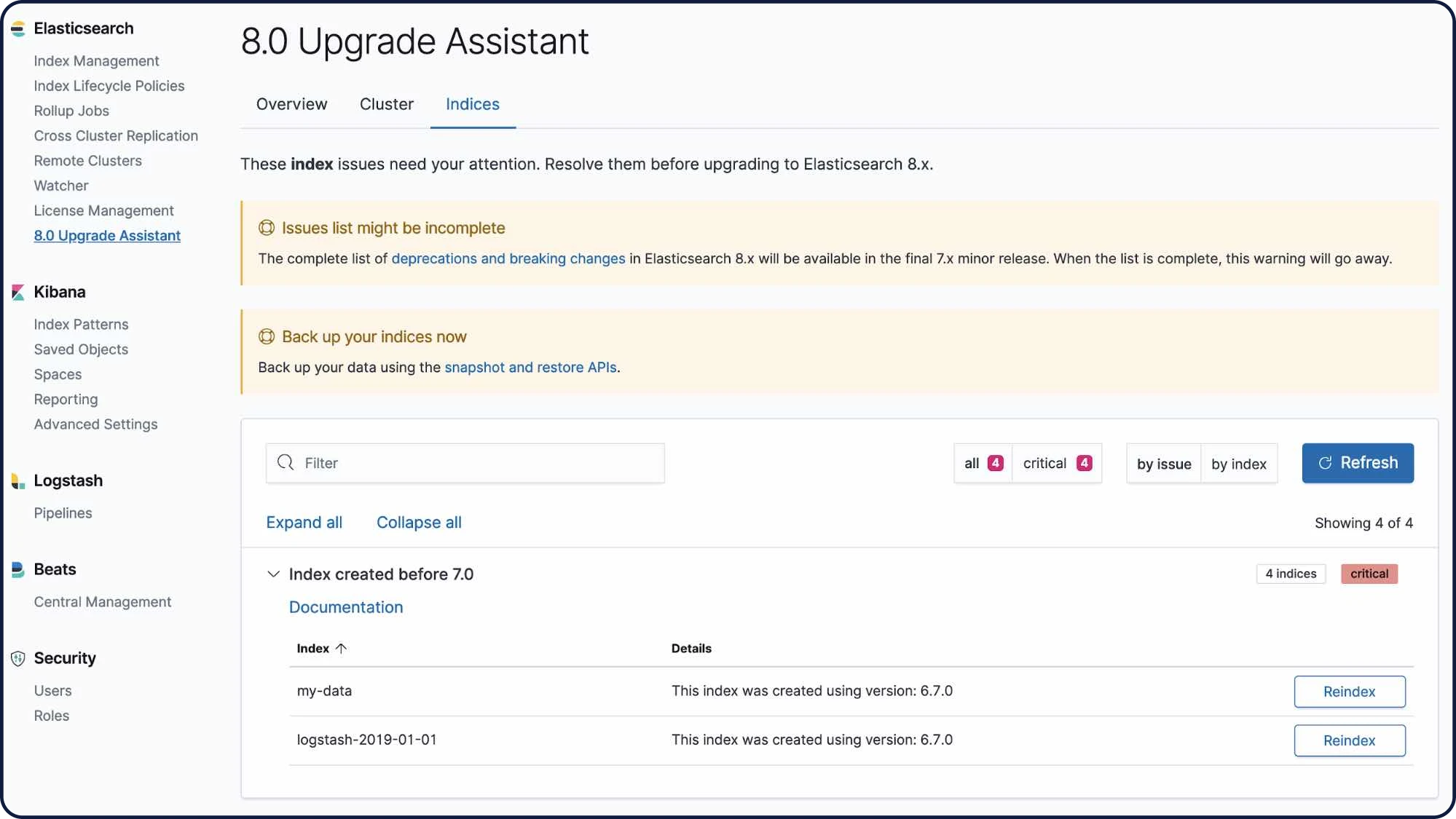
API d'assistant de mise à jour
L'API d'assistant de mise à jour vous permet de consulter le statut de mise à jour de votre cluster Elasticsearch et de réindexer les index créés dans la version majeure précédente. L'assistant vous aide à vous préparer pour la prochaine version majeure d'Elasticsearch.
Découvrir l'API d'assistant de mise à jourGestion des utilisateurs et des rôles
Créez et gérez les utilisateurs et les rôles par le biais d'un API ou depuis l'application Management de Kibana.
Découvrir la gestion d'utilisateur/de rôle
Transformations
Les transformations sont des structures de données tabulaires bidimensionnelles qui rendent les données indexées plus faciles à assimiler. Elles réalisent des agrégations qui réorganisent vos données dans un nouvel index centré sur les entités. En transformant et en résumant vos données, vous avez la possibilité de les visualiser et de les analyser de manière différente, y compris en tant que source pour d'autres analyses de Machine Learning.
Découvrir les transformationsGestion et opérations
Alerting
Avec les fonctionnalités d'alerting de la Suite Elastic, toute la puissance du langage de requête d'Elasticsearch est entre vos mains : vous pouvez ainsi identifier les modifications apportées aux données qui vous intéressent. En d'autres termes, tout ce que vous pouvez rechercher dans Elasticsearch peut aussi faire l'objet d'une alerte.
Alerting hautement disponible et évolutif
Ce n'est pas par hasard que les organisations de toutes tailles font confiance à la Suite Elastic pour gérer leurs besoins d'alerte. En ingérant de manière fiable et sécurisée les données de toutes les sources, dans tous les formats, les analystes peuvent faire des recherches, analyser, et visualiser des données clés en temps réel ; tout cela avec un système d'alerte fiable et personnalisé.
En savoir plus sur AlertingNotifications par e-mail, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Liez les alertes à des outils d'intégration embarqués pour IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters et Slack ou encore les e-mails. Intégrez-les à tout autre système tiers via une sortie webhook.
Options de notification d'alerte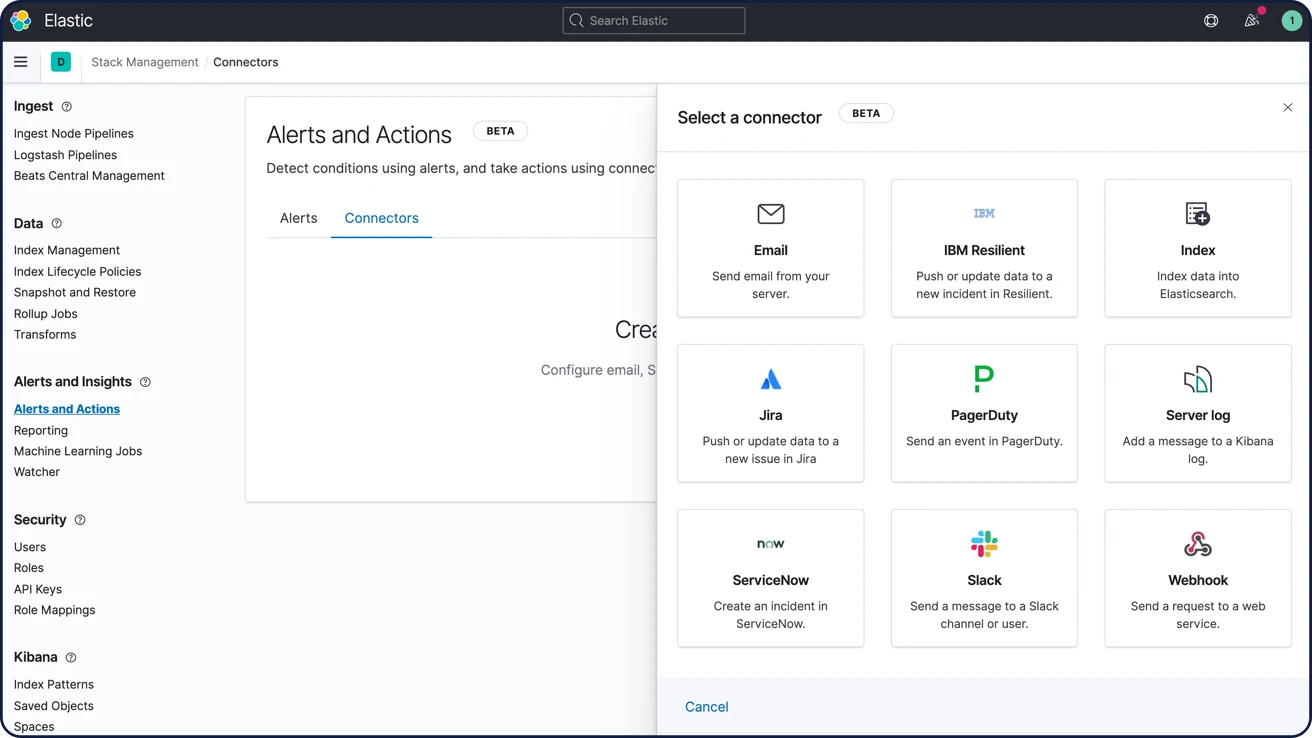
Interface utilisateur d’alerting
Contrôlez toutes vos alertes de A à Z via une seule et même interface utilisateur, qui vous permet de les créer, de les visualiser et de les gérer. De plus, grâce à des mises à jour à en temps réel, plus rien ne vous échappe : vous connaissez les alertes en cours et les actions entreprises.
En savoir plus sur la configuration d'alertes dans Kibana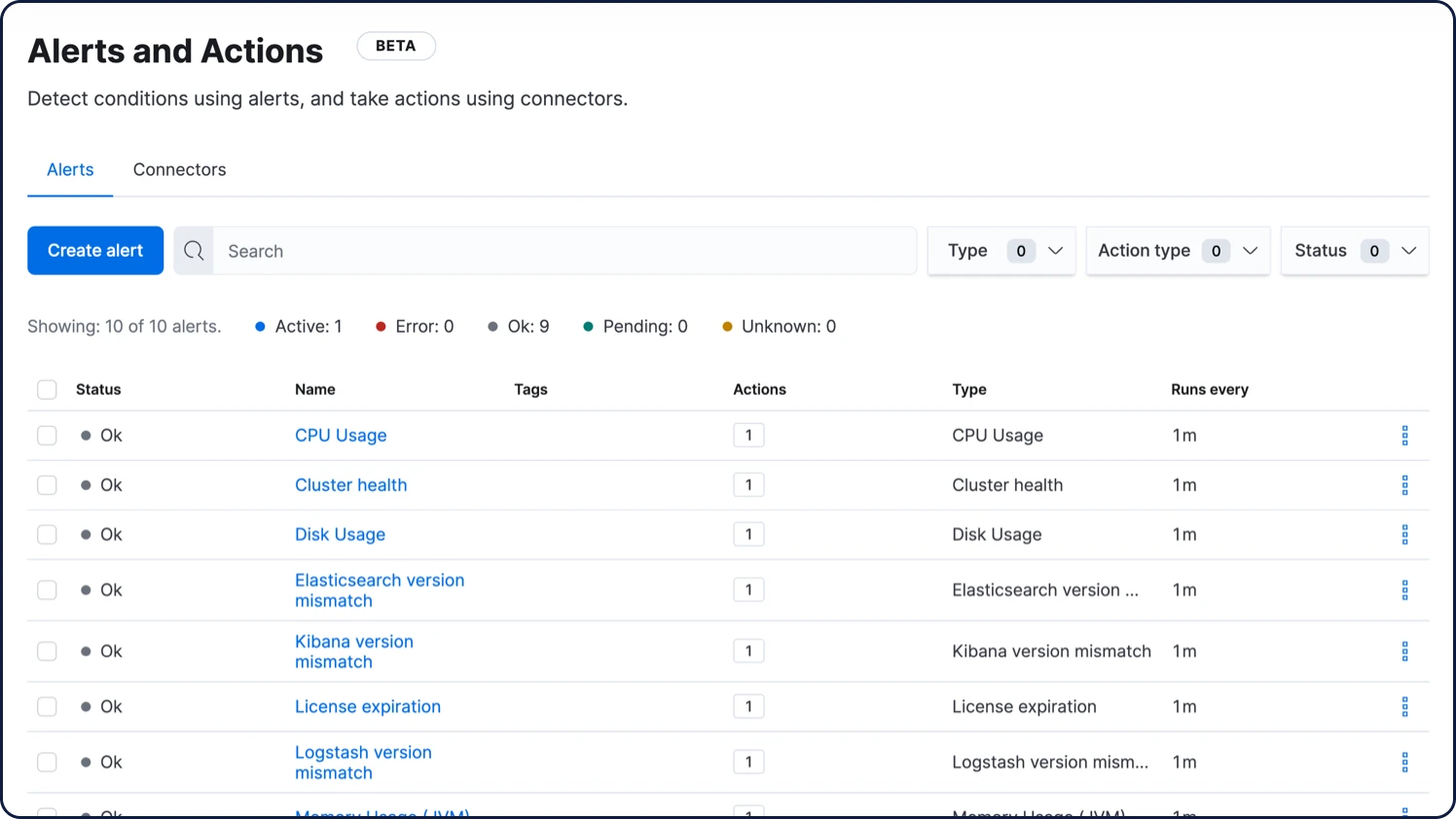
Suppression d'alerting et réduction du bruit
Désactivez momentanément les règles d'alerte afin de masquer les notifications et les actions pour une durée définie par l'utilisateur. Vous ne manquerez jamais une action parce que vous avez oublié de réactiver une règle en traitant des problèmes survenus de manière inattendue ou pendant des périodes d'indisponibilité connues.
Suppression d'alerting et réduction du bruitAlertes de seuil de recherche pour Discover
Dans Discover, une règle de seuil de recherche est basée sur une requête Elasticsearch. Elle analyse les documents sur un intervalle donné et vérifie si les documents répondant aux critères indiqués ont atteint un seuil. Si tel est le cas, elle déclenche alors une alerte. Les utilisateurs peuvent créer et attribuer une action s'ils souhaitent qu'une notification soit déclenchée ou qu'un incident soit automatiquement créé.
En savoir plus sur les alertes de seuil de recherche pour DiscoverGestion et opérations
Sécurité de la Suite
Les fonctionnalités de sécurité de la Suite Elastic accordent aux utilisateurs les droits d'accès appropriés. Les équipes informatiques, opérationnelles, et celles en charge des applications peuvent s'appuyer sur ces fonctionnalités pour gérer les utilisateurs bien intentionnés et repousser les acteurs malveillants. La direction et les clients sont plus zen : les données stockées dans la Suite Elastic sont totalement sécurisées.
Paramètres sécurisés
Certains paramètres sont sensibles. Se fier aux seules autorisations des systèmes de fichiers pour protéger leurs valeurs est insuffisant. Les composants de la Suite Elastic proposent donc des magasins de clés pour empêcher les accès non autorisés aux paramètres sensibles du cluster. Et pour encore plus de sécurité, vous avez aussi la possibilité de protéger les magasins de clés Elasticsearch et Logstash par mot de passe.
En savoir plus sur les paramètres sécurisésCommunications chiffrées
Les attaques réseau sur les données de nœud Elasticsearch peuvent être contrées grâce au chiffrement du trafic à l'aide du protocole SSL/TLS, de certificats d'authentification de nœud, et autres.
Découvrir le chiffrement des communicationsPrise en charge du chiffrement au repos
Bien que la Suite Elastic ne mette pas en place le chiffrement au repos de base, nous vous recommandons de configurer un chiffrement au niveau du disque dur sur l'ensemble des machines hôtes. De plus, les cibles de snapshot doivent aussi assurer le chiffrement des données au repos.
Contrôle d'accès basé sur les rôles (RBAC)
Le contrôle d'accès basé sur les rôles (RBAC) vous permet d'accorder des autorisations à certains utilisateurs en attribuant des privilèges à certains rôles et en attribuant des rôles à des utilisateurs ou des groupes.
Découvrir le RBAC
Contrôle d'accès basé sur les attributs (ABAC)
Les fonctionnalités de sécurité de la Suite Elastic fournissent également un mécanisme de contrôle d'accès basés sur les attributs (ABAC) qui vous permet d'utiliser les attributs pour restreindre l'accès aux documents dans les requêtes de recherche et les agrégations. Cela vous permet de mettre une règle d'accès en place dans une définition de rôle pour que les utilisateurs ne puissent lire un document spécifique que s'ils ont les attributs requis.
Découvrir l'ABACContrôle d'accès anonyme (pour le partage public)
Des cartes aux tableaux de bord en passant par tout objet sauvegardé dans Kibana, vous pouvez désormais créer des liens spécialisés permettant à tout utilisateur d'accéder à une ressource spécifique sans devoir saisir d'identifiants.
En savoir plus sur l'accès anonymeSécurité au niveau du champ et du document
La sécurité au niveau du champ restreint les champs auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau du champLa sécurité au niveau du document restreint les documents auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau du documentLogging d'audits
Vous pouvez activer les audits pour suivre les événements de sécurité comme les échecs d'authentification et les connexions refusées. Le logging de ces événements vous permet de monitorer votre cluster à la recherche d'activité suspicieuse et vous fournit des preuves en cas d'attaque.
Découvrir le logging d'auditFiltrage IP
Vous pouvez appliquer un filtrage IP aux clients d'application, de nœud et de transport, en plus d'autres nœuds qui tentent de rejoindre le cluster. Si l'adresse IP d'un nœud se trouve sur la liste noire, les fonctionnalités de sécurité d'Elasticsearch autorisent la connexion à Elasticsearch, mais celle-ci est abandonnée immédiatement et aucune requête n'est traitée.
Adresse IP ou ensemble
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Liste blanche
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Nom d'hôte
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Découvrir le filtrage IP
Domaines de sécurité
Les fonctionnalités de sécurité de la Suite Elastic authentifient les utilisateurs à l'aide de domaines et d'un ou plusieurs services d'authentification par token. On utilise les domaines pour résoudre et authentifier les utilisateurs en fonction de tokens d'authentification. Les fonctionnalités de sécurité fournissent plusieurs domaines intégrés.
Découvrir les domaines de sécuritéAuthentification unique (SSO)
La Suite Elastic prend en charge l'authentification unique (SSO) SAML dans Kibana, en utilisant Elasticsearch comme service back-end. L'authentification SAML permet aux utilisateurs de se connecter à Kibana à l'aide d'un fournisseur d'identité externe, comme Okta ou Auth0.
Découvrir la SSOIntégrations tierces de sécurité
Si vous utilisez un système d'authentification non pris en charge dès le départ avec les fonctionnalités de sécurité de la Suite Elastic, vous pouvez créer un domaine personnalisé pour authentifier les utilisateurs.
Découvrir la sécurité tierceMode FIPS 140-2
Elasticsearch propose un mode compatible FIPS 140-2 qui peut s'exécuter dans une JVM activée. Les algorithmes cryptographiques agréés FIPS/recommandés par NIST garantissent le respect des normes de traitement.
Découvrir la compatibilité FIPS 140-2Section 508
Si vous avez besoin que le déploiement de votre Suite Elastic respecte les normes de conformité à la section 508, les fonctionnalités de sécurité s'en chargent.
Découvrir les normes de conformitéStandards (GDPR)
Il y a de grandes chances que vos données soient classifiées comme données à caractère personnel par les directives du règlement général sur la protection des données (RGPD). Découvrez comment vous pouvez utiliser les fonctionnalités de la Suite Elastic ; du contrôle d'accès basé sur les rôles au chiffrement des données ; pour mettre vos données Elasticsearch en conformité avec les exigences de sécurité et de traitement du RGPD.
Gestion et opérations
Déploiement
Cloud public, cloud privé, ou quelque part entre les deux. Quel que soit le cas de figure, nous vous facilitons l'exécution et la gestion de la Suite Elastic.
Téléchargement et installation
Pour se lancer, c'est toujours aussi simple : il vous suffit de télécharger et d'installer Elasticsearch et Kibana sous forme d'archive ou via un gestionnaire de package. Vous indexerez, analyserez et visualiserez vos données en un clin d'œil. Et avec la distribution par défaut, vous pouvez aussi essayer des fonctionnalités Platinum comme Machine Learning, Security, ou encore l'analyse de graphes – tout cela, gratuitement, pour une période de 30 jours.
Télécharger la Suite ElasticElastic Cloud
Elastic Cloud, notre famille d'offres SaaS en pleine expansion, facilite le déploiement, l'utilisation et le scaling des produits et des solutions Elastic dans le cloud. Sautez sur le tremplin d'Elastic Cloud pour mettre Elastic à profit pour vous avec fluidité, grâce à l'expérience Elasticsearch facile à utiliser, hébergée et gérée et aux solutions de recherche qui sortent du lot. Essayez un produit Elastic Cloud gratuitement pendant 14 jours, sans carte de crédit.
Lancez-vous dans Elastic CloudLancez-vous avec la version d'essai gratuite d'Elasticsearch Service
Elastic Cloud Enterprise
Avec Elastic Cloud Enterprise (ECE), provisionnez, gérez et monitorez Elasticsearch et Kibana depuis une seule et même console. Et ce, quelles que soient votre infrastructure ou la taille de votre déploiement. Vous vous demandez où exécuter Elasticsearch et Kibana ? Bonne nouvelle : vous avez l'embarras du choix. Matériel physique, environnement virtuel, cloud privé, zone privée au sein d'un cloud public, ou encore cloud public (Google, Azure ou AWS, pour ne citer que ceux-là). À vous de choisir votre infrastructure.
