- Elasticsearch Guide: other versions:
- What is Elasticsearch?
- What’s new in 8.10
- Set up Elasticsearch
- Installing Elasticsearch
- Run Elasticsearch locally
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Miscellaneous cluster settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- Health Diagnostic settings
- Index lifecycle management settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Monitoring settings
- Node
- Networking
- Node query cache settings
- Search settings
- Security settings
- Shard request cache settings
- Snapshot and restore settings
- Transforms settings
- Thread pools
- Watcher settings
- Advanced configuration
- Important system configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Plugins
- Upgrade Elasticsearch
- Index modules
- Mapping
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Index templates
- Data streams
- Ingest pipelines
- Example: Parse logs
- Enrich your data
- Processor reference
- Append
- Attachment
- Bytes
- Circle
- Community ID
- Convert
- CSV
- Date
- Date index name
- Dissect
- Dot expander
- Drop
- Enrich
- Fail
- Fingerprint
- Foreach
- Geo-grid
- GeoIP
- Grok
- Gsub
- HTML strip
- Inference
- Join
- JSON
- KV
- Lowercase
- Network direction
- Pipeline
- Redact
- Registered domain
- Remove
- Rename
- Reroute
- Script
- Set
- Set security user
- Sort
- Split
- Trim
- Uppercase
- URL decode
- URI parts
- User agent
- Aliases
- Search your data
- Collapse search results
- Filter search results
- Highlighting
- Long-running searches
- Near real-time search
- Paginate search results
- Retrieve inner hits
- Retrieve selected fields
- Search across clusters
- Search multiple data streams and indices
- Search shard routing
- Search templates
- Search with synonyms
- Sort search results
- kNN search
- Semantic search
- Searching with query rules
- Query DSL
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Categorize text
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Frequent item sets
- Geo-distance
- Geohash grid
- Geohex grid
- Geotile grid
- Global
- Histogram
- IP prefix
- IP range
- Missing
- Multi Terms
- Nested
- Parent
- Random sampler
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Time series
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Average bucket
- Bucket script
- Bucket count K-S test
- Bucket correlation
- Bucket selector
- Bucket sort
- Change point
- Cumulative cardinality
- Cumulative sum
- Derivative
- Extended stats bucket
- Inference bucket
- Max bucket
- Min bucket
- Moving function
- Moving percentiles
- Normalize
- Percentiles bucket
- Serial differencing
- Stats bucket
- Sum bucket
- Bucket aggregations
- Geospatial analysis
- EQL
- SQL
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Data management
- ILM: Manage the index lifecycle
- Tutorial: Customize built-in policies
- Tutorial: Automate rollover
- Index management in Kibana
- Overview
- Concepts
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Troubleshooting index lifecycle management errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Data tiers
- Autoscaling
- Monitor a cluster
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure the Elastic Stack
- Elasticsearch security principles
- Start the Elastic Stack with security enabled automatically
- Manually configure security
- Updating node security certificates
- User authentication
- Built-in users
- Service accounts
- Internal users
- Token-based authentication services
- User profiles
- Realms
- Realm chains
- Security domains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- JWT authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Looking up users without authentication
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Role restriction
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enable audit logging
- Restricting connections with IP filtering
- Securing clients and integrations
- Operator privileges
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Watcher
- Command line tools
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- How to
- Troubleshooting
- Fix common cluster issues
- Diagnose unassigned shards
- Add a missing tier to the system
- Allow Elasticsearch to allocate the data in the system
- Allow Elasticsearch to allocate the index
- Indices mix index allocation filters with data tiers node roles to move through data tiers
- Not enough nodes to allocate all shard replicas
- Total number of shards for an index on a single node exceeded
- Total number of shards per node has been reached
- Troubleshooting corruption
- Fix data nodes out of disk
- Fix master nodes out of disk
- Fix other role nodes out of disk
- Start index lifecycle management
- Start Snapshot Lifecycle Management
- Restore from snapshot
- Multiple deployments writing to the same snapshot repository
- Addressing repeated snapshot policy failures
- Troubleshooting an unstable cluster
- Troubleshooting discovery
- Troubleshooting monitoring
- Troubleshooting transforms
- Troubleshooting Watcher
- Troubleshooting searches
- Troubleshooting shards capacity health issues
- REST APIs
- API conventions
- Common options
- REST API compatibility
- Autoscaling APIs
- Behavioral Analytics APIs
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat component templates
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Prevalidate node removal
- Nodes reload secure settings
- Nodes stats
- Cluster Info
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Create or update desired nodes
- Get desired nodes
- Delete desired nodes
- Get desired balance
- Reset desired balance
- Cross-cluster replication APIs