Essayez ECE gratuitement pendant 30 joursElastic Cloud sur Kubernetes
Basé sur le modèle Kubernetes Operator, Elastic Cloud sur Kubernetes (ECK) vient étendre les fonctionnalités d'orchestration de base de Kubernetes, qui deviennent compatibles avec la configuration et la gestion d'Elasticsearch et Kibana sur Kubernetes. Avec Elastic Cloud sur Kubernetes, l'exécution d'Elasticsearch sur Kubernetes et les processus de déploiement, de mise à niveau, d'instantanés, de montée en charge, de haute disponibilité, de sécurité… Tout cela gagne en simplicité.
Déployez avec Elastic Cloud sur KubernetesHelm Charts
Avec l'offre officielle Helm Charts Elasticsearch et Kibana, offrez-vous un déploiement en quelques minutes.
Découvrir l'offre officielle Helm Charts d'ElasticConteneurisation de Docker
Exécutez Elasticsearch et Kibana sur Docker avec les conteneurs officiels du hub Docker.
Exécuter la Suite Elastic sur DockerGestion et opérations
Clients
La Suite Elastic vous permet de travailler avec les données en employant la méthode qui vous convient le mieux. Grâce à ses API RESTful, ses clients de langage, ou encore ses DSL performants (sans oublier SQL), elle rime avec flexibilité et élargit le champ des possibles.
API REST
Elasticsearch vous fournit un API REST basé sur le langage JSON complet et puissant, vous pouvez l'utiliser pour interagir avec votre cluster.
Découvrir l'API RESTConsultez la santé, l'état et les statistiques de votre cluster, de votre nœud et de votre index.
Gérez les données et les métadonnées de votre cluster, de votre nœud et de votre index.
Réalisez une opération CRUD (créer, lire, mettre à jour et supprimer) et recherchez des opérations dans vos index.
Exécutez des opérations de recherche avancées comme la pagination, le tri, le filtrage, le script, les agrégations et bien d'autres.
Clients de langage
Elasticsearch utilise des API RESTful et JSON standards. Nous créons et maintenons également des clients dans de nombreux langages tels que Java, Python, .NET, SQL et PHP. Et, notre communauté en a ajouté encore plus. À l'image d'Elasticsearch, ils sont simples à utiliser, leur utilisation est naturelle, et ils vous offrent une foule de possibilités.
Explorer les clients linguistiques disponiblesConsole
Grâce à Console, l'un des outils de développement de Kibana, vous pouvez composer des requêtes et les envoyer vers Elasticsearch en employant une syntaxe de type cURL, et visualiser les réponses à vos requêtes.
Découvrir Console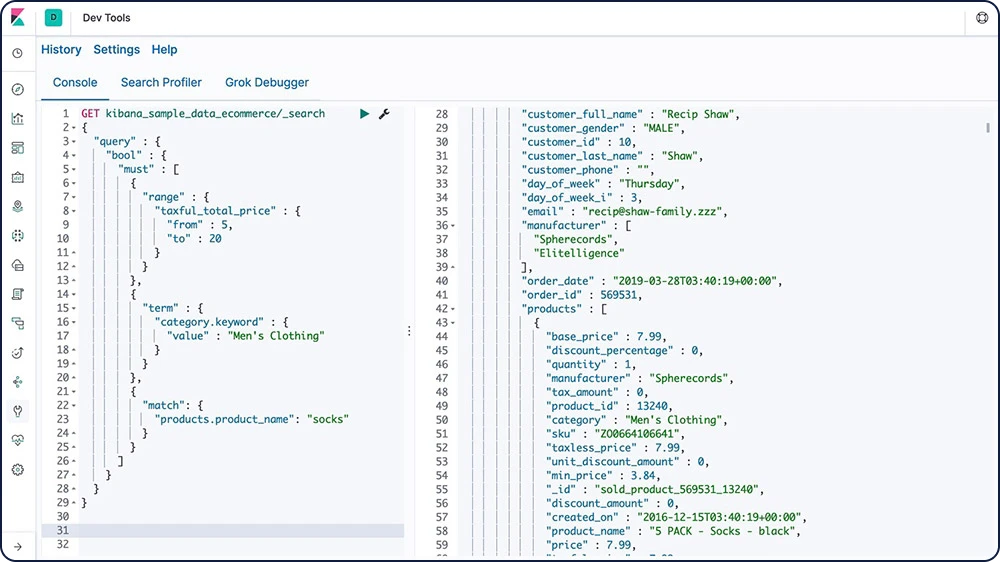
Elasticsearch DSL
Elasticsearch fournit un Query DSL complet (langage spécifique à un domaine) qui se base sur le langage JSON pour définir les requêtes. Query DSL met à disposition des options de recherche puissantes pour la recherche full-text, y compris la correspondance de termes et de phrases, la correspondance partielle, les caractères génériques, les requêtes géographiques, et bien plus encore.
Découvrir Elasticsearch DSLGET /fr/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL est une fonctionnalité qui permet d'exécuter les requêtes de type SQL en temps réel sur Elasticsearch. Tous les clients peuvent utiliser SQL pour rechercher et agréger des données nativement dans Elasticsearch, qu'il utilise l'interface REST, une ligne de commande ou JDBC.
Découvrir Elasticsearch SQL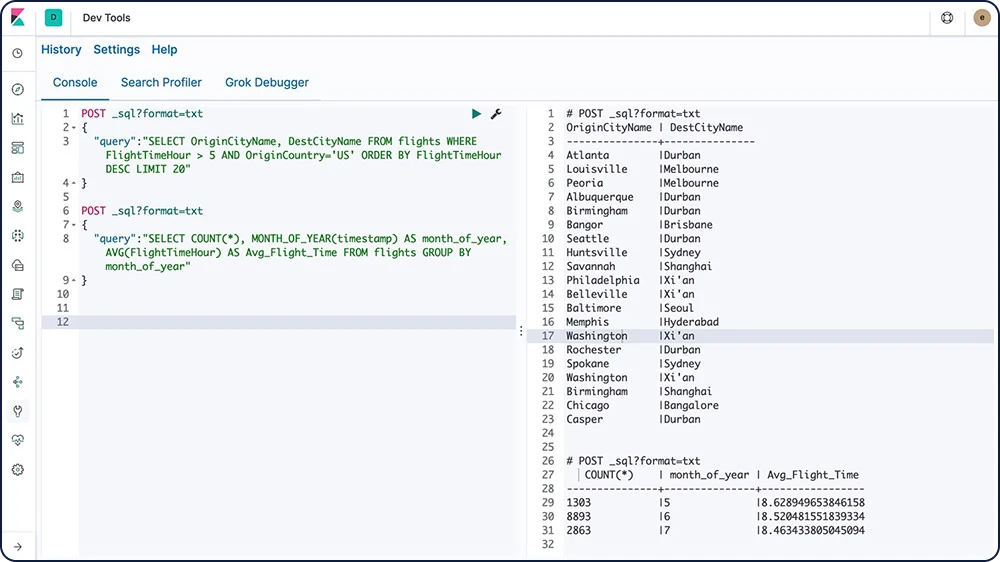
Event Query Language (EQL)
Grâce à sa capacité à interroger des séquences d'événements répondant à des conditions spécifiques, Event Query Language (EQL) convient parfaitement à des cas d'utilisation comme l'analyse de la sécurité.
Découvrir EQLClient JDBC
Le pilote JDBC Elasticsearch SQL est un pilote JDBC riche et ultracomplet pour Elasticsearch. Il s'agit d'un pilote de type 4, qui ne dépend donc pas d'une plateforme, fonctionne en autonomie, se connecte directement à la base de données et est écrit en Java. Il convertit les appels JDBC en Elasticsearch SQL.
Découvrir le client JDBCClient OBDC
Le pilote ODBC Elasticsearch SQL est un pilote ODBC 3.80 riche en fonctionnalités pour Elasticsearch. Il s'agit d'un pilote au niveau cœur qui expose toutes les fonctionnalités accessibles à travers l'API ODBC SQL d'Elasticsearch et qui convertit les appels ODBC en Elasticsearch SQL.
Découvrir le client ODBCConnecteur Tableau pour Elasticsearch
Le connecteur Tableau pour Elasticsearch facilite l'accès aux données dans Elasticsearch pour les utilisateurs de Tableau Desktop et Tableau Server.
Télécharger le connecteur TableauIngérer et enrichir
Ingérer et enrichir
Sources de données
Quel que soit le type de données que vous traitez, les agents Beats sont là pour les collecter. Déployés sur vos serveurs avec vos conteneurs ou comme fonctions, ils centralisent vos données dans Elasticsearch. Envie de monter en puissance de traitement ? Les agents Beats peuvent aussi transférer ces données vers Logstash, qui se charge de les transformer et de les analyser.
Systèmes d'exploitation
Collectez les données de votre framework d'audit Linux et monitorez l'intégrité de vos fichiers. Auditbeat transfère ces événements en temps réel vers la Suite Elastic en vue d'une analyse plus poussée.
Gardez un œil sur votre infrastructure Windows. Winlogbeat est un agent de transfert léger, qui diffuse en direct les logs d'événements Windows vers Elasticsearch et Logstash.
Découvrir WinlogbeatServeurs web et proxys
Filebeat et Metricbeat proposent plusieurs méthodes de monitoring pour vos serveurs Web et vos serveurs proxy, y compris les modules et les tableaux de bord préconfigurés de Nginx, Apache, HAProxy, IIS et plus.
Datastores et files d'attente
Filebeat et Metricbeat comprennent des modules internes qui simplifient la collecte, l'analyse et la visualisation des formats de log communs et des indicateurs système en provenance des datastores, des bases de données et des systèmes de file d'attente comme MySQL, MongoDB, PostgreSQL, Microsoft SQL, et plus.
Services cloud
Suivez les performances et la disponibilité d'un vaste éventail de services cloud fournis par Amazon Web Services, Google Cloud et Microsoft Azure à partir d'un point de surveillance unique afin d'obtenir des analyses efficaces à grande échelle. En outre, Functionbeat vous permet d'observer en toute simplicité votre architecture cloud sans serveur, notamment les logs CloudWatch, SQS et Kinesis.
Conteneurs et orchestration
Monitorez vos logs d'application, gardez un œil sur vos événements et indicateurs Kubernetes, et analysez la performance des conteneurs Docker. Lancez des recherches et affichez des visualisations via une application conçue pour les opérations d'infrastructure.
Avec la fonctionnalité Autodiscover de Metricbeat et Filebeat, plus aucun changement dans votre environnement ne vous échappe.
Automatisez l'ajout de modules et de chemins de logs, et adaptez dynamiquement vos paramètres de monitoring grâce aux hooks d'API Docker et Kubernetes.
Données réseau
Avec les informations réseau comme HTTP, DNS et SIP, vous gardez un œil sur les latences et les erreurs applicatives, les temps de réponse, la performance des SLA, les modèles et tendances associées aux accès utilisateurs, et plus encore. Exploitez ces données pour comprendre le trafic de votre réseau.
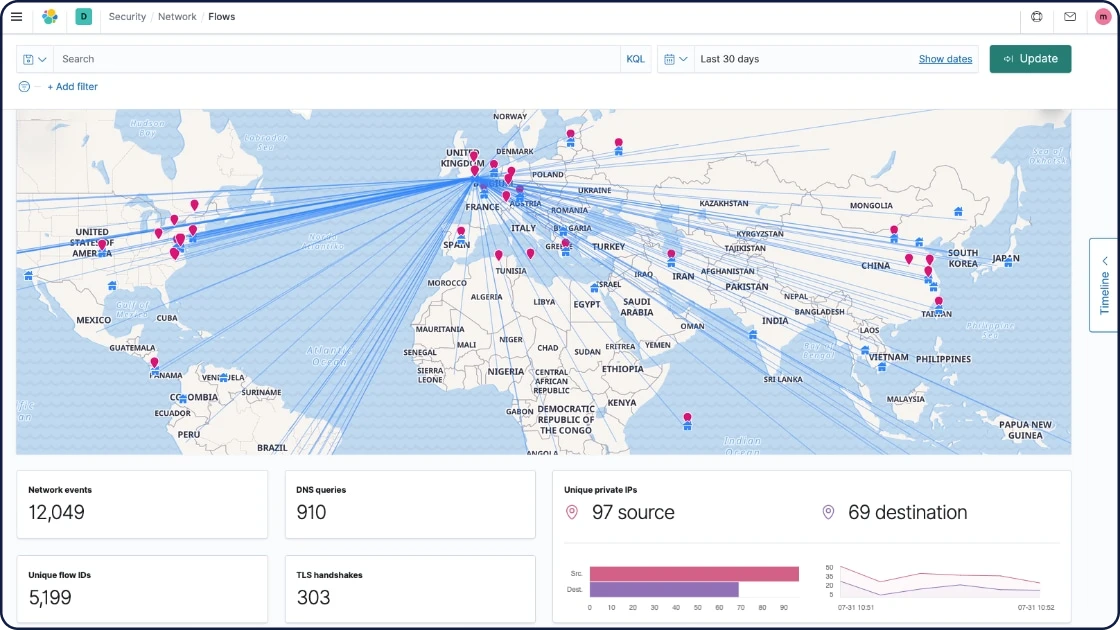
Données de sécurité
Les menaces peuvent venir de partout. C'est pourquoi il est si important de pouvoir observer ce qui se passe dans votre environnement en temps réel. Agent et Beats ingèrent une multitude de sources de données de sécurité, commerciales ou open source. Résultat : vous pouvez appliquer le monitoring et la détection à grande échelle.
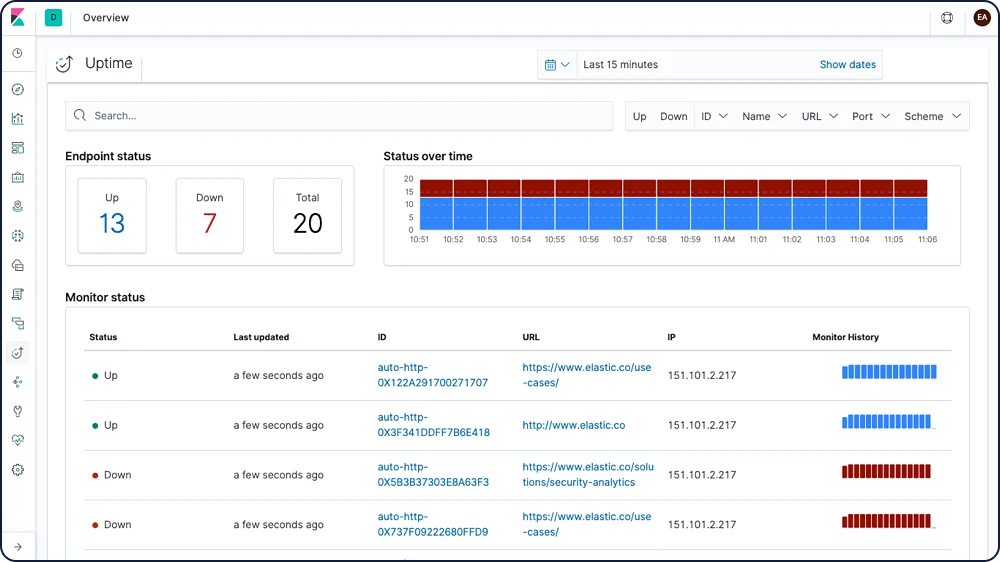
Données de disponibilité
Que vous testiez un service local ou sur le Web, Heartbeat vous permet de générer les données de disponibilité et de temps de réponse avec une facilité déconcertante.
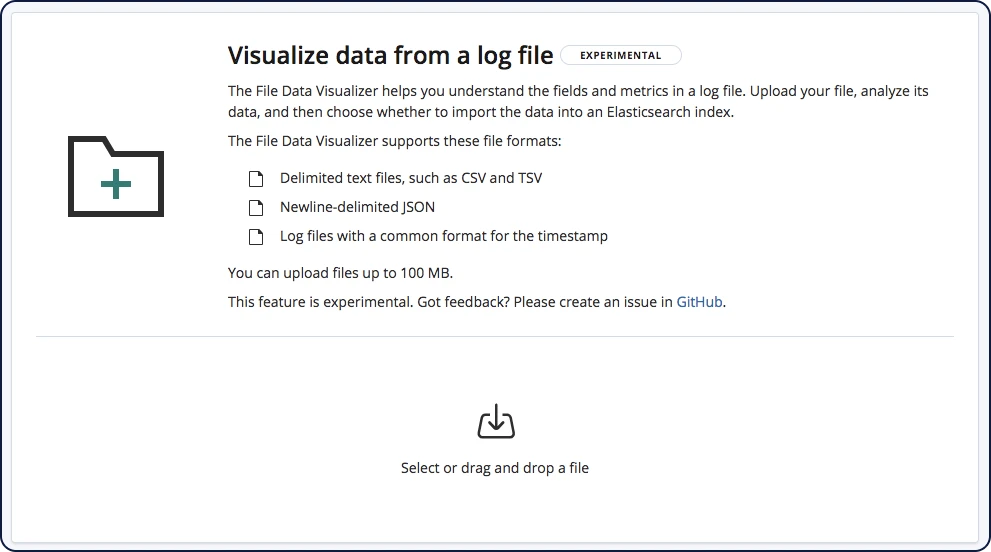
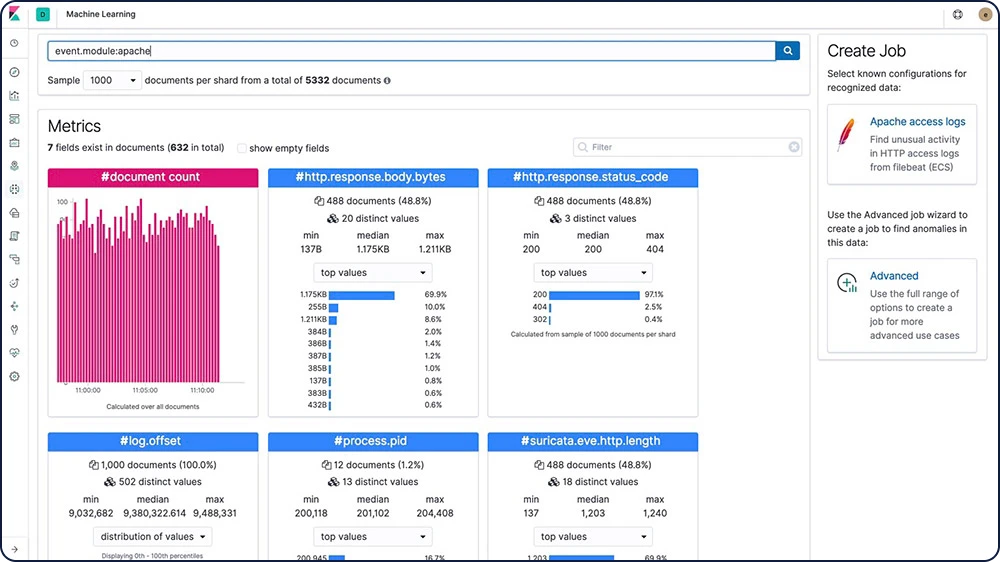
Importation de fichiers
Grâce à File Data Visualizer, vous pouvez charger un fichier CSV, NDJSON ou log dans un index Elasticsearch. File Data Visualizer utilise l'API de structure de fichier pour identifier le format du fichier et les mappings de champ. Vous pouvez ensuite choisir d'importer les données dans un index.
Ingérer et enrichir
Enrichissement des données
La Suite Elastic convertit les données brutes en précieuses informations grâce à des analyseurs, un générateur de tokens, des filtres et des options d'enrichissement au moment de l'indexation.
Processeurs
Utilisez un nœud d'ingestion pour pré-traiter les documents avant de réellement les indexer. Le nœud d'ingestion intercepte les groupes et indexe les requêtes, applique les transformations, puis renvoie les documents à l'index ou aux API Bulk. Le nœud d'ingestion comprend plus de 25 processeurs, y compris "append" (ajouter), "convert" (convertir), "date" (dater), "dissect" (disséquer), "drop" (abandonner), "fail" (échouer), "grok", "join" (joindre), "remove" (supprimer), "set" (définir), "split" (découper), "sort" (trier), "trim" (simplifier), et bien plus.
Analyseurs
L'analyse consiste en un processus de conversion du texte, comme le corps d'un e-mail, en tokens ou en termes qui sont ensuite ajoutés à un index inversé pour la recherche. Cette analyse est réalisée par un analyseur qui peut être intégré ou personnalisé et défini par index à l'aide d'une combinaison de générateurs de tokens et de filtres.
Exemple : analyseur standard (par défaut)
Entrée : "Les deux renards bruns RAPIDES sautent au-dessus de l'os du chien fainéant."
Sortie : les deux renards bruns rapides sautent au-dessus de l'os du chien fainéant
Générateur de tokens
Un générateur de tokens reçoit un flux de caractères, le divise en tokens (généralement en mots), et sort un flux de tokens. Le générateur de tokens se charge également de l'enregistrement de l'ordre ou de la position de chaque terme (utilisé pour les recherches de proximité de mots et de phrases) ainsi que des décalages de caractère de début et de fin du mot d'origine que le terme représente (utilisés pour mettre en évidence des extraits de recherche). Elasticsearch est doté de plusieurs générateurs de tokens intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Exemple : Générateur de tokens de caractères blancs
Entrée : "Les deux renards bruns RAPIDES sautent au-dessus de l'os du chien fainéant."
Sortie : The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filtres
Les filtres de tokens prennent en charge un flux de tokens en provenance d'un générateur de tokens et peuvent modifier les tokens (par exemple les mettre en minuscules), les supprimer (par exemple éliminer les mots non significatifs), ou en ajouter (par exemple des synonymes). Elasticsearch est doté de plusieurs filtres de tokens intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Vous pouvez utiliser les filtres de caractères pour prétraiter le flux de caractères avant qu'il passe dans le générateur de tokens. Un filtre de caractères reçoit le texte d'origine sous forme de flux de caractère et peut transformer le flux en ajoutant, en éliminant ou en modifiant des caractères. Elasticsearch est doté de plusieurs filtres de caractères intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Découvrir les filtres de caractèresAnalyseurs linguistiques
Effectuez des recherches dans votre langue. Elasticsearch propose plus de 30 analyseurs linguistiques différents, y compris plusieurs langues utilisant des caractères non latins comme le russe, l'arabe et le chinois.
Grok
Un modèle grok est similaire à une expression régulière qui prend en charge les alias d'expressions qui peuvent être réutilisés. Utilisez Grok pour extraire des champs structurés d'un champ textuel dans un document. Cet outil convient parfaitement pour les logs Syslog, les logs de serveur Web comme Apache, les logs MySQL et tous les formats de log qui sont généralement écrits pour les utilisateurs plutôt que pour les machines.
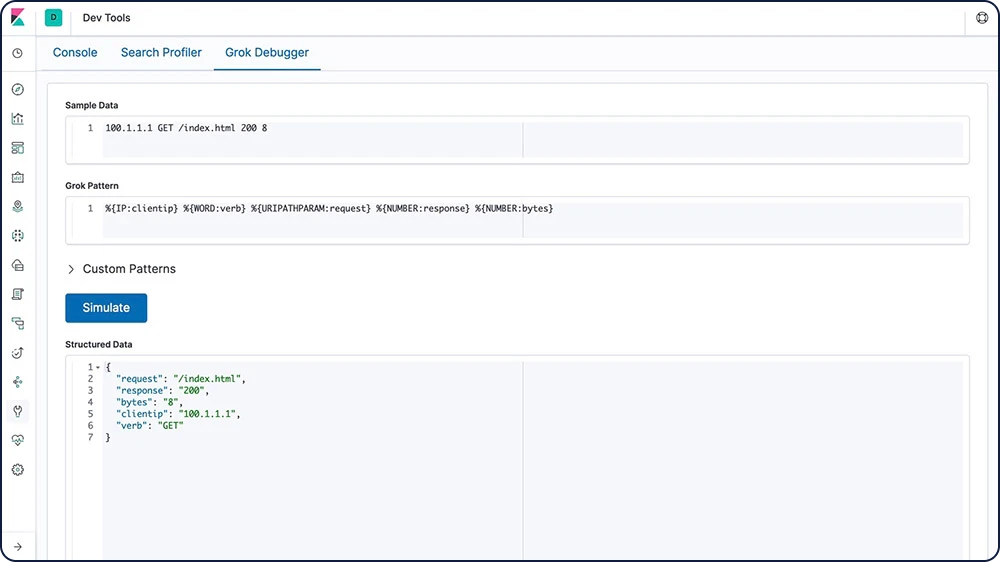
Transformation de champ
Si vous utilisez des flux de données, vous pouvez ajouter des scripts pour transformer vos données avant de les analyser. Les flux de données contiennent une propriété "script_fields" en option, qui vous permet de spécifier des scripts qui évaluent des expressions personnalisées et d'afficher les champs de script. Vous pouvez effectuer plusieurs types de transformations avec cette fonctionnalité.
Ajout de champs numériques
Concaténation, simplification et transformation des chaînes
Remplacement de tokens
Mise en correspondance et concaténation d'expressions régulières
Division des chaînes par nom de domaine
Transformation des données geo_point
Recherches externes
Enrichissez vos données de log au moment de l'ingestion avec les plug-ins de recherche externe de Logstash. Complétez facilement les lignes de log et donnez-leur plus de contexte avec des informations comme l'emplacement IP du client, les résultats de recherche DNS ou encore les données provenant de lignes de log adjacentes. Logstash est doté de plusieurs plug-ins de recherche parmi lesquels vous pouvez choisir.
Processeur d'enrichissement Match
Le processeur d'ingestion Match permet aux utilisateurs d'interroger leurs données au moment de l'ingestion et leur indique l'index depuis lequel ils peuvent extraire des données enrichies. Très utile pour les utilisateurs Beats qui doivent ajouter quelques éléments à leurs données : plutôt que de passer de Beats à Logstash, ils peuvent directement consulter le pipeline d'ingestion. Grâce au processeur, ils sont aussi en mesure de normaliser les données pour améliorer leurs analyses et traiter les requêtes courantes.
Processeur d'enrichissement Geo-match
Aussi utile que pratique, le processeur d'enrichissement Geo-match permet aux utilisateurs de booster leurs fonctionnalités de recherche et d'agrégation grâce à leurs données géographiques. Le tout, sans devoir définir de requêtes ou d'agrégations en termes de coordonnées géographiques. Comme avec le processeur d'enrichissement Match, les utilisateurs peuvent interroger leurs données au moment de l'ingestion et rechercher l'index optimal depuis lequel ils peuvent extraire des données enrichies.
Ingérer et enrichir
Modules et intégrations
Clients et API
Elasticsearch utilise des API RESTful et JSON standards. Nous créons et maintenons également des clients dans de nombreux langages tels que Java, Python, .NET, SQL et PHP. Et, notre communauté en a ajouté encore plus. À l'image d'Elasticsearch, ils sont simples à utiliser, leur utilisation est naturelle, et ils vous offrent une foule de possibilités.
Nœud d'ingestion
Elasticsearch propose plusieurs types de nœuds, et l'un d'eux sert spécifiquement à ingérer des données. Les nœuds d'ingestion peuvent exécuter des pipelines de prétraitement, qui se composent d'un processeur d'ingestion ou plus. En fonction du type d'opération réalisé par les processeurs d'ingestion et des ressources nécessaires, cela peut être utile de dédier des nœuds d'ingestion à la réalisation de cette tâche.
Elastic Agent
Elastic Agent est un agent unifié unique qui peut être déployé pour les hébergeurs ou conteneurs afin de collecter des données et de les envoyer à la Suite Elastic. Il vous permet d'ajouter le monitoring des logs, des indicateurs et d'autres types de données à chaque hébergeur. Les hébergeurs contrôlés par Elastic Agent exploitent Endpoint Security pour surveiller les événements de sécurité de l'hébergeur. L'étude des données de sécurité est rendue possible grâce à l'application Elastic Security disponible dans Kibana.
Beats
Les agents Beats sont des agents de transfert de données open source que vous pouvez installer sur vos serveurs pour envoyer des données opérationnelles à Elasticsearch ou Logstash. Elastic vous fournit des agents Beats qui permettent de capturer plusieurs types de logs communs, d'indicateurs et d'autres types de données.
Auditbeat pour les logs d'audit Linux
Filebeat pour les fichiers log
Functionbeat pour les données cloud
Heartbeat pour les données de disponibilité
Journalbeat pour les journaux systemd
Metricbeat pour les indicateurs d'infrastructure
Packetbeat pour le trafic réseau
Winlogbeat pour l'analyse des logs d'événements Windows
Agents de transfert communautaires
Si vous avez besoin de résoudre un cas d'utilisation spécifique, nous vous encourageons à créer un agent Beat communautaire. Nous avons créé une infrastructure pour simplifier le processus. La bibliothèque libbeat, écrite entièrement en Go, propose l'API que tous les agents Beats utilisent pour transférer des données vers Elasticsearch, configurer les options d'entrée, implémenter des loggings, et plus.
Avec plus de 100 agents Beats partagés par la communauté, il existe des agents pour les logs et les indicateurs de Cloudwatch, les activités de GitHub, les sujets Kafka, MySQL, MongoDB Prometheus, Apache, Twitter, et bien plus encore.
Consulter les agents Beats disponibles développés par la communautéLogstash
Logstash est un moteur de collecte de données open source doté de capacités pipeline en temps réel. Logstash peut rassembler de manière dynamique les données provenant de plusieurs sources et les normaliser vers les destinations de votre choix. Nettoyez et démocratisez toutes vos données pour plusieurs cas d'utilisation d'analytique et de visualisation en aval.
Plug-ins Logstash
Vous pouvez ajouter vos propres plug-ins d'entrée, codec, de filtre ou de sortie à Logstash. Vous pouvez développer et déployer ces plug-ins indépendamment du cœur de Logstash. Vous pouvez également écrire votre propre plug-in Java et l'utiliser dans Logstash.
Elasticsearch-Hadoop
Elasticsearch pour Apache Hadoop (Elasticsearch-Hadoop ou ES-Hadoop) est une petite bibliothèque gratuite, ouverte, indépendante et auto-contenue qui permet aux tâches Hadoop d'interagir avec Elasticsearch. Utilisez-la pour développer des applications de recherche intégrées et dynamiques pour traiter vos données Hadoop ou lancer des analyses complexes à faible latence, s'appuyant sur des agrégations, des requêtes full-text ou des requêtes géospatiales.
Plug-ins et intégrations
Elasticsearch étant une application gratuite et ouverte compatible avec tous les langages, vous pouvez facilement étendre ses fonctionnalités avec des plug-ins et des intégrations. Grâce aux plug-ins, vous avez une façon personnalisée d'améliorer les fonctionnalités principales d'Elasticsearch. Les intégrations sont des outils externes ou des modules qui facilitent le travail avec Elasticsearch.
Plug-ins d'extension d'API
Plug-ins Alerting
Plug-ins d'analyse
Plug-ins de découverte
Plug-ins d'ingestion
Plug-ins de gestion
Plug-ins Mapper
Plug-ins de sécurité
Plug-ins de référentiel d'instantané/de restauration
Plug-ins de stockage
Ingérer et enrichir
Gestion
Gérez vos méthodes d'ingestion depuis des emplacements centralisés dans Kibana.
Fleet
Fleet permet de profiter d'une interface utilisateur sur le web dans Kibana pour l'ajout et la gestion des intégrations de services et plateformes populaires, ainsi que de la gestion d'une flotte d'agents Elastic. Nos intégrations permettent d'ajouter facilement des sources de données, et sont de plus livrées avec des ressources prêtes à l'emploi, comme des tableaux de bord, des visualisations et des pipelines conçus pour extraire des champs structurés à partir des logs.
Gestion centralisée du pipeline Logstash
Contrôlez plusieurs instances Logstash à partir de l'interface utilisateur de gestion de pipeline dans Kibana. Du côté de Logstash, activez simplement la gestion de la configuration et paramétrez Logstash pour qu'il utilise les configurations de pipeline gérées de manière centrale.
Stockage de données
Stockage de données
Flexibilité
La Suite Elastic est une solution ultraperformante, capable de répondre à quasiment tous les cas d'utilisation. Bien qu'elle soit surtout connue pour ses capacités de recherche avancée, sa conception flexible en fait un outil parfaitement adapté à différents besoins, comme le stockage de documents, l'analyse de séries temporelles et d'indicateurs, ou encore l'analyse géospatiale.
Types de données
Elasticsearch est compatible avec différents types de données pour les champs d'un document, et chacun de ces types de données présente plusieurs sous-types. Cela vous permet de stocker, d'analyser et d'utiliser vos données avec une efficacité et une efficience maximales, peu importe leur type. Voici quelques exemples de types de données pour lesquels Elasticsearch est optimisé :
Texte
Formes
Nombres
Vecteurs
Histogramme
Séries date/heure
Champ "flattened" (lissé)
Points géographiques/formes géométriques
Données non structurées (JSON)
Données structurées
Recherche full-text (index inversé)
Elasticsearch utilise une structure appelée index inversé et conçue pour faire des recherches full-text très rapides. Un index inversé se compose d'une liste des mots uniques qui apparaissent dans un document. Pour chaque mot, cet index comprend une liste de tous les documents dans lesquels il apparaît. Pour créer un index inversé, il faut tout d'abord diviser le champ de contenu de chaque document en mots séparés (qu'on appelle termes ou tokens), puis créer une liste triée de tous les termes uniques, et enfin lister dans quels documents chaque terme apparaît.
Stockage de documents (données non structurées)
Avec Elasticsearch, les données ne doivent pas obligatoirement être structurées pour être ingérées ou analysées (bien que la structuration améliore la vitesse). Cette conception facilite le lancement et fait aussi d'Elasticsearch un espace de stockage de documents efficace. Même si Elasticsearch n'est pas une base de données NoSQL, il propose des fonctionnalités similaires.
Séries temporelles/analyse (structure en colonnes)
Un index inversé permet aux recherches de rapidement trouver des termes de recherche. Cependant, le tri et les agrégations requièrent un autre modèle d'accès aux données. Au lieu de rechercher le terme et de trouver des documents, elles doivent pouvoir rechercher le document et trouver les termes qu'il contient dans un champ. Les valeurs des documents sont la structure de données sur disque dans Elasticsearch. Elles sont créées au moment de l'indexation du document, ce qui signifie que ce modèle d'accès aux données est possible, et permet de faire des recherches en colonnes. Grâce à cela, Elasticsearch excelle dans l'analyse des indicateurs et des séries temporelles.
Données géospatiales (arborescence BKD)
Elasticsearch utilise l'arborescence BKD dans Lucene pour stocker les données géospatiales. Cela permet d'analyser de manière efficace les points géographiques (latitude et longitude) et les formes géométriques (rectangles et polygones).
Stockage de données
Sécurité
Elasticsearch est compatible avec différentes méthodes qui permettent de veiller à ce que vos données ne tombent pas entre de mauvaises mains.
Prise en charge du chiffrement des données au repos
Bien que la Suite Elastic ne mette pas en place le chiffrement au repos de base, nous vous recommandons de configurer un chiffrement au niveau du disque dur sur l'ensemble des machines hôtes. De plus, les cibles instantanées doivent aussi assurer le chiffrement des données au repos.
Sécurité des API au niveau des champs et des documents
La sécurité au niveau des champs restreint les champs auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
La sécurité au niveau des documents restreint les documents auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau des documentsStockage de données
Gestion
Elasticsearch vous permet de gérer entièrement vos clusters et leurs nœuds, vos index et leurs partitions, sans oublier l'essentiel : l'intégralité des données qu'ils contiennent.
Index groupés
Un cluster est un ensemble constitué d'un ou de plusieurs nœuds (serveurs). Il stocke toutes vos données et vous permet de centraliser l'indexation et la recherche des données sur l'ensemble des nœuds. Son architecture facilite le scaling horizontal. Elasticsearch intègre une API REST complète et performante, ainsi que des interfaces utilisateur, qui vous permettent d'interagir avec vos clusters.
Snapshot et restauration des données
Un instantané est une sauvegarde d'un cluster Elasticsearch en cours d'exécution. Vous pouvez créer un snapshot soit d'index individuels, soit de tout le cluster, et stocker ce snapshot dans un référentiel dans un système de fichier partagé. Des plug-ins qui prennent également en charge les référentiels distants sont disponibles.
Snapshots de source
Un référentiel de source vous permet de créer des instantanés minimaux de la source, qui occupent jusqu'à 50 % d'espace disque. Les snapshots de source contiennent les champs stockés et les métadonnées d'index. Ils ne comprennent pas les structures de valeurs des index ou des documents et on ne peut pas y faire des recherches lorsqu'on les restaure.
Index de cumul
Conserver les données historiques pour les analyser est extrêmement utile, mais il s'agit de quelque chose qu'on évite souvent en raison du coût financier associé à l'archivage de quantités astronomiques de données. Par conséquent, les périodes de conservation sont influencées par les réalités financières plutôt que par l'utilité d'avoir à disposition une quantité importante de données historiques. La fonctionnalité de cumul vous donne le moyen de résumer et stocker les données historiques pour pouvoir les analyser, mais pour seulement une fraction du coût de stockage des données brutes.
Rechercher et analyser
Rechercher et analyser
Recherche full-text
Elasticsearch est connu pour ses puissantes capacités de recherche full-text. Sa rapidité ? Il la doit à l'index inversé intégré au cœur du moteur de recherche. Sa puissance ? Il la tire de son score de pertinence ajustable, de son Query DSL avancé et d'une pléthore de fonctions qui vous permettent de booster la recherche.
Index inversé
Elasticsearch utilise une structure appelée index inversé et conçue pour faire des recherches full-text très rapides. Un index inversé se compose d'une liste des mots uniques qui apparaissent dans un document. Pour chaque mot, cet index comprend une liste de tous les documents dans lesquels il apparaît. Pour créer un index inversé, il faut tout d'abord diviser le champ de contenu de chaque document en mots séparés (qu'on appelle termes ou tokens), puis créer une liste triée de tous les termes uniques, et enfin lister dans quels documents chaque terme apparaît.
Champs d'exécution
Les champs d'exécution sont des champs évalués au moment de la requête (schéma de lecture). Ils peuvent être ajoutés ou modifiés à tout moment, y compris après l'indexation des documents, et peuvent être définis dans une requête. Les champs d'exécution sont affectés par les requêtes dans la même interface que celle des champs indexés. Un champ peut donc être un champ d'exécution dans certains indices d'un flux de données, et un champ indexé dans d'autres indices de ce flux de données, sans que les requêtes ne puissent faire la différence. Bien que les performances des requêtes soient déjà optimales pour les champs indexés, les champs d'exécution ne sont pas en reste en permettant la modification flexible de la structure de données une fois les documents indexés.
Champ d'exécution de recherche
Les champs d'exécution de recherche vous offrent la possibilité d'ajouter des informations depuis un index de recherche dans les résultats et depuis un index principal en définissant une clé sur les deux index qui lient les documents. Comme les champs d'exécution, cette fonctionnalité est utilisée au moment de la recherche pour assurer un enrichissement flexible des données.
Recherche inter-clusters
La fonctionnalité de recherche inter-clusters (CCS) permet à n'importe quel nœud de se comporter comme un client fédéré sur plusieurs clusters. Un nœud de recherche inter-cluster ne contacte pas le cluster distant. Il se connecte plutôt à un cluster distant de manière légère pour exécuter des recherches fédérées.
Score de pertinence
Une fonction de similarité (score de pertinence/modèle de classement) définit comment les documents correspondants sont notés. Par défaut, Elasticsearch utilise la similarité BM25, une similarité TF/IDF avancée qui est dotée d'une normalisation tf intégrée qui convient parfaitement pour les champs courts (comme les noms). Plusieurs autres options de similarité sont disponibles.
Recherche vectorielle (ANN)
Grâce à la nouvelle prise en charge de la recherche approximative du plus proche voisin ou ANN de Lucene 9 fondée sur l'algorithme HNSW, le nouveau point de terminaison de l'API _knn_search permet de mener des recherches plus performantes et scalables en fonction de la similarité vectorielle. Pour ce faire, un équilibre est trouvé entre rappel et performance : grâce à des compromis mineurs en matière de rappel, les très grands ensembles de données deviennent bien plus performants (par rapport à la méthode existante de similarité vectorielle par force brute).
Query DSL
La recherche full-text requiert un langage de requête robuste. Elasticsearch fournit un Query DSL complet (langage spécifique à un domaine) qui se base sur le langage JSON pour définir les requêtes. Créez des requêtes simples pour faire correspondre des termes et des phrases, ou développez des requêtes composées qui peuvent combiner plusieurs requêtes. De plus, vous pouvez appliquer des filtres au moment de la requête pour éliminer des documents avant de leur attribuer des notes de pertinence.
Recherche asynchrone
L'API de recherche asynchrone vous permet d'exécuter en arrière-plan les requêtes qui prennent du temps. Vous pouvez en surveiller la progression et récupérer des résultats partiels à mesure qu'ils sont disponibles.
Surligneurs
Les surligneurs vous permettent de mettre en évidence des extraits d'un ou plusieurs champs dans vos résultats de recherche pour pouvoir montrer aux utilisateurs où se trouvent les correspondances de recherche. Lorsque vous demandez l'affichage des surlignages, la réponse contient un élément de surlignage supplémentaire pour chaque résultat de recherche comprenant les champs surlignés et les fragments surlignés.