- Data stream APIs
- Document APIs
- Enrich APIs
- EQL APIs
- Features APIs
- Fleet APIs
- Find structure API
- Graph explore API
- Index APIs
- Alias exists
- Aliases
- Analyze
- Analyze index disk usage
- Clear cache
- Clone index
- Close index
- Create index
- Create or update alias
- Create or update component template
- Create or update index template
- Create or update index template (legacy)
- Delete component template
- Delete dangling index
- Delete alias
- Delete index
- Delete index template
- Delete index template (legacy)
- Exists
- Field usage stats
- Flush
- Force merge
- Get alias
- Get component template
- Get field mapping
- Get index
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Import dangling index
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- List dangling indices
- Open index
- Refresh
- Resolve index
- Rollover
- Shrink index
- Simulate index
- Simulate template
- Split index
- Unfreeze index
- Update index settings
- Update mapping
- Index lifecycle management APIs
- Create or update lifecycle policy
- Get policy
- Delete policy
- Move to step
- Remove policy
- Retry policy
- Get index lifecycle management status
- Explain lifecycle
- Start index lifecycle management
- Stop index lifecycle management
- Migrate indices, ILM policies, and legacy, composable and component templates to data tiers routing
- Ingest APIs
- Info API
- Licensing APIs
- Logstash APIs
- Machine learning APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get model snapshots
- Get model snapshot upgrade statistics
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Reset jobs
- Revert model snapshots
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Upgrade model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Delete data frame analytics jobs
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Preview data frame analytics
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Update data frame analytics jobs
- Machine learning trained model APIs
- Clear trained model deployment cache
- Create or update trained model aliases
- Create part of a trained model
- Create trained models
- Create trained model vocabulary
- Delete trained model aliases
- Delete trained models
- Get trained models
- Get trained models stats
- Infer trained model
- Start trained model deployment
- Stop trained model deployment
- Update trained model deployment
- Migration APIs
- Node lifecycle APIs
- Query rules APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Script APIs
- Search APIs
- Search Application APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Clear service account token caches
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Create service account tokens
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete service account token
- Delete users
- Disable users
- Enable users
- Enroll Kibana
- Enroll node
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get service accounts
- Get service account credentials
- Get token
- Get user privileges
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- Query API key information
- Update API key
- Bulk update API keys
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SAML complete logout
- SAML service provider metadata
- SSL certificate
- Activate user profile
- Disable user profile
- Enable user profile
- Get user profiles
- Suggest user profile
- Update user profile data
- Has privileges user profile
- Create Cross-Cluster API key
- Update Cross-Cluster API key
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- SQL APIs
- Synonyms APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Migration guide
- Release notes
- Elasticsearch version 8.10.4
- Elasticsearch version 8.10.3
- Elasticsearch version 8.10.2
- Elasticsearch version 8.10.1
- Elasticsearch version 8.10.0
- Elasticsearch version 8.9.2
- Elasticsearch version 8.9.1
- Elasticsearch version 8.9.0
- Elasticsearch version 8.8.2
- Elasticsearch version 8.8.1
- Elasticsearch version 8.8.0
- Elasticsearch version 8.7.1
- Elasticsearch version 8.7.0
- Elasticsearch version 8.6.2
- Elasticsearch version 8.6.1
- Elasticsearch version 8.6.0
- Elasticsearch version 8.5.3
- Elasticsearch version 8.5.2
- Elasticsearch version 8.5.1
- Elasticsearch version 8.5.0
- Elasticsearch version 8.4.3
- Elasticsearch version 8.4.2
- Elasticsearch version 8.4.1
- Elasticsearch version 8.4.0
- Elasticsearch version 8.3.3
- Elasticsearch version 8.3.2
- Elasticsearch version 8.3.1
- Elasticsearch version 8.3.0
- Elasticsearch version 8.2.3
- Elasticsearch version 8.2.2
- Elasticsearch version 8.2.1
- Elasticsearch version 8.2.0
- Elasticsearch version 8.1.3
- Elasticsearch version 8.1.2
- Elasticsearch version 8.1.1
- Elasticsearch version 8.1.0
- Elasticsearch version 8.0.1
- Elasticsearch version 8.0.0
- Elasticsearch version 8.0.0-rc2
- Elasticsearch version 8.0.0-rc1
- Elasticsearch version 8.0.0-beta1
- Elasticsearch version 8.0.0-alpha2
- Elasticsearch version 8.0.0-alpha1
- Dependencies and versions
How Watcher works
editHow Watcher works
editYou add watches to automatically perform an action when certain conditions are met. The conditions are generally based on data you’ve loaded into the watch, also known as the Watch Payload. This payload can be loaded from different sources - from Elasticsearch, an external HTTP service, or even a combination of the two.
For example, you could configure a watch to send an email to the sysadmin when a search in the logs data indicates that there are too many 503 errors in the last 5 minutes.
This topic describes the elements of a watch and how watches operate.