Saisie semi-automatique (complétion automatique)
L'outil de suggestion de saisie semi-automatique vous fournit une fonctionnalité de complétion automatique/de recherche en cours de frappe. Il s'agit d'une fonctionnalité de navigation qui guide les utilisateurs vers des résultats pertinents en cours de frappe, ce qui améliore la précision de recherche.
Corrections (correcteur orthographique)
L'outil de suggestion de termes est à la racine du correcteur orthographique. Il suggère des termes en fonction de la distance d'édition. Le texte de suggestion fourni est analysé avant de suggérer des termes. Les termes suggérés sont fournis par tokens textuels de suggestion analysés.
Outil de suggestion (did-you-mean)
L'outil de suggestion de phrase ajoute une fonctionnalité did-you-mean à votre recherche en bâtissant une logique supplémentaire par-dessus l'outil de suggestion de terme pour sélectionner des phrases corrigées entières au lieu de tokens individuels pondérés sur la base de modèles de langage ngram. En pratique, cet outil de suggestion est capable de prendre de meilleures décisions quant aux tokens à sélectionner en fonction des co-occurrences et des fréquences.
Filtres
Les filtres retournent le modèle de recherche standard, où on utilise une recherche pour trouver un document stocké dans un index, et peuvent être utilisés pour faire correspondre des documents à des recherches stockées dans un index. La recherche de filtre en elle-même contient le document qui est utilisé comme recherche pour être associée aux recherches stockées.
Système de profilage/d'optimisation des requêtes
L'API de profilage fournit des informations de temporisation détaillées à propos de l'exécution de composants individuels dans une requête de recherche. Il permet de mieux comprendre comment les requêtes de recherche s'exécutent à bas niveau pour que vous puissiez comprendre pourquoi certaines requêtes sont lentes et prendre des mesures pour les améliorer.
Résultats de recherche en fonction des autorisations
La sécurité au niveau des champs et la sécurité au niveau des documents restreint les résultats de recherche à ce à quoi les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs et les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Annulation de requête
La fonctionnalité d'annulation de requête intégrée à Kibana s'avère très pratique lorsqu'il s'agit de réduire la charge de travail inutile pour limiter l'impact global imposé au cluster. L'annulation automatique de requêtes Elasticsearch a lieu lorsque les utilisateurs modifient ou mettent à jour leur recherche, ou qu'ils actualisent la page du navigateur.
Rechercher et analyser
Analytique
La recherche des données n'est que le début. Les puissantes fonctionnalités d'analyse de la Suite Elastic vous permettent de découvrir ce que veulent vraiment dire les données que vous avez recherchées et collectées. Que l'on parle de l'agrégation de résultats, de la découverte de relations entre des documents ou de la création d'alertes selon des valeurs de seuil, tout s'appuie sur une fonction de recherche performante.
Agrégations
L'architecture d'agrégations vous aide à obtenir des données agrégées à l'aide d'une requête de recherche. Il est adossé à de simples composantes de base appelées agrégations, que vous pouvez exploiter pour créer des résumés complexes de vos données. On peut voir une agrégation comme une unité de travail qui construit des informations analytiques à partir d'un ensemble de documents.
Agrégations d'indicateurs
Agrégations d'intervalles
Agrégations de pipelines
Agrégations de matrices
Agrégations de grilles hexagonales géométriques
Agrégations d'échantillonnage aléatoire
Exploration de graphes
L'API d'exploration Graph vous permet d'extraire et de résumer des informations à propos des documents et des termes qui se trouvent dans votre index Elasticsearch. La meilleure façon de comprendre le comportement de cette API est d'utiliser Graph dans Kibana pour explorer les relations.
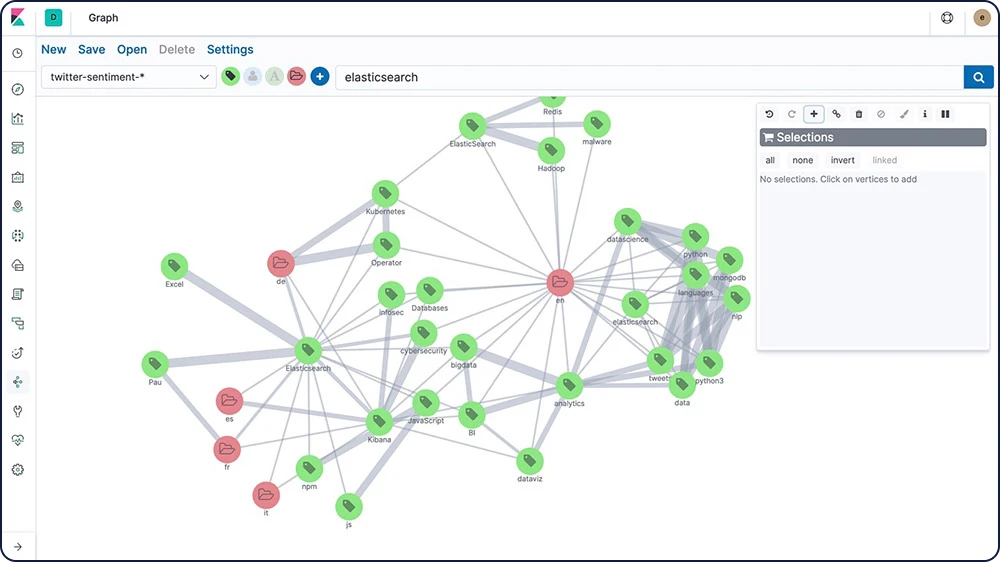
Alertes de seuil
Créez des alertes de seuil pour vérifier de manière périodique quand les données de vos index Elasticsearch passent au-dessus ou en dessous d'un certain seuil pendant une période donnée. Avec Alerting, toute la puissance du langage de requête d'Elasticsearch est entre vos mains : vous pouvez ainsi identifier les modifications apportées aux données qui vous intéressent.
Rechercher et analyser
Machine Learning
Les fonctionnalités Machine Learning d'Elastic modélisent automatiquement le comportement de vos données Elasticsearch (tendances, périodicité, etc.). Le tout, en temps réel. Leur mission : identifier les problèmes plus rapidement, rationaliser l'analyse de la cause première et réduire le nombre de faux positifs.
Inférence
L'inférence vous permet d'utiliser des processus de Machine Learning supervisé, comme la régression ou la classification, pour réaliser notamment des analyses par lot. Vous pouvez aussi utiliser ces processus de manière continue. Avec l'inférence, il est possible d'appliquer des modèles entraînés de Machine Learning sur les données entrantes.
Détection de la langue
La détection de la langue est un modèle entraîné dont vous pouvez vous servir pour déterminer la langue d'un texte. Vous pouvez référencer le modèle de détection de la langue dans un processeur d'inférence.
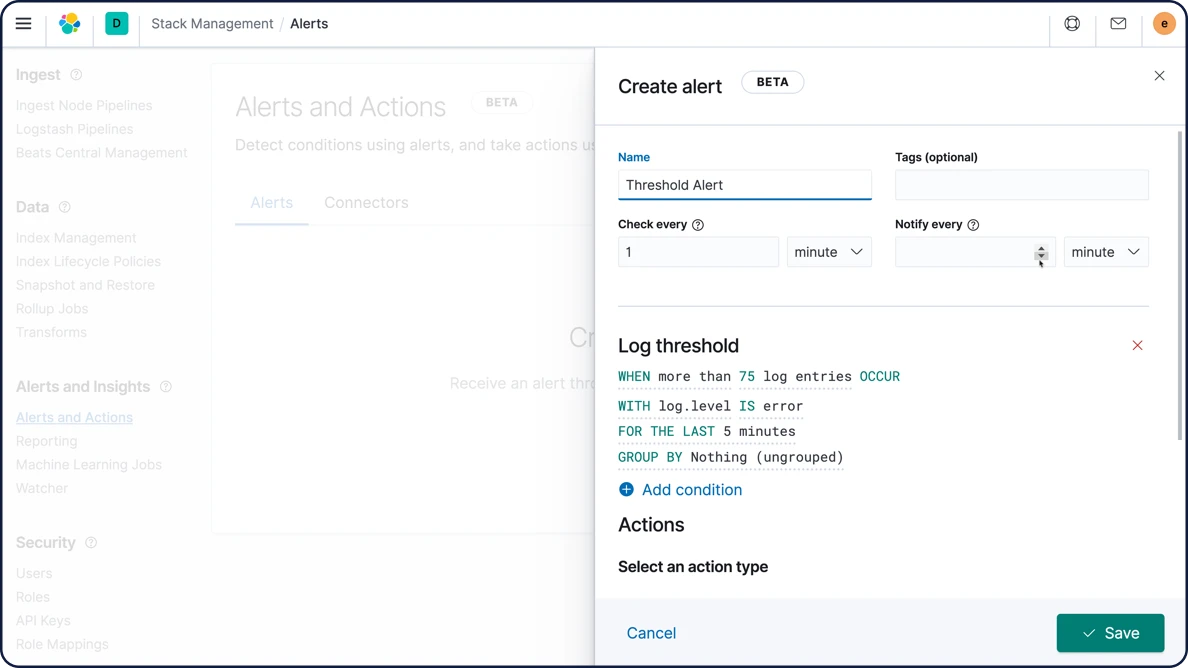
Prévisions relatives aux séries temporelles
Une fois que la fonctionnalité de Machine Learning d'Elastic a créé des points de comparaison de comportements normaux pour vos données, vous pouvez utiliser ces informations pour extrapoler les comportements futurs. Créez ensuite une prévision afin d'estimer une valeur temporelle à une date future spécifique ou pour estimer la probabilité d'occurrence d'une valeur temporelle dans le futur
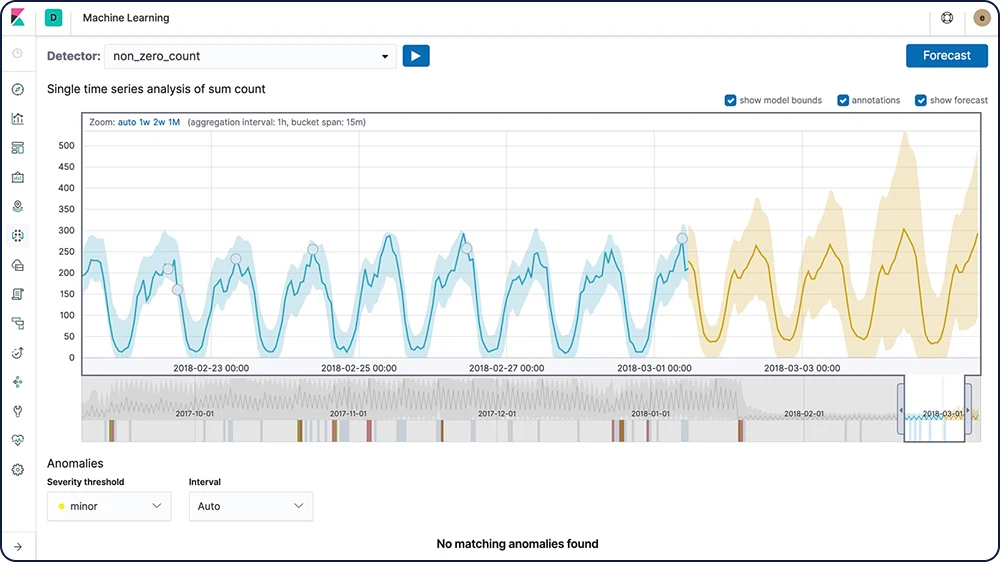
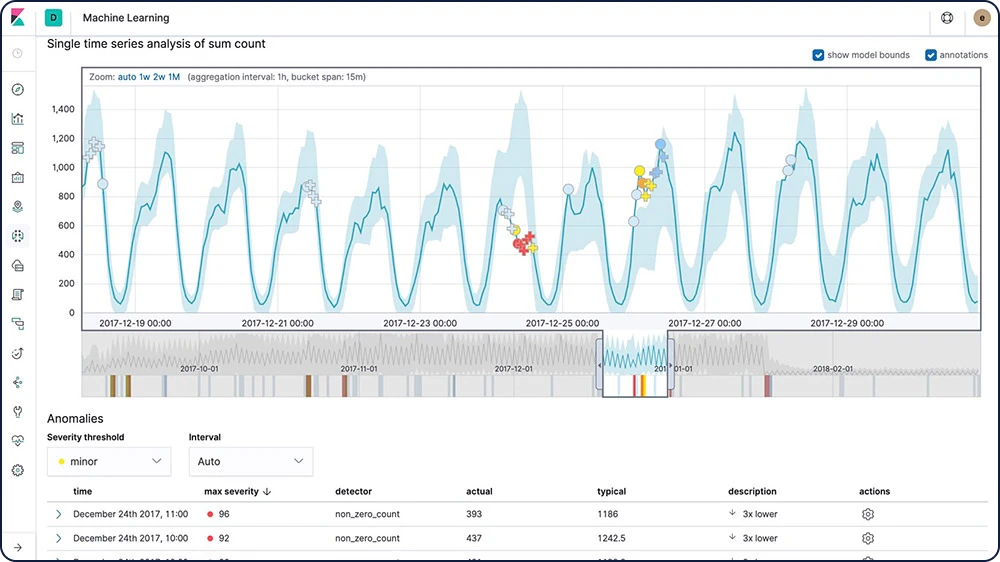
Détection des anomalies dans les séries temporelles
Les fonctionnalités de Machine Learning d'Elastic automatisent l'analyse des données temporelles en créant des points de comparaison précis de comportements normaux dans les données et en identifiant les modèles anormaux dans celles-ci. Les anomalies sont détectées, notées et liées à des influenceurs importants du point de vue statistique dans les données à l'aide d'algorithmes de Machine Learning propriétaires.
Les anomalies liées aux écarts temporels de valeurs, de nombres ou de fréquences
Rareté statistique
Les comportements inhabituels pour le membre d'une population
Alerting associé aux anomalies
Certaines modifications sont difficiles à définir au moyen de règles et de seuils. Dans ce cas, vous pouvez associer l'alerting à des fonctionnalités de Machine Learning non supervisé qui vous permettront de détecter les comportements inhabituels. Ensuite, vous pouvez aussi recevoir des notifications en fonction des scores d'anomalies et lorsque des problèmes surviennent.
Analyse de la population et de l'entité
Utilisez les fonctionnalités de Machine Learning d'Elastic pour créer un profil de ce qu'un utilisateur "type", une machine ou une autre entité réalise pendant une période donnée, puis pour identifier les anomalies où ils se comportent de manière anormale par rapport à la population.
Catégorisation des messages de log
Les événements log d'application ne sont souvent pas structurés et contiennent des données variables. Les fonctionnalités de Machine Learning d'Elastic observent la partie statique du message, regroupent les messages similaires et les classifient en catégories de messages.
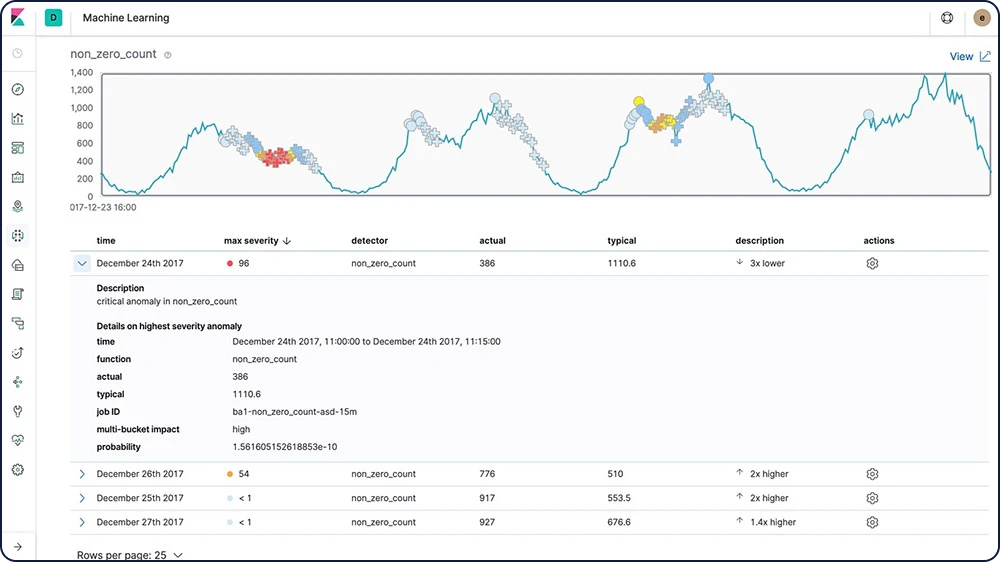
Indication de la cause première
Une fois une anomalie détectée, les fonctionnalités Elastic Machine Learning facilitent l'identification des propriétés qui ont contribué à son apparition. Par exemple, en cas de baisse inhabituelle des transactions, vous pouvez rapidement identifier le serveur défaillant ou le commutateur mal configuré qui sont à l'origine du problème.
File Data Visualizer
File Data Visualizer vous aide à mieux comprendre vos données Elasticsearch et à identifier les champs potentiels d'analyse Machine Learning en analysant les indicateurs et les champs dans un fichier de log ou dans un index existant.
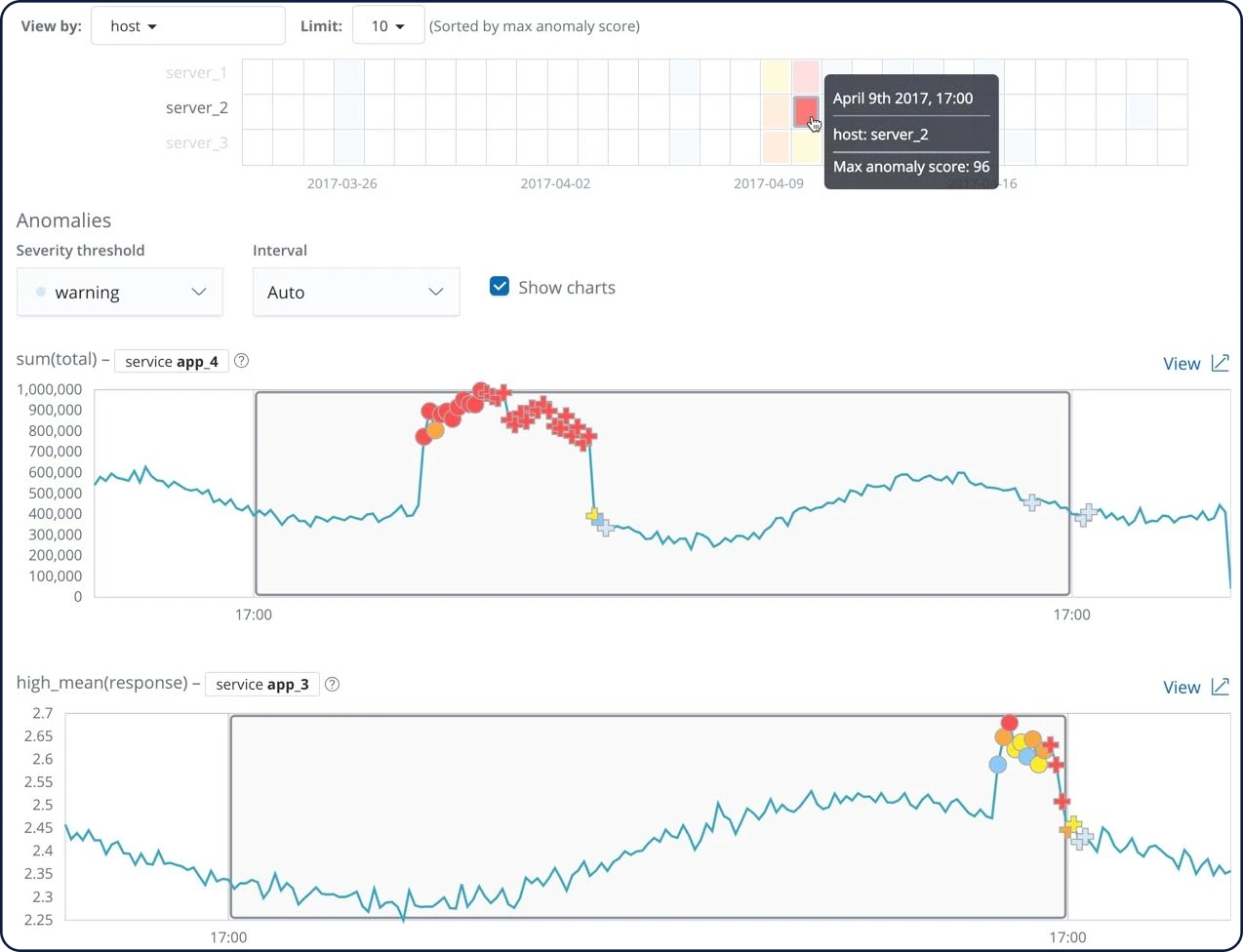
Explorateur d'anomalies à plusieurs indicateurs
Créez des tâches de Machine Learning complexes avec plusieurs détecteurs. Utilisez l'explorateur d'anomalies pour afficher les résultats après qu'une tâche à plusieurs indicateurs ait analysé le flux d'entrée de données, modélisé son comportement et effectué une analyse en fonction des deux détecteurs que vous avez définis dans votre tâche.
API de détection des aberrations
La détection non supervisée des aberrations s'appuie sur quatre méthodes de machine learning basées sur la distance et la densité, qui lui permettent de découvrir des points de données inhabituels par rapport à la majorité. Pour créer des tâches d'analyse des trames de données pour la détection d'aberrations, utilisez l'API "Create data frame analytics jobs".
Gestion des snapshots
Restaurez rapidement un modèle sur le snapshot souhaité en cas de panne système imprévue ou tout autre événement en échec lors de la détection des anomalies.
Rechercher et analyser
Elastic APM
Vous hébergez déjà des logs et des indicateurs système dans Elasticsearch ? Allez plus loin grâce aux indicateurs de performance applicative d'Elastic APM. Quatre lignes de code et le tour est joué : vous avez une vue d'ensemble qui vous permet de corriger rapidement les erreurs. Et vous vous sentez plus confiant vis-à-vis du code que vous déployez.
Serveur APM
Le serveur APM reçoit des données provenant d'agents APM et les transforme en documents Elasticsearch. Pour cela, il expose un point de terminaison de serveur HTTP vers lequel les agents diffusent les données APM qu'ils ont collectées. Une fois que le serveur APM a validé et traité les événements des agents APM, il transforme les données en documents Elasticsearch et les stocke dans des index Elasticsearch correspondants.
Agents APM
Les agents APM sont des bibliothèques open source qui sont écrites dans le même langage que votre service. Vous pouvez les installer dans votre service de la même manière que vous installeriez n'importe quelle autre bibliothèque. Ils instrumentalisent votre code et collectent des données et des erreurs de performance au moment de l'exécution. Ces données sont mises en mémoire tampon pendant une courte période puis envoyées sur le serveur APM.
Application APM
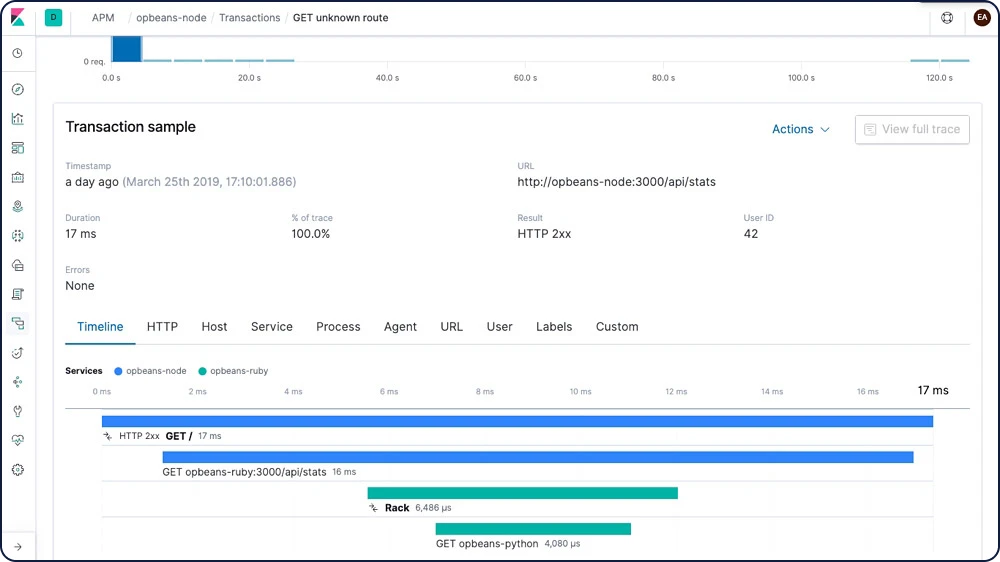
Trouver et résoudre des problèmes dans votre code, c'est en fait de la recherche. Avec notre application APM dédiée dans Kibana, vous identifiez d'un coup d'œil les goulets d'étranglement et pouvez agir directement sur les changements problématiques au niveau du code. Résultat : le code gagne en qualité et en efficacité, vous accélérez le cycle développement-test-déploiement, et les applications sont plus performantes – ce qui débouche au final sur une meilleure expérience client.
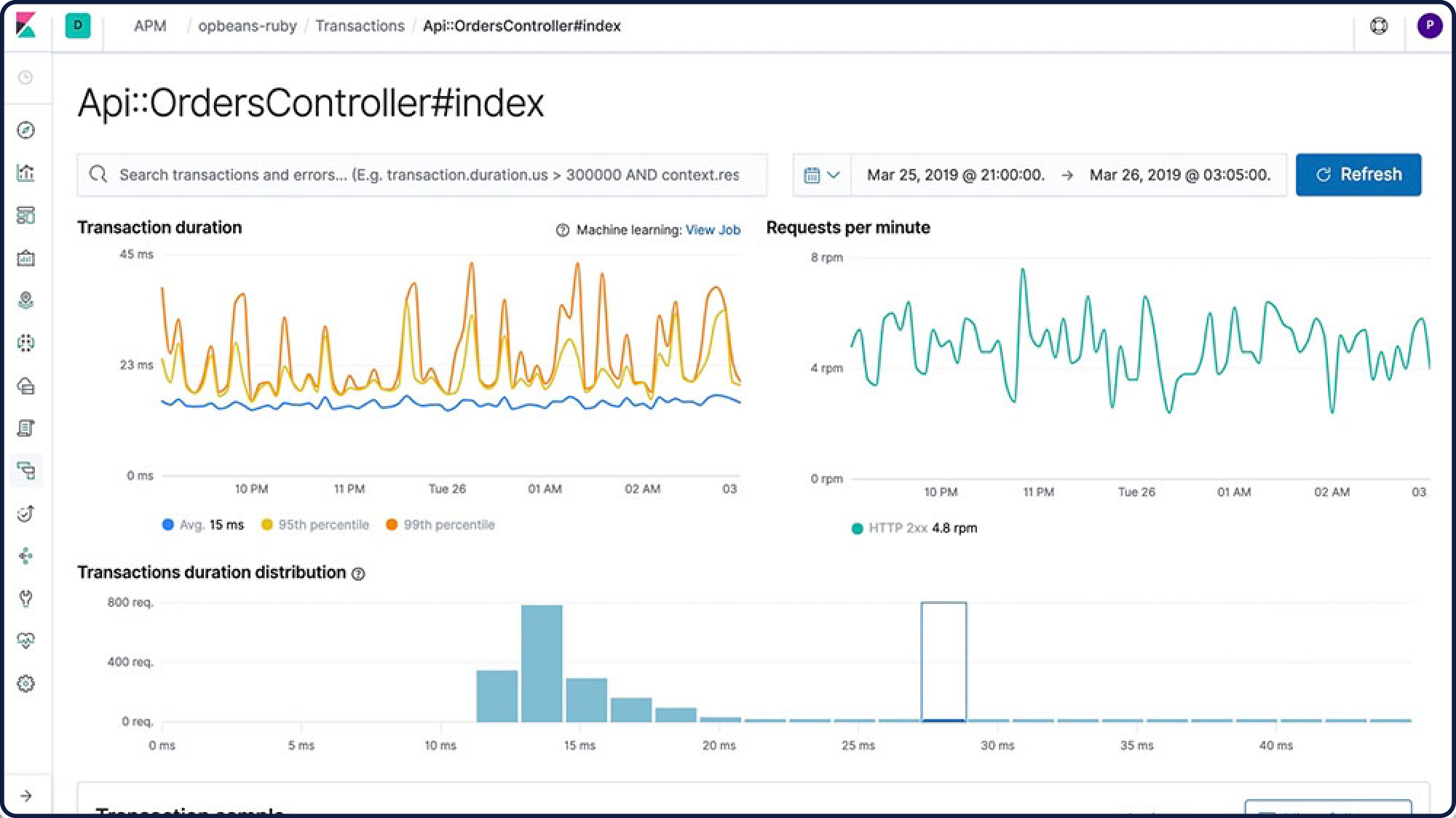
Traçage distribué
Vous vous demandez comment vos requêtes circulent dans votre infrastructure ? Assemblez les transactions entre elles grâce au traçage distribué et visualisez les interactions entre vos services. Détectez le point où se produisent les problèmes de latence et localisez précisément les composants à optimiser.
Intégration de l'alerting (alerte/signaler/aviser)
Restez toujours informé des performances de votre code. Recevez une notification par e-mail dès qu'un problème se produit, ou une notification Slack lorsque tout se passe vraiment très bien.
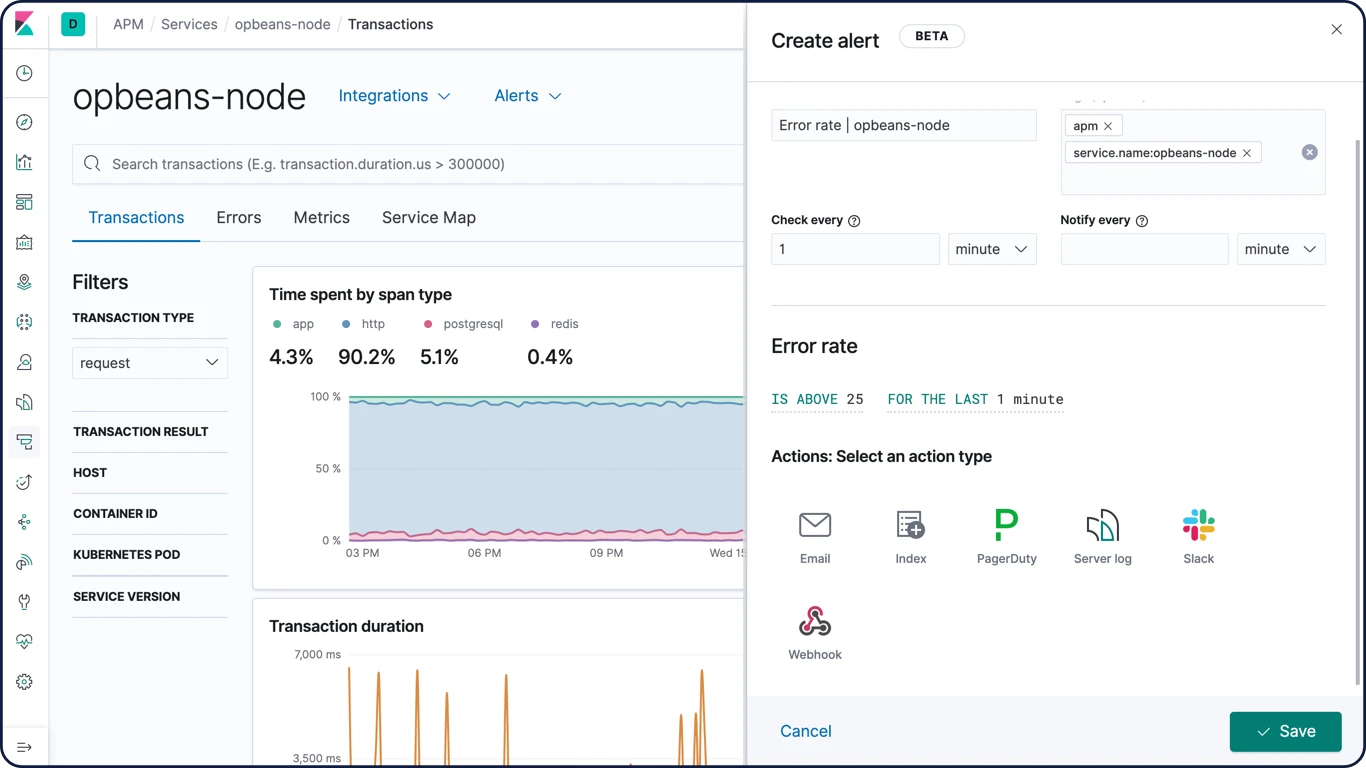
Mapping des services
Le mapping des services représente de façon visuelle les relations entre vos services. Il fournit des indicateurs importants concernant les transactions, comme la durée moyenne d'une transaction, les taux de requêtes et d'erreurs, ou encore l'utilisation du processeur et de la mémoire.
Intégration du Machine Learning
Créez une tâche de Machine Learning directement depuis l'application APM. Concentrez-vous rapidement sur les comportements anormaux grâce aux fonctionnalités de Machine Learning qui modélisent automatiquement vos données.
Explorer et visualiser
Explorer et visualiser
Visualisations
Transformez les données contenues dans vos index Elasticsearch en visualisations. Les visualisations Kibana s'appuient sur des requêtes Elasticsearch. Grâce à une série d'agrégations Elasticsearch qui vous permet d'extraire et de traiter vos données, vous pouvez créer des graphiques qui illustrent les tendances, les pics et les baisses que vous avez besoin de connaître.
Tableaux de bord
Un tableau de bord Kibana affiche une collection de visualisations et de recherches. Vous pouvez organiser, redimensionner et modifier le contenu du tableau de bord puis l'enregistrer pour pouvoir le partager. Vous pouvez mettre en place des recherches personnalisées entre plusieurs tableaux de bord, et même dans des applications web, afin de favoriser la prise de décisions et de mesures.
Canvas
Canvas est une toute nouvelle façon de rendre les données époustouflantes. Canvas combine vos données avec des couleurs, des formes, du texte et votre imagination pour proposer des présentations dynamiques, sur plusieurs pages et détaillées au pixel près, à toutes les tailles.
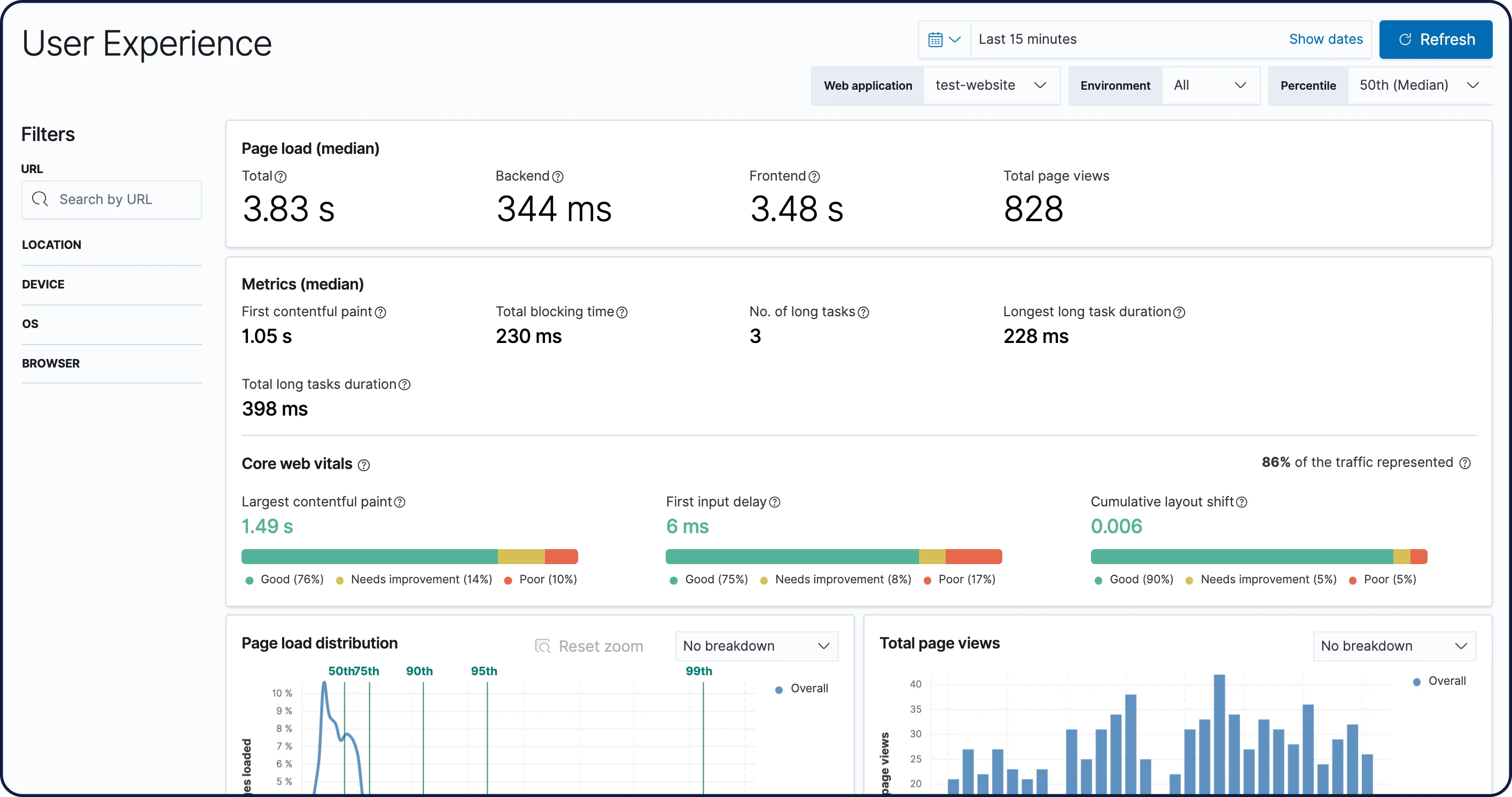
Expérience utilisateur
Les données de l'application User Experience reflètent les expériences réelles vécues par les utilisateurs. Ainsi, vous pouvez quantifier et analyser les performances de votre application web telles qu'elles ont été perçues.
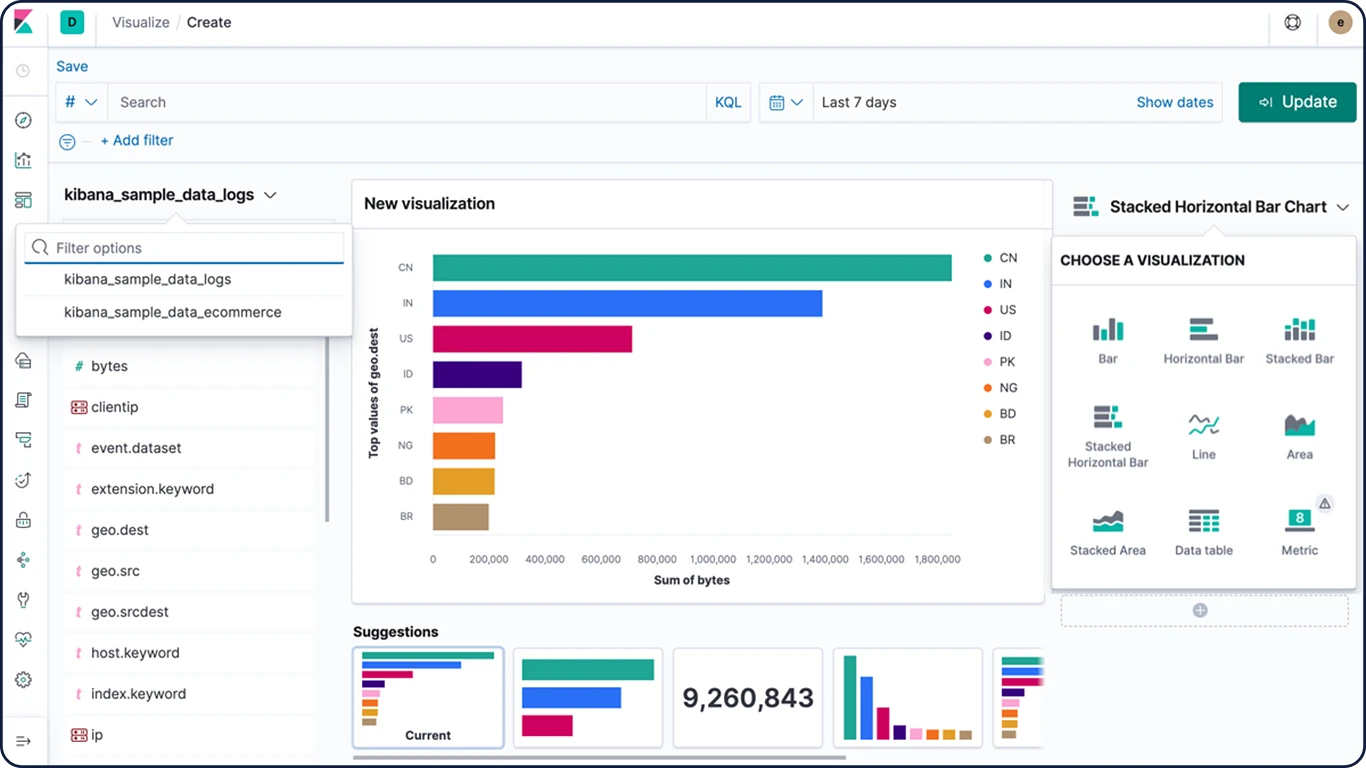
Kibana Lens
Facile à utiliser et intuitive, Kibana Lens est une interface utilisateur qui simplifie le processus de visualisation des données : un simple glisser-déposer et le tour est joué. Que vous ayez des milliards de logs à analyser ou des tendances à identifier à partir du trafic de votre site web, Lens vous permet de convertir vos données en informations exploitables en quelques clics. Et aucune expérience de Kibana n'est nécessaire.