Watch definition
editA watch consists of a trigger, input, condition, and actions. The actions define what needs to be done once the condition is met. In addition, you can define conditions and transforms to process and prepare the watch payload before executing the actions.
- Trigger
- Determines when the watch is checked. A watch must have a trigger.
- Input
- Loads data into the watch payload. If no input is specified, an empty payload is loaded.
- Condition
-
Controls whether the watch actions are executed. If no condition is specified,
the condition defaults to
always. - Transform
- Processes the watch payload to prepare it for the watch actions. You can define transforms at the watch level or define action-specific transforms. Optional.
- Actions
- Specify what happens when the watch condition is met.
For example, the following snippet shows a create or update watch request that defines a watch that looks for log error events:
PUT _watcher/watch/log_errors { "metadata" : { "color" : "red" }, "trigger" : { "schedule" : { "interval" : "5m" } }, "input" : { "search" : { "request" : { "indices" : "log-events", "body" : { "size" : 0, "query" : { "match" : { "status" : "error" } } } } } }, "condition" : { "compare" : { "ctx.payload.hits.total" : { "gt" : 5 }} }, "transform" : { "search" : { "request" : { "indices" : "log-events", "body" : { "query" : { "match" : { "status" : "error" } } } } } }, "actions" : { "my_webhook" : { "webhook" : { "method" : "POST", "host" : "mylisteninghost", "port" : 9200, "path" : "/{{watch_id}}", "body" : "Encountered {{ctx.payload.hits.total}} errors" } }, "email_administrator" : { "email" : { "to" : "sys.admino@host.domain", "subject" : "Encountered {{ctx.payload.hits.total}} errors", "body" : "Too many error in the system, see attached data", "attachments" : { "attached_data" : { "data" : { "format" : "json" } } }, "priority" : "high" } } } }
|
Metadata - You can attach optional static metadata to a watch. |
|
|
Trigger - This schedule trigger executes the watch every 5 minutes. |
|
|
Input - This input searches for errors in the |
|
|
Condition - This condition checks to see if there are more than 5 error
events (hits in the search response). If there are, execution
continues for all |
|
|
Transform - If the watch condition is met, this transform loads all of the
errors into the watch payload by searching for the errors using
the default search type, |
|
|
Actions - This watch has two actions. The |
Watch execution
editWhen you add a watch, Watcher immediately registers its trigger with the
appropriate trigger engine. Watches that have a schedule trigger are
registered with the scheduler trigger engine.
The scheduler tracks time and triggers watches according to their schedules.
On each node, that contains one of the .watches shards, a scheduler, that is
bound to the watcher lifecycle runs. Even though all primaries and replicas are
taken into account, when a watch is triggered, watcher also ensures, that each
watch is only triggered on one of those shards. The more replica shards you
add, the more distributed the watches can be executed. If you add or remove
replicas, all watches need to be reloaded. If a shard is relocated, the
primary and all replicas of this particular shard will reload.
Because the watches are executed on the node, where the watch shards are, you can create dedicated watcher nodes by using shard allocation filtering.
You could configure nodes with a dedicated node.attr.role: watcher property and
then configure the .watches index like this:
response = client.indices.put_settings( index: '.watches', body: { "index.routing.allocation.include.role": 'watcher' } ) puts response
PUT .watches/_settings { "index.routing.allocation.include.role": "watcher" }
When the Watcher service is stopped, the scheduler stops with it. Trigger engines use a separate thread pool from the one used to execute watches.
When a watch is triggered, Watcher queues it up for execution. A watch_record
document is created and added to the watch history and the watch’s status is set
to awaits_execution.
When execution starts, Watcher creates a watch execution context for the watch. The execution context provides scripts and templates with access to the watch metadata, payload, watch ID, execution time, and trigger information. For more information, see Watch Execution Context.
During the execution process, Watcher:
- Loads the input data as the payload in the watch execution context. This makes the data available to all subsequent steps in the execution process. This step is controlled by the input of the watch.
-
Evaluates the watch condition to determine whether or not to continue processing
the watch. If the condition is met (evaluates to
true), processing advances to the next step. If it is not met (evaluates tofalse), execution of the watch stops. - Applies transforms to the watch payload (if needed).
- Executes the watch actions granted the condition is met and the watch is not throttled.
When the watch execution finishes, the execution result is recorded as a Watch Record in the watch history. The watch record includes the execution time and duration, whether the watch condition was met, and the status of each action that was executed.