Constructeur visuel Time Series Visual Builder (TSVB)
Le TSVB utilise toute la puissance de l'architecture d'agrégations d'Elasticsearch et combine un nombre infini d'agrégations et d'agrégations de pipeline pour afficher les données complexes de façon significative.
Analyse de graphes
Les fonctionnalités d'analyse de graphes vous permettent de découvrir comment les objets contenus dans un index Elasticsearch sont liés. Vous pouvez explorer les connexions entre les termes indexés et voir quelles connexions sont les plus importantes. Cela peut s'avérer utile dans plusieurs applications, de la détection de fraude aux moteurs de recommandation.
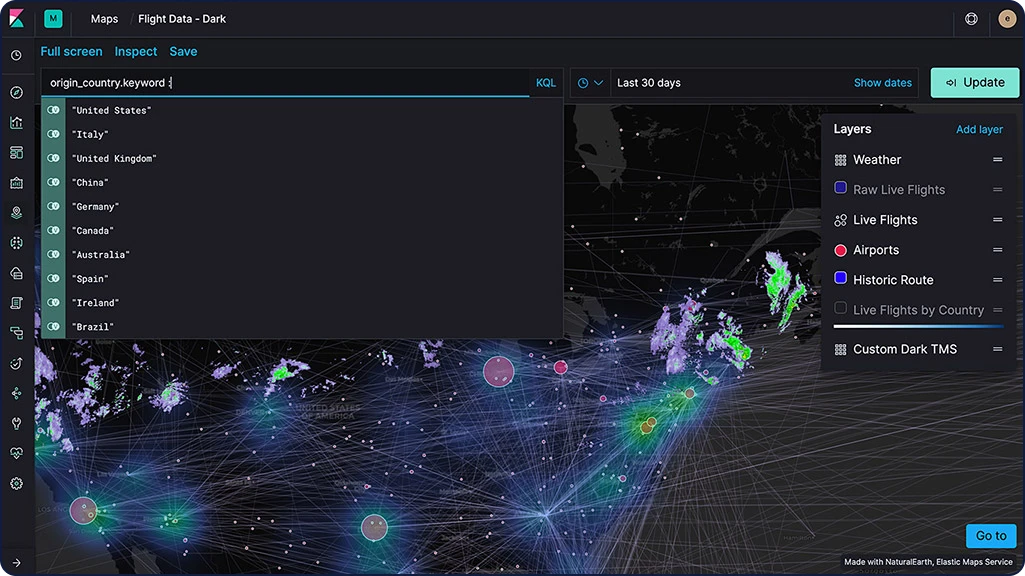
Analyse des données géospatiales
"À quel endroit ?". Voilà une question stratégique pour bon nombre d'utilisateurs de la Suite Elastic. Qu'il s'agisse de protéger votre réseau contre des attaques, de comprendre pourquoi les temps de réponse d'une application sont plus longs dans certaines zones géographiques ou tout simplement de trouver un taxi, les données géographiques ainsi que la recherche jouent un rôle important.
Monitoring de conteneur
Vos applications et votre environnement évoluent. La Suite Elastic aussi. Monitorez, recherchez et visualisez tout ce qui se passe au niveau de vos applications, de Docker et de Kubernetes, le tout depuis un seul et même emplacement.
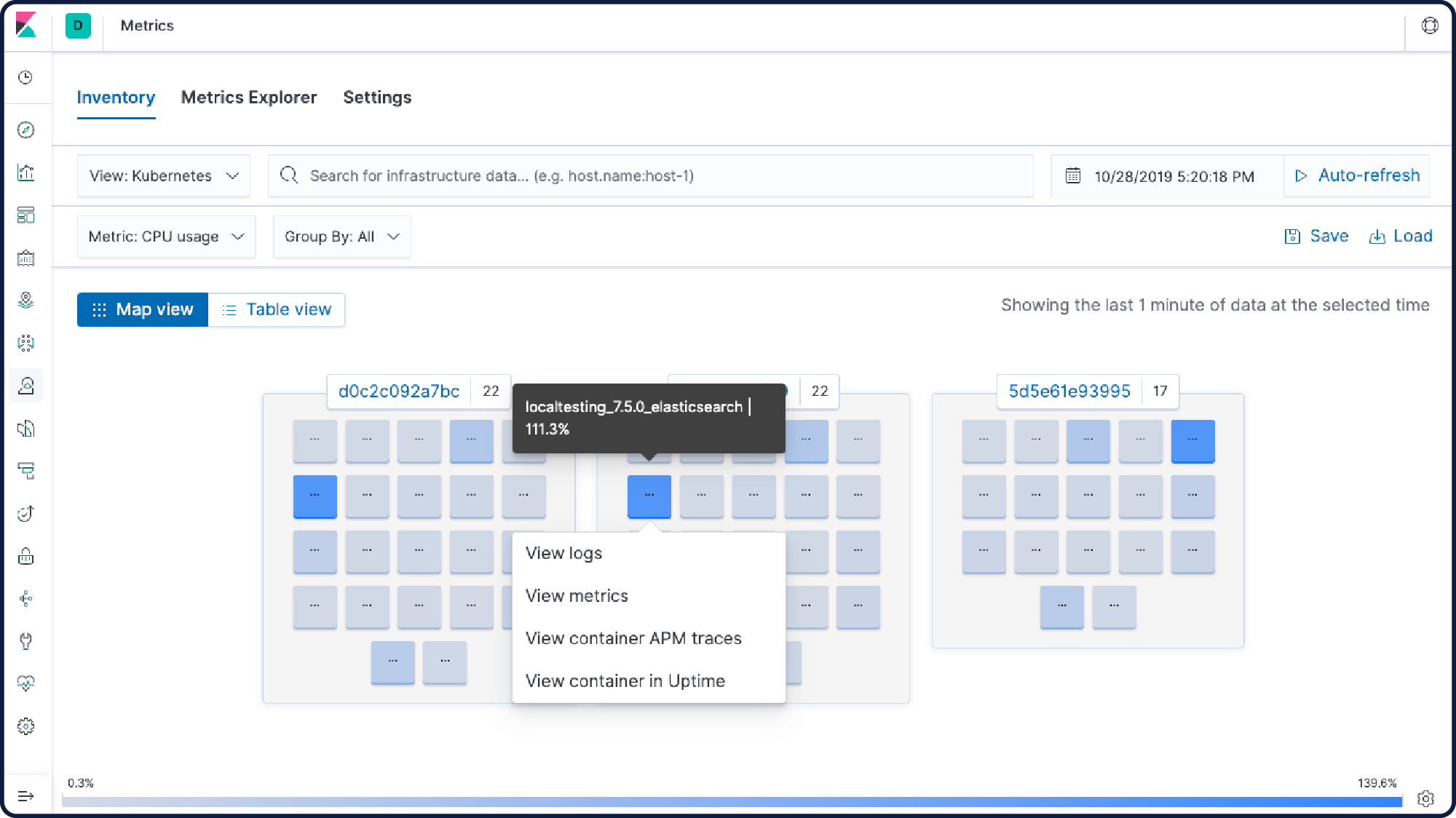
Plug-ins Kibana
Ajoutez des fonctionnalités supplémentaires à Kibana grâce aux modules de plug-in créés par la communauté. Les plug-ins open source sont disponibles pour plusieurs applications, extensions, visualisations et bien plus encore. Les plug-ins comprennent :
Visualisations Vega
Exportateur Prometheus
Graphiques 3D et graphes
Visualisations de calendrier
Et bien plus
Tutoriel relatif à l'importation des données
Grâce à notre tutoriel facile à suivre, apprenez à charger un ensemble de données dans Elasticsearch, à définir un modèle d'indexation, à découvrir et à explorer les données, à créer des visualisations et des tableaux de bord, et plus.
Éditeur des champs d'exécution Kibana
L'éditeur des champs d'exécution Kibana se sert de la fonctionnalité Elasticsearch pour les champs d'exécution afin de donner aux analystes la possibilité d'ajouter leurs propres champs personnalisés à la volée. Depuis les champs d'indexation, Discover et Kibana Lens, cet éditeur permet de créer, d'éditer et de supprimer des champs d'exécution.
Explorer et visualiser
Partager et collaborer
En quelques clics, partagez vos visualisations Kibana avec vos collègues, votre manager, son supérieur, vos clients, les responsables de la conformité, les prestataires. Bref : avec qui vous voulez, vraiment. À vous de choisir l'option de partage qui vous convient. Intégrez un tableau de bord, partagez un lien ou exportez vos données aux formats PDF, PNG ou CSV, puis envoyez votre fichier par e-mail. Vous pouvez aussi organiser vos tableaux de bord et vos visualisations via Kibana Spaces.
Tableaux de bord imbriquables
Depuis Kibana, vous pouvez facilement partager un lien direct vers un tableau de bord Kibana ou intégrer le tableau de bord dans une page Web avec un iframe (soit en tant que tableau de bord actualisé, soit en tant que snapshot statique de l'instant T).
Mode tableau de bord
Utilisez le rôle intégré "kibana_dashboard_only_user" pour restreindre ce que les utilisateurs voient lorsqu'ils se connectent à Kibana. Le rôle "kibana_dashboard_only_user" est préconfiguré pour être en lecture seule dans Kibana. Lorsque les utilisateurs ouvrent un tableau de bord, ils n'ont accès qu'à une expérience visuelle restreinte. L'ensemble des commandes de modification et de création sont cachées.
Spaces
Grâce à Spaces dans Kibana, vous pouvez organiser vos tableaux de bord et autres objets enregistrés en catégories pertinentes. Une fois dans un espace spécifique, vous ne verrez que les tableaux de bord et les autres objets enregistrés qui y appartiennent. En activant la sécurité, vous pouvez contrôler quels utilisateurs ont accès aux espaces individuels, ce qui vous donne une couche de protection supplémentaire.
Bannières personnalisées pour Kibana Spaces
Les bannières personnalisées permettent de différencier les espaces Kibana Spaces en fonction des rôles, des équipes, des fonctions, etc. Préparez des annonces et des messages adaptés à des espaces Kibana Spaces individuels, et aidez les utilisateurs à identifier l'espace auquel ils appartiennent.
Exportations CSV
Exportez les recherches enregistrées dans Discover vers des fichiers CSV pour les utiliser dans des éditeurs de texte externes.
Balises
Créez facilement des balises et ajoutez-les aux tableaux de bord et aux visualisations pour gérer le contenu avec efficacité.
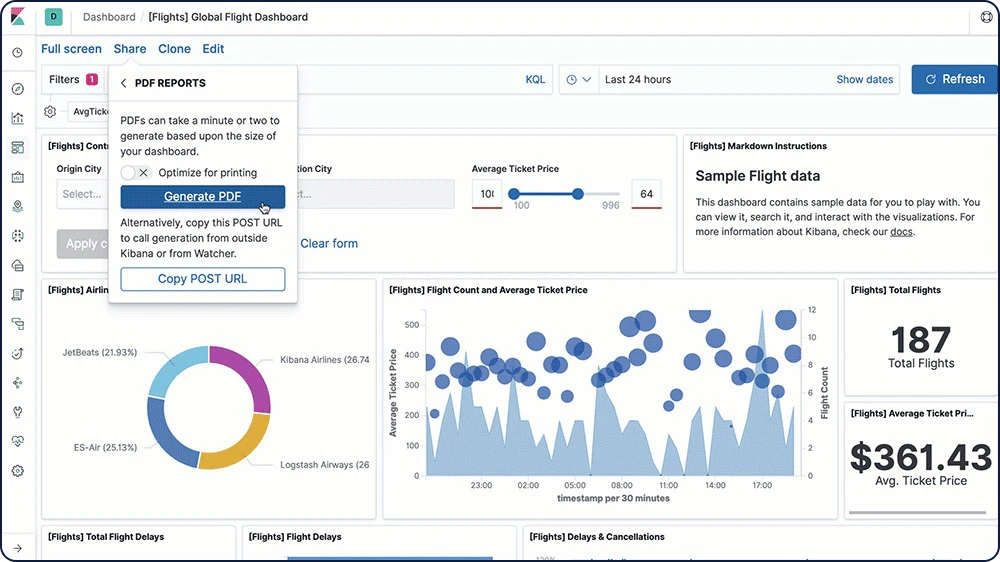
Rapports au format PDF/PNG
Générez rapidement des rapports à partir de n'importe quelle visualisation ou tableau de bord Kibana et sauvegardez-les au format PDF ou PNG. Rapports à la demande, rapports planifiés, rapports générés en fonction de certains événements… La fonctionnalité Reporting vous permet de faire tout cela et plus encore, comme partager automatiquement vos rapports avec vos collaborateurs.
Explorer et visualiser
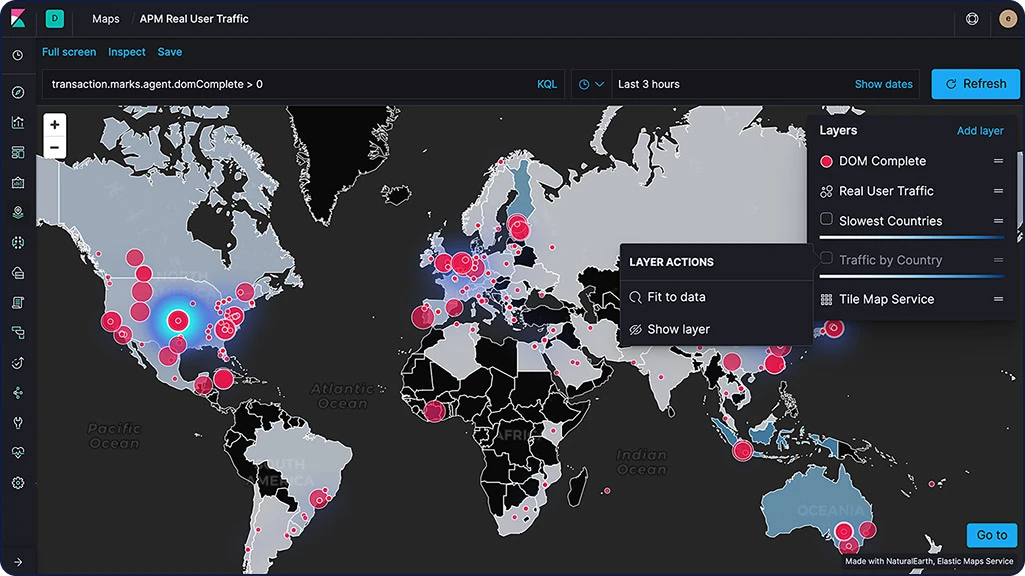
Elastic Maps
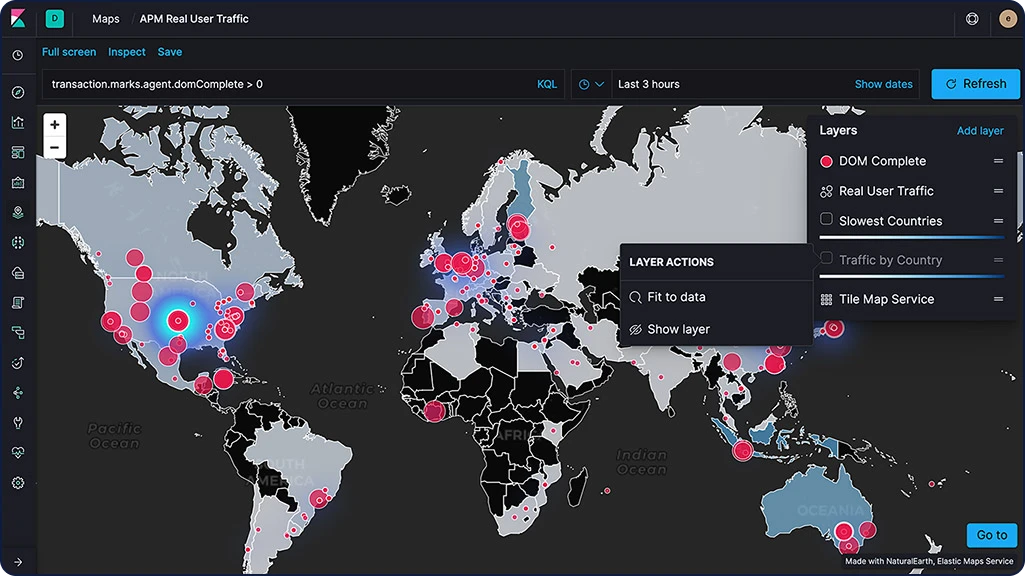
L'application Maps vous permet d'analyser vos données géographiques à grande échelle, rapidement, et en temps réel. Avec des fonctionnalités comme les couches et les index multiples intégrés à une carte, le tracé de documents bruts, les styles dynamiques côté client et la recherche globale sur plusieurs couches, comprendre vos données et les monitorer devient un jeu d'enfants.
Calques de carte
Avec l'application Maps de Kibana, ajoutez des calques distincts pour visualiser différents index dans une seule vue. Toutes les couches étant affichées sur la même carte, vous pouvez aussi les interroger et les filtrer en temps réel. Parmi les options de calques, on trouve les calques choroplèthes, les calques thermiques, les calques de mosaïque, les calques de vecteur et même des calques spécifiques aux cas d'utilisation, comme l'observabilité pour les données APM.
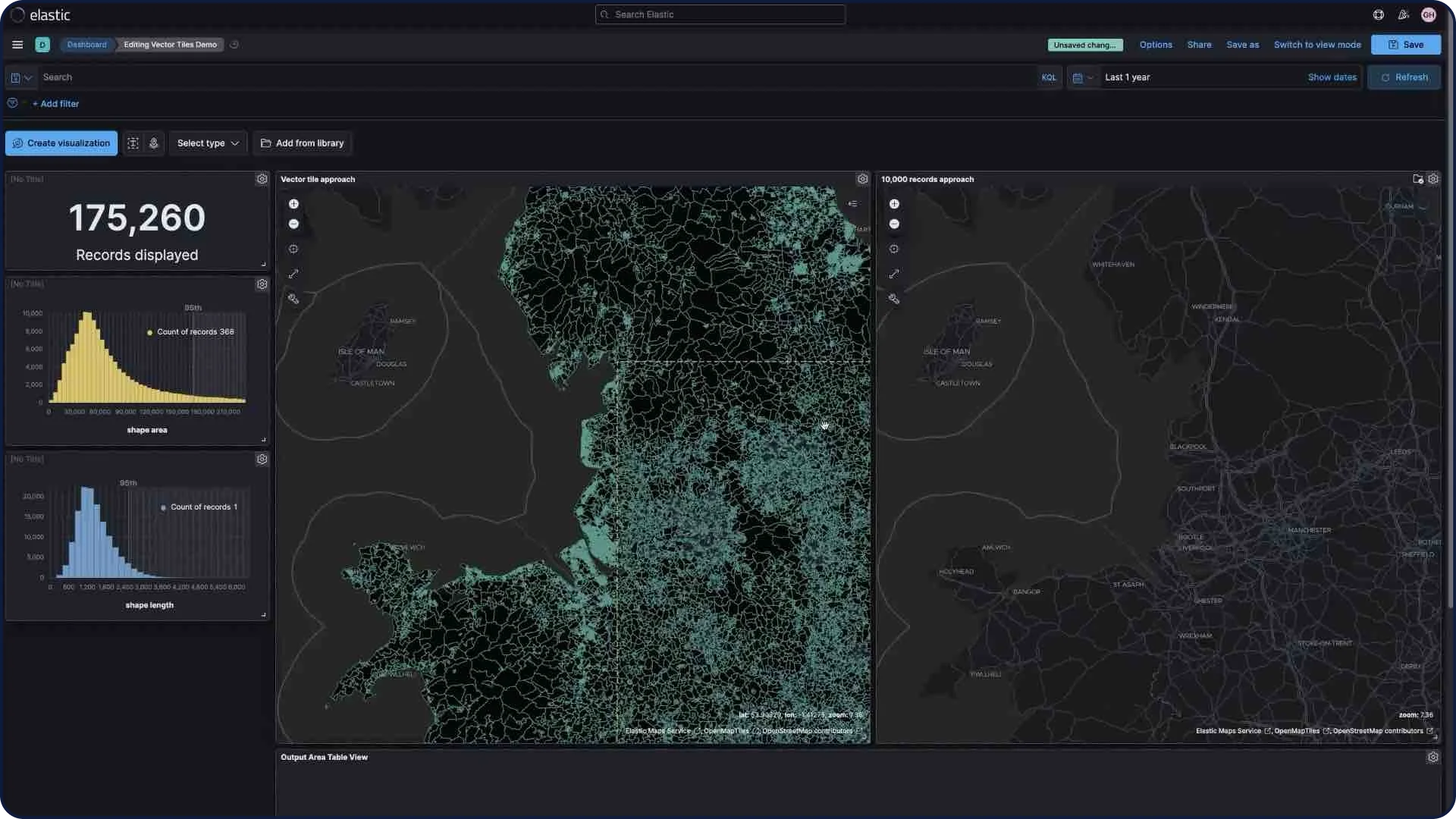
Tuiles vectorielles
Les tuiles vectorielles permettent de diviser votre carte en tuiles. Cette approche vous permet de bénéficier de performances optimales et d'un zoom fluide, par rapport à d'autres méthodes. Tous les nouveaux calques de polygone ont le paramètre "Use vector tiles" (Utiliser les tuiles vectorielles) activé par défaut. Si vous préférez opter pour l'approche utilisant 10 000 enregistrements, vous pouvez modifier les options d'échelle dans les paramètres d'un calque.
Cartes régionales personnalisées
Créez des cartes régionales à l'aide de données géographiques personnalisées. Il s'agit de cartes thématiques sur lesquelles les formes vectorielles associées à un périmètre s'affichent en dégradé.
Elastic Maps Service (niveaux de zoom)
Le service Elastic Maps alimente toutes les visualisations géospatiales dans Kibana (y compris l'application Maps) en fournissant des tuiles de fond de carte, des fichiers de formes et des fonctionnalités clés essentielles à la visualisation des données géographiques. Avec la distribution par défaut de Kibana, vous pouvez zoomer jusqu'à 18 fois sur une carte.
Serveur Elastic Maps
Le serveur Elastic Maps se sert des fonds de carte et des frontières d'Elastic Maps Service sur une infrastructure locale.
Importation de fichiers GeoJSON
Bien qu'elle soit simple et facile à utiliser, la fonctionnalité d'importation GeoJSON n'en est pas moins performante. Grâce à une ingestion directe vers Elasticsearch, cette fonctionnalité vous permet de faire glisser des fichiers GeoJSON enrichis de points, de formes et de contenu, pour les déposer sur une carte et les visualiser instantanément. Servez-vous des limites GeoJSON définies pour configurer des alertes par email ou application Web lorsque vous surveillez des mouvements d'objets à l'aide des données.
Alertes géographiques
Une notification se déclenche dès qu'une entité franchit une limite spécifique d'une manière ou d'une autre. L'emplacement de l'entité est monitoré tout au long de sa présence dans les limites définies.
Chargement de fichiers de forme
Chargez des fichiers de forme dans Elastic avec cet agent de chargement simple mais efficace intégré directement dans l'application Maps. Importez facilement des données ouvertes locales et des limites afin d'effectuer des analyses et des comparaisons.
Explorer et visualiser
Elastic Logs
Directement compatible avec les sources de données les plus courantes, la Suite Elastic intègre aussi des tableaux de bord par défaut qui vous permettent de démarrer sans attendre. Bref : nous avons tout fait pour vous faciliter la vie et vous offrir une expérience optimale. Transférez des logs avec Filebeat et Winlogbeat, indexez-les dans Elasticsearch – et visualisez le tout dans Kibana en quelques minutes.
Agent de transfert de logs (Filebeat)
Oubliez SSH. Avec Filebeat, dites oui à la simplicité : misez sur un agent de transfert léger qui vous permet de centraliser vos logs et vos fichiers. Filebeat intègre des modules internes (auditd, Apache, NGINX, System et MySQL, entre autres) qui simplifient la collecte, l'analyse et la visualisation des formats de logs les plus courants – le tout, via une seule commande.
Tableaux de bord de logs
Des exemples de tableaux de bord Filebeat vous facilitent la tâche pour explorer les données de log dans Kibana. Commencez rapidement à utiliser ces tableaux de bord préconfigurés puis personnalisez-les selon vos besoins.
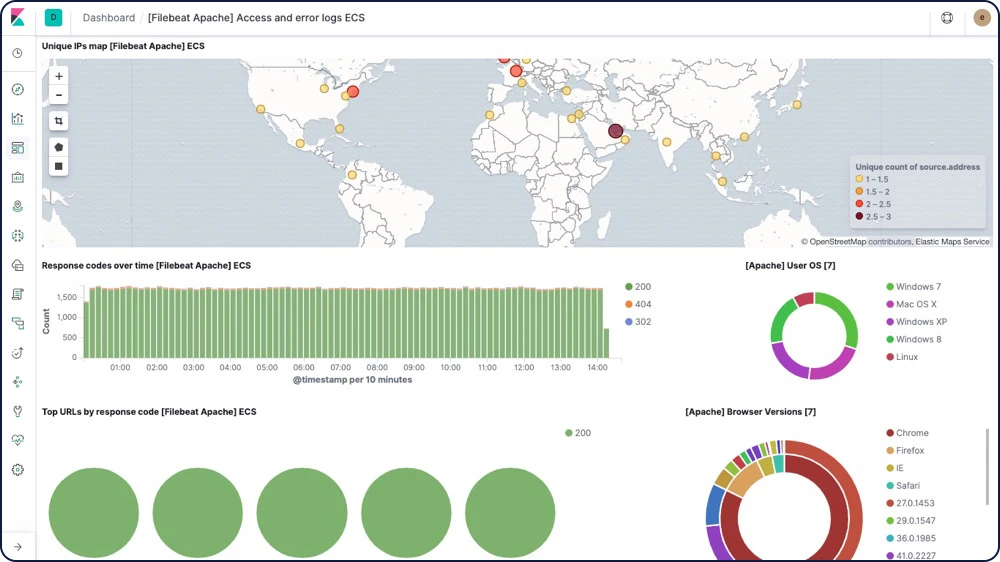
Détection des anomalies de taux de logs
L'analyse des taux de logs optimisée par le Machine Learning met automatiquement en évidence les périodes de temps où les taux de logs sont hors normes. Un avantage pour identifier et inspecter rapidement les anomalies de logs.
Application Logs
L'application Logs fournit un suivi des logs en temps réel via un affichage compact et personnalisable. Les données de log sont ensuite corrélées aux indicateurs dans l'application Metrics, vous facilitant ainsi le diagnostic des problèmes.
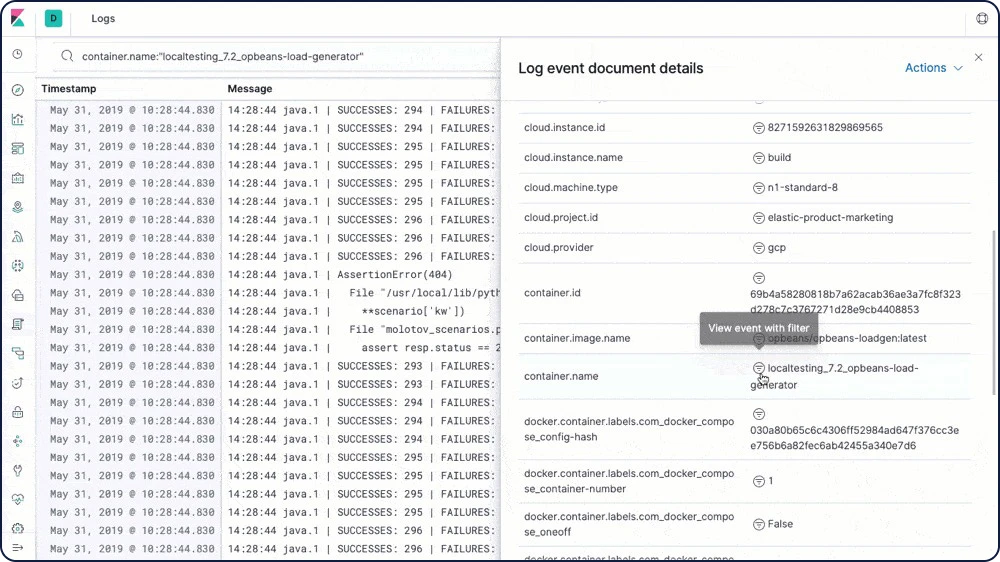
Explorer et visualiser
Elastic Metrics
Avec Elastic Metrics, effectuez facilement le suivi d'indicateurs de haut niveau comme l'utilisation des processeurs, la charge système, l'utilisation de la mémoire et le trafic réseau. L'évaluation de l'intégrité globale de vos serveurs, de vos conteneurs et de vos services devient ainsi bien plus simple.
Agent de transfert d'indicateurs (Metricbeat)
Metricbeat est un agent de transfert léger que vous pouvez installer sur vos serveurs pour collecter des indicateurs qui proviennent du système d'exploitation et des services qui s'exécutent sur le serveur de manière périodique. Statistiques relatives au processeur, à la mémoire, à Redis ou NGINX, Metricbeat se charge du transfert léger des statistiques de vos systèmes et services.
Tableaux de bord d'indicateurs
Les exemples de tableaux de bord de Metricbeat vous facilitent la tâche lorsque vous commencez à monitorer vos serveurs dans Kibana. Commencez rapidement avec ces tableaux de bord prêts à l’emploi, puis personnalisez-les selon vos besoins.
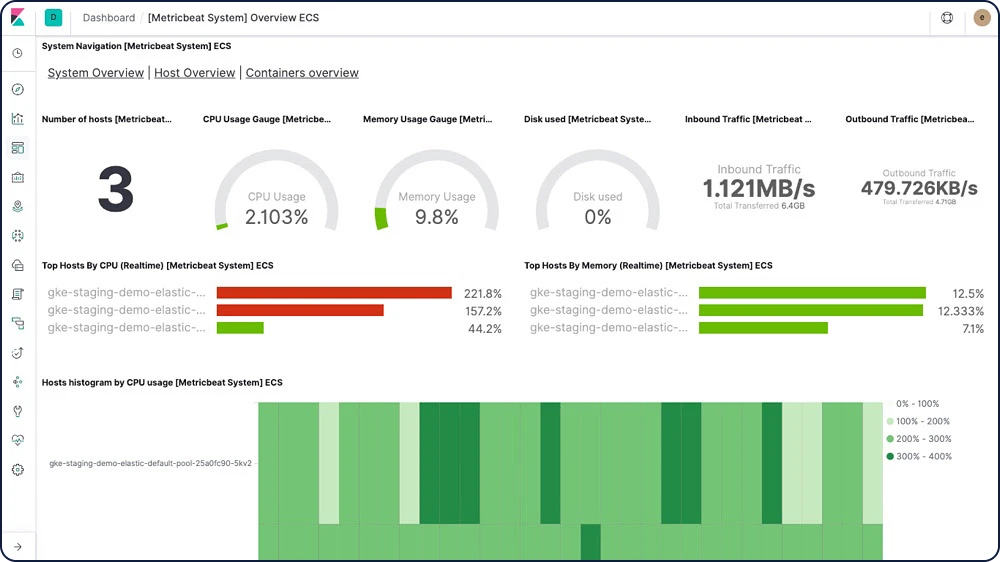
Intégration de l'alerting pour Metrics
Créez des alertes de seuil pour vos indicateurs avec des commentaires en temps réel, directement dans l'application Metrics dans Kibana. Choisissez le mode par lequel vous souhaitez être averti : documents, logs, Slack, webhooks simples, ou autre.
Intégration du Machine Learning pour Metrics
Décelez les problèmes d'infrastructure courants grâce à la détection des anomalies en un clic proposée par l'interface utilisateur Metrics.
Application Metrics
Une fois vos indicateurs diffusés en continu vers Elasticsearch, l'application Metrics de Kibana vous permet de les monitorer et d'identifier les problèmes en temps réel.
Explorer et visualiser
Elastic Uptime
Propulsée par l'agent open source Heartbeat, la solution Elastic Uptime permet d'associer vos données de disponibilité au contexte détaillé que fournissent vos logs, vos indicateurs et APM. Corréler les activités, en tirer des conclusions et résoudre rapidement les problèmes devient ainsi bien plus simple.
Moniteur de disponibilité (Heartbeat)
Heartbeat est un daemon léger que vous pouvez installer sur un serveur distant pour contrôler l'état de vos services de manière périodique et déterminer s'ils sont disponibles. Heartbeat ingère les données du serveur. Celles-ci sont ensuite affichées sur le tableau de bord et l'application Uptime dans Kibana.
Tableaux de bord Uptime
Les tableaux de bord Heartbeat préconfigurés vous permettent de visualiser facilement le statut de vos services dans Kibana. Commencez rapidement avec ces tableaux de bord prêts à l’emploi, puis personnalisez-les selon vos besoins.
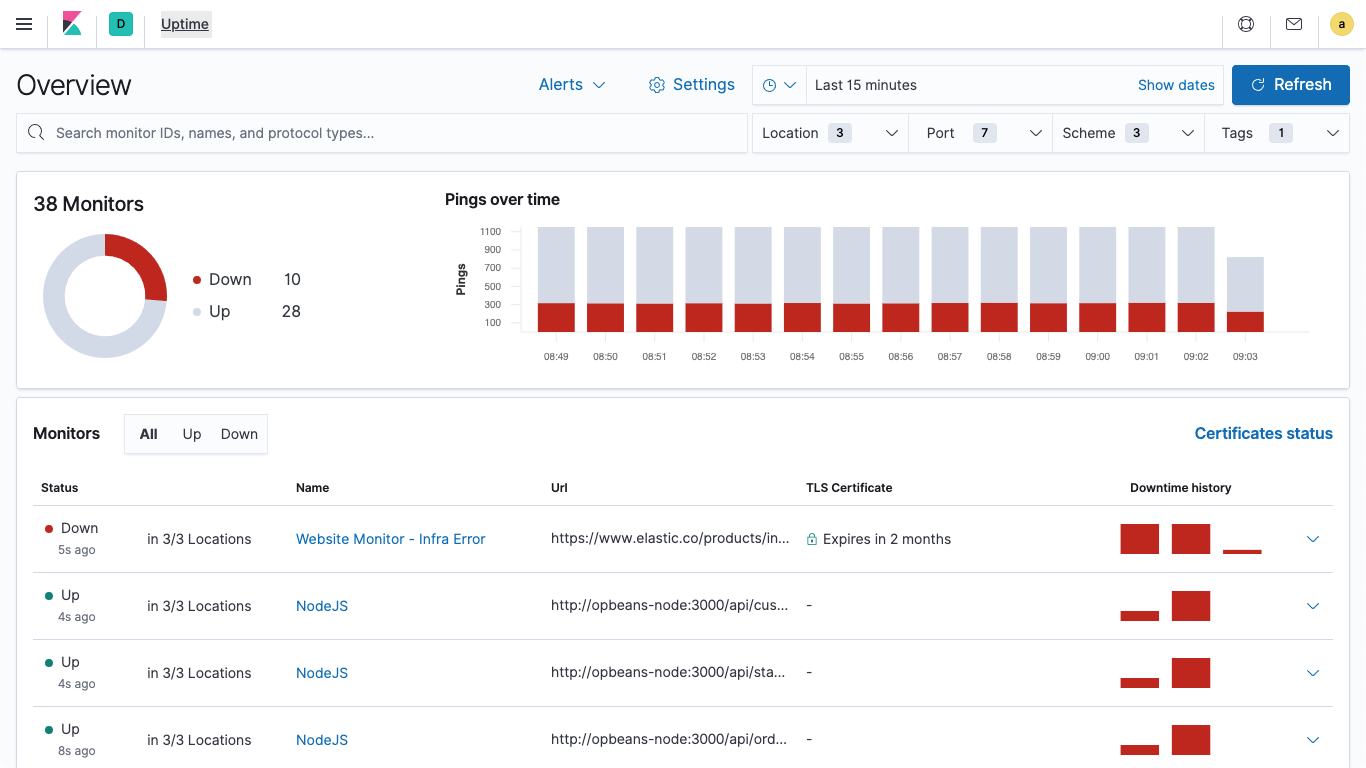
Intégration de l'alerting pour Uptime
Créez facilement des alertes de seuil à partir de vos données de disponibilité directement dans l'application Uptime. Choisissez le mode par lequel vous souhaitez être averti : documents, logs, Slack, webhooks simples, ou autre.
Monitoring des certificats
Vérifiez si vos certificats SSL ou TLS expirent bientôt ou recevez une notification quand c'est le cas. Vos services sont ainsi toujours disponibles, et tout cela se fait directement dans l'application Uptime.
Suivi synthétique
Simulez l'expérience utilisateur sur des parcours à plusieurs étapes, par exemple au niveau du flux de paiement d'une boutique en ligne. Capturez des informations détaillées sur le statut à chaque étape afin d'identifier les zones problématiques et, de là, créez des expériences numériques exceptionnelles.
Application Uptime
L'application Uptime de Kibana a pour but de vous aider à identifier rapidement et à diagnostiquer les pannes ainsi que d'autres problèmes de connectivité au sein de votre réseau ou de votre environnement. Monitorez facilement les hôtes, les services, les sites web, les API et plus depuis cette interface utile.
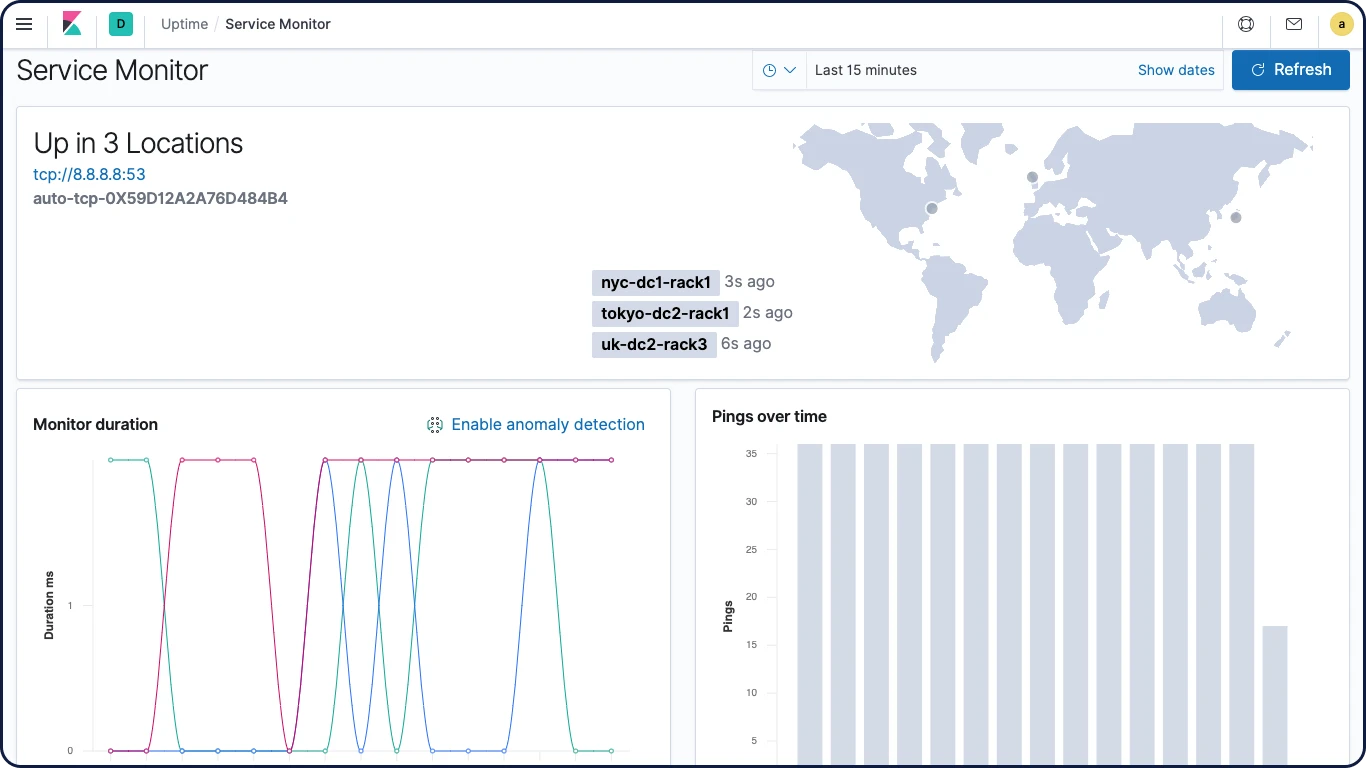
Explorer et visualiser
Elastic Security
Avec Elastic Security, les équipes de sécurité peuvent prévenir les menaces, les détecter et y répondre. La solution permet en effet de bloquer les ransomwares et les malwares au niveau de l'hôte, mais aussi d'automatiser la détection des menaces et des anomalies. Elle permet également de rationaliser la réponse avec des workflows intuitifs, une gestion intégrée des incidents, ainsi que des intégrations aux plateformes SOAR et aux systèmes de suivi des incidents.
Elastic Common Schema
Avec Elastic Common Schema (ECS), analysez de manière homogène les données provenant de différentes sources. Vous pouvez désormais appliquer des règles de détection, des tâches de Machine Learning, des tableaux de bord et d'autres contenus de sécurité à un plus grand nombre de cas d'utilisation, améliorer la précision de vos recherches et utiliser des noms de champs bien plus simples à mémoriser.
Analyse de la sécurité de l'hôte
Elastic Security permet d'analyser de manière interactive les données aux points de terminaison d'Elastic Agent et d'Elastic Beats, ainsi que des technologies commerciales telles que CrowdStrike et Microsoft Defender for Endpoint. Explorez les activités du shell avec Session View, et les processus avec Analyzer.
Analyse de la sécurité réseau
Elastic Security est capable de monitorer la sécurité réseau grâce à des cartes interactives, des graphes, des tableaux sur les événements, et bien plus encore. La solution est compatible avec de nombreuses solutions de sécurité réseau, notamment les technologies open source comme Zeek et Suricata, les appareils provenant de fournisseurs tels que Cisco ASA, Palo Alto Networks et Check Point, mais aussi certains services cloud, notamment AWS, Azure, GCP et Google Cloud.
Analyse de la sécurité de l'utilisateur
En matière d'analyse des entités, Elastic Security est la solution idéale. En effet, elle offre de la visibilité sur l'activité des utilisateurs, ce qui aide les professionnels à réagir aux menaces internes, aux piratages des comptes, à l'abus de privilèges et autres angles d'attaques. En permettant de collecter les données sur l'ensemble de l'environnement, cette solution renforce le monitoring de la sécurité. Les données utilisateur collectées sont présentées dans des visualisations et des tableaux. Le contexte utilisateur, quant à lui, est fourni dans le cadre du processus de détection ou d'examen. Vous bénéficiez en plus d'un accès rapide à des détails supplémentaires.
Timeline Event Explorer
Grâce à l'afficheur d'événements Timeline Event Viewer, les analystes peuvent visualiser, filtrer, corréler et annoter les événements, collecter des données pour connaître la cause première ou la portée des attaques, harmoniser les investigations et regrouper les informations à des fins de référence immédiate et sur le long terme.
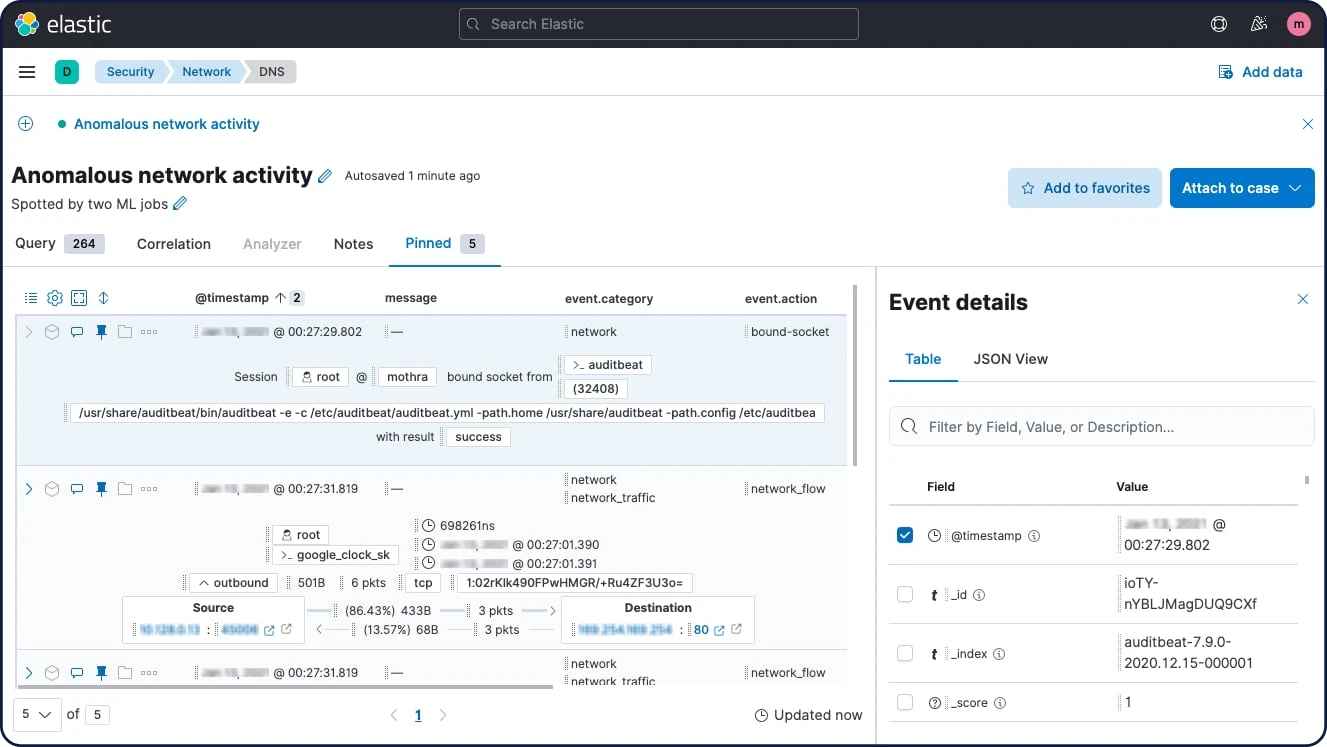
Gestion des incidents
Les workflows de gestion intégrée des incidents permettent une meilleure maîtrise en matière de détection des menaces et de réponses apportées à ces dernières. Avec Elastic Security, les analystes peuvent désormais ouvrir des incidents, les mettre à jour, y ajouter des tags, les commenter, les fermer et les intégrer à des systèmes externes. Une API ouverte et la prise en charge prédéfinie d'IBM Resilient, de Jira, de Swimlane et de ServiceNow permettent en outre un alignement sur les workflows existants.
Moteur de détection
Le moteur de détection assure une détection des menaces basée sur les techniques d'attaque et vous alerte lorsqu'il détecte des anomalies affichant des valeurs élevées. Il est rapide à adopter grâce aux règles prédéfinies développées et testées par les ingénieurs en recherche d'Elastic Security. De plus, vous pouvez aussi créer des règles personnalisées pour n'importe quelles données formatées pour Elastic Common Schema (ECS).
Détection des anomalies par Machine Learning
Le Machine Learning intégré automatise la détection des anomalies, tout en renforçant les workflows de recherche et de détection. Et avec le portefeuille de tâches de Machine Learning prédéfinies que nous vous proposons, leur adoption n'a jamais été plus rapide. Les workflows d'alerting et d'investigation exploitent les résultats du Machine Learning.
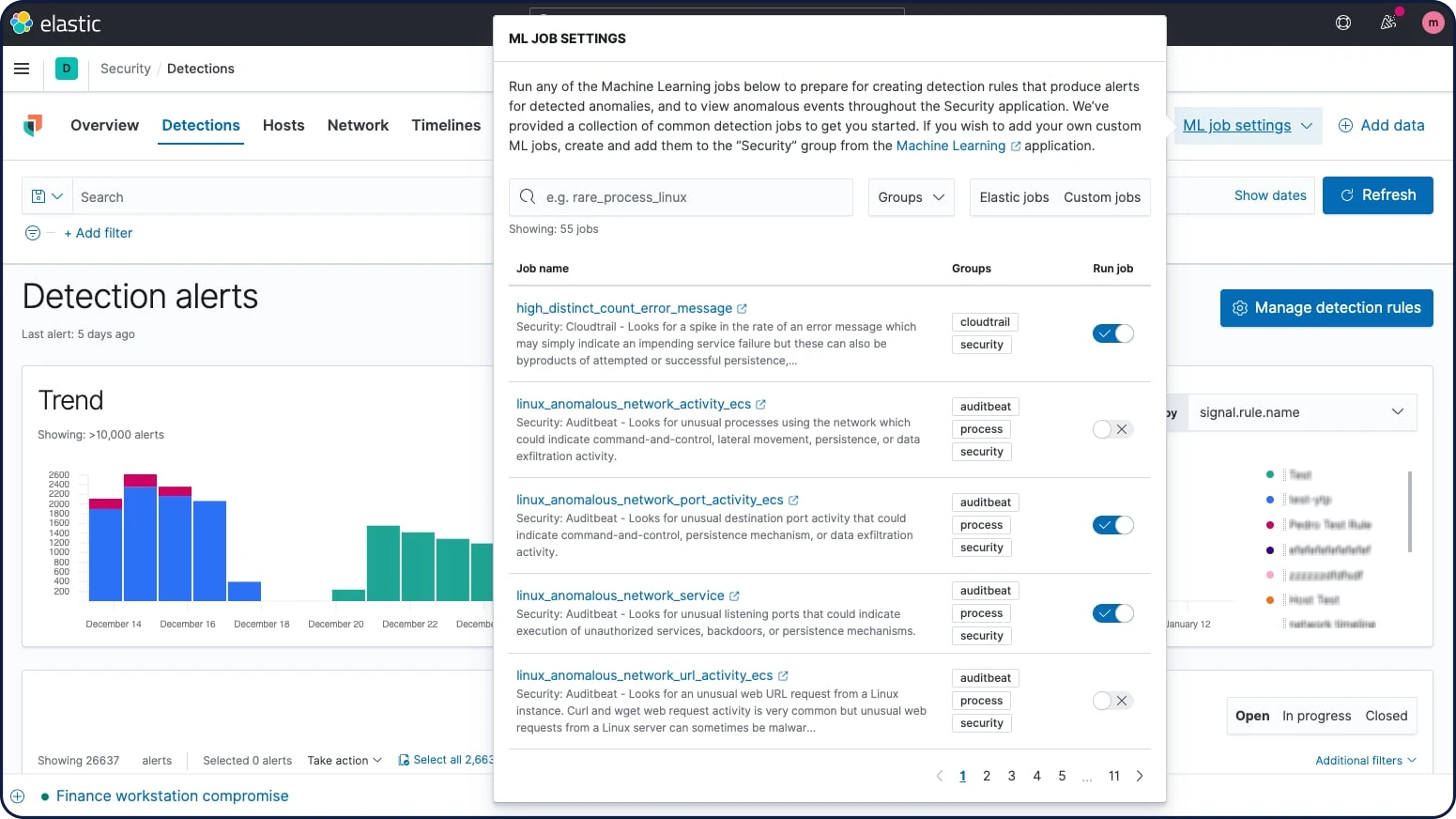
Prévention contre les ransomwares basée sur les comportements
Elastic Security assure la prévention contre les ransomwares grâce à l'analyse des comportements effectuée sur Elastic Agent. Les attaques par ransomware ciblant des systèmes Windows sont bloquées grâce à l'analyse des données de processus système individuels. Cette protection est efficace sur un large éventail de familles de ransomwares courants.
Protection contre les comportements malveillants
Dans Elastic Agent, la protection contre les comportements malveillants stoppe les menaces sophistiquées au niveau des points de terminaison. Elle assure une nouvelle couche de protection pour les hôtes Linux, Windows et macOS. Par ailleurs, elle vient renforcer la protection existante contre les malwares et les ransomwares avec une prévention dynamique du comportement post-exécution. Résultat : les menaces avancées sont stoppées net.
Protection contre les malwares
La prévention sans signature contre les malwares stoppe immédiatement les programmes exécutables malveillants sur les hôtes Linux, Windows et macOS. Cette fonctionnalité intègre Elastic Agent, qui recueille également des données de sécurité et permet l'inspection et la réaction basées sur l'hôte. L'administration basée sur Kibana rationalise le déploiement et l'administration.
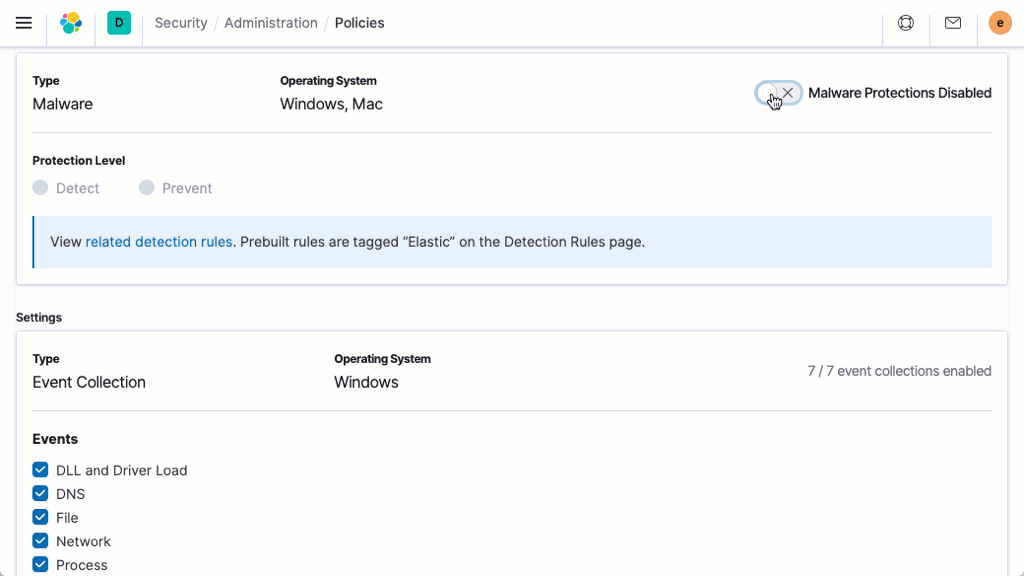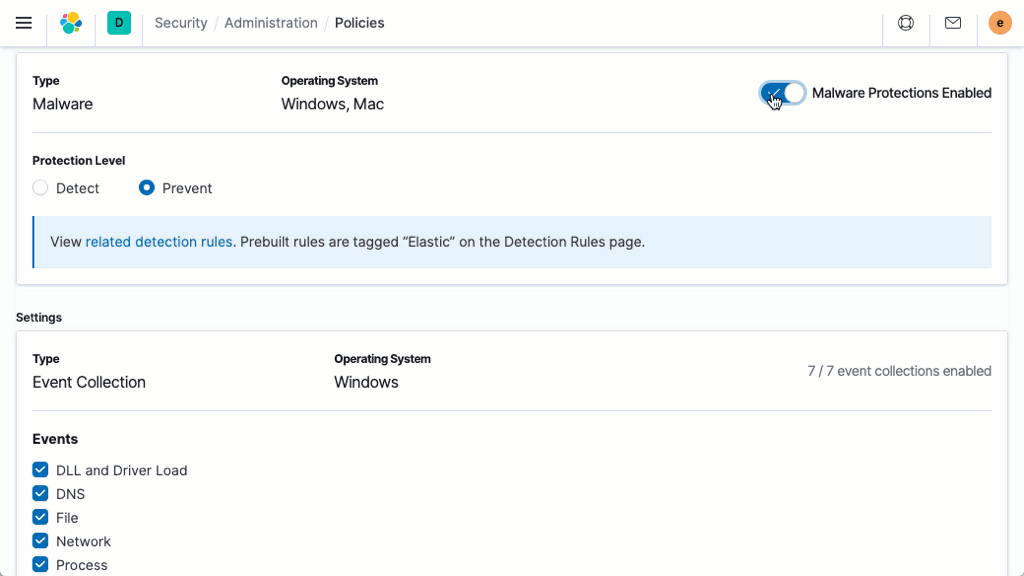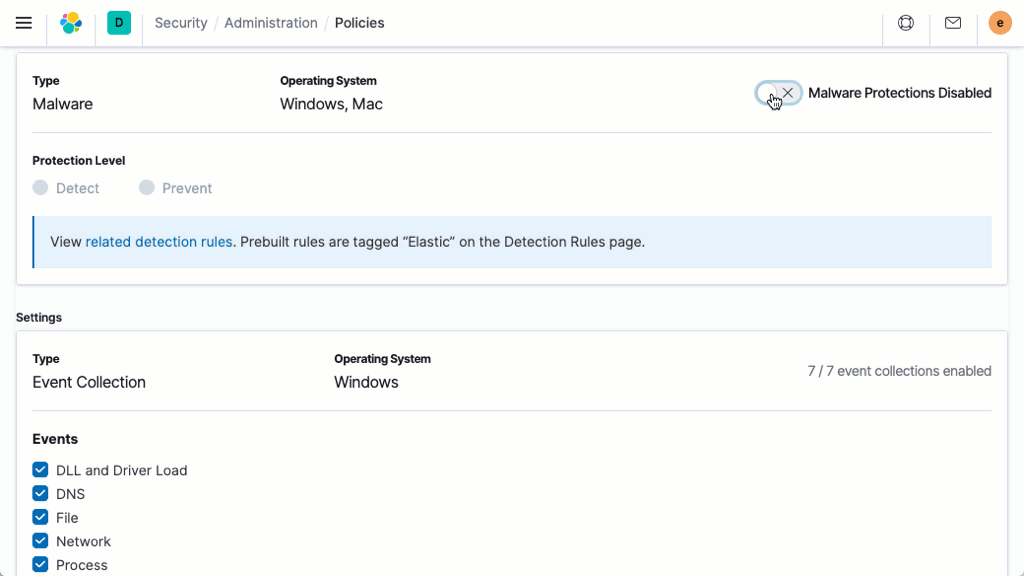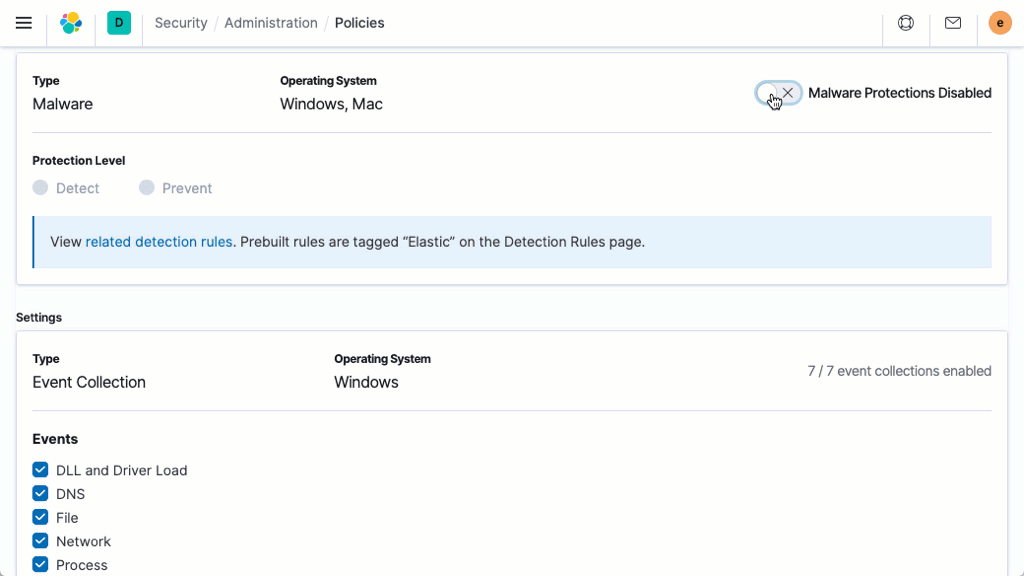
Protection de la mémoire de l'hôte
La protection de la mémoire d'Elastic Agent bloque un grand nombre de techniques exploitées pour l'injection de processus par shellcode. Elle stoppe en effet les sous-techniques utilisées comme le piratage de l'exécution de threads, les fonctions Asynchronous Procedure Call, le Process Hollowing, ou encore le Process Doppelgänging.
Protection de la mémoire contre les menaces
Gestion centralisée d'osquery
Grâce à Elastic Security, les utilisateurs peuvent facilement déployer osquery sur chaque point de terminaison tout en rationalisant la détection et l'inspection des hôtes sur Linux, Windows et macOS. La solution fournit un accès direct à des données d'hôte enrichies, extraites avec des requêtes SQL préconçues et personnalisées aux fins d'analyse dans Elastic Security.
Analyse des activités de réseau basée sur les hôtes
Grâce à Elastic Agent, recueillez les activités de réseau à partir d'un nombre illimité d'hôtes. Analysez-les afin d'identifier au sein du périmètre du réseau et au-delà le trafic indétectable pour les pare-feux. Ainsi, les équipes de sécurité sont en mesure de lutter contre les comportements malveillants, comme les attaques par point d'eau et DNS ou les exfiltrations de données. L'intégration de l'analyseur de paquets réseau comprend une licence commerciale gratuite de Npcap, la bibliothèque de sniffing de paquets déployée à grande échelle pour les systèmes Windows, qui confère une visibilité sur chaque hôte du réseau, indépendamment de son système d'exploitation.
Audit des sessions de charge de travail dans le cloud
Elastic sécurise les charges de travail du cloud hybrides et les applications cloud-native avec un agent de transfert léger alimenté par la technologie eBPF. Identifiez automatiquement les menaces pesant sur l'exécution de vos systèmes grâce à des modèles de Machine Learning et à des règles de détection prédéfinies et personnalisées. Menez vos investigations dans un affichage de type terminal qui repère les contenus riches.
Collecte de données sur le niveau de sécurité Kubernetes (KSPM) et conclusions de la posture du CIS
Bénéficiez d'une visibilité sur votre niveau de sécurité au sein de vos environnements multi-cloud. Examinez les conclusions, comparez-les aux contrôles du CIS et appliquez les corrections conseillées afin d'impulser une amélioration rapide.