The following diagram shows the watch execution process:
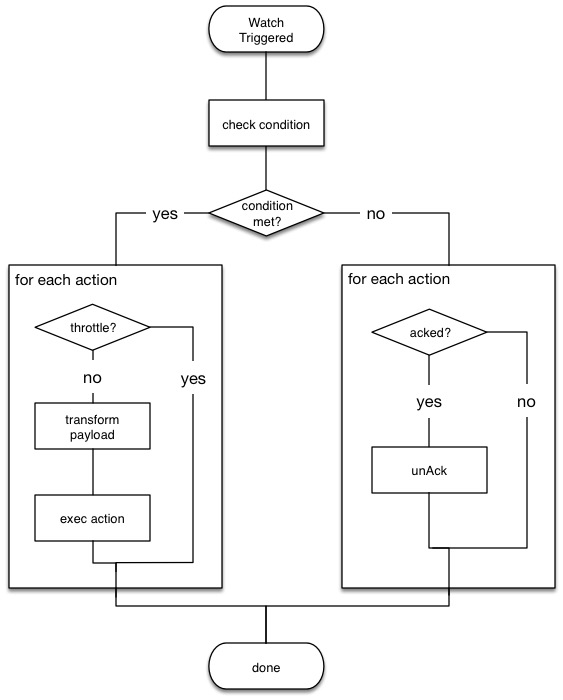
Watch acknowledgment and throttling
editWatcher supports both time-based and acknowledgment-based throttling. This enables you to prevent actions from being repeatedly executed for the same event.
By default, Watcher uses time-based throttling with a throttle period of 5 seconds. This means that if a watch is executed every second, its actions are performed a maximum of once every 5 seconds, even when the condition is always met. You can configure the throttle period on a per-action basis or at the watch level.
Acknowledgment-based throttling enables you to tell Watcher not to send any more
notifications about a watch as long as its condition is met. Once the condition
evaluates to false, the acknowledgment is cleared and Watcher resumes executing
the watch actions normally.
For more information, see Acknowledgement and throttling.
Watch active state
editBy default, when you add a watch it is immediately set to the active state, registered with the appropriate trigger engine, and executed according to its configured trigger.
You can also set a watch to the inactive state. Inactive watches are not registered with a trigger engine and can never be triggered.
To set a watch to the inactive state when you create it, set the
active parameter to inactive. To
deactivate an existing watch, use the
deactivate watch API. To reactivate an
inactive watch, use the
activate watch API.
You can use the execute watch API to force the execution of a watch even when it is inactive.
Deactivating watches is useful in a variety of situations. For example, if you have a watch that monitors an external system and you need to take that system down for maintenance, you can deactivate the watch to prevent it from falsely reporting availability issues during the maintenance window.
Deactivating a watch also enables you to keep it around for future use without deleting it from the system.
Scripts and templates
editYou can use scripts and templates when defining a watch. Scripts and templates can reference elements in the watch execution context, including the watch payload. The execution context defines variables you can use in a script and parameter placeholders in a template.
Watcher uses the Elasticsearch script infrastructure, which supports inline and stored. Scripts and templates are compiled and cached by Elasticsearch to optimize recurring execution. Autoloading is also supported. For more information, see Scripting and How to write scripts.
Watch execution context
editThe following snippet shows the basic structure of the Watch Execution Context:
{ "ctx" : { "metadata" : { ... }, "payload" : { ... }, "watch_id" : "<id>", "execution_time" : "20150220T00:00:10Z", "trigger" : { "triggered_time" : "20150220T00:00:10Z", "scheduled_time" : "20150220T00:00:00Z" }, "vars" : { ... } }
|
Any static metadata specified in the watch definition. |
|
|
The current watch payload. |
|
|
The id of the executing watch. |
|
|
A timestamp that shows when the watch execution started. |
|
|
Information about the trigger event. For a |
|
|
Dynamic variables that can be set and accessed by different constructs during the execution. These variables are scoped to a single execution (i.e they’re not persisted and can’t be used between different executions of the same watch) |
Using scripts
editYou can use scripts to define conditions and transforms. The default scripting language is Painless.
Starting with 5.0, Elasticsearch is shipped with the new Painless scripting language. Painless was created and designed specifically for use in Elasticsearch. Beyond providing an extensive feature set, its biggest trait is that it’s properly sandboxed and safe to use anywhere in the system (including in Watcher) without the need to enable dynamic scripting.
Scripts can reference any of the values in the watch execution context or values explicitly passed through script parameters.
For example, if the watch metadata contains a color field
(e.g. "metadata" : {"color": "red"}), you can access its value with the via the
ctx.metadata.color variable. If you pass in a color parameter as part of the
condition or transform definition (e.g. "params" : {"color": "red"}), you can
access its value via the color variable.
Using templates
editYou use templates to define dynamic content for a watch. At execution time,
templates pull in data from the watch execution context. For example, you can use
a template to populate the subject field for an email action with data stored
in the watch payload. Templates can also access values explicitly passed through
template parameters.
You specify templates using the Mustache scripting language.
For example, the following snippet shows how templates enable dynamic subjects in sent emails:
{ "actions" : { "email_notification" : { "email" : { "subject" : "{{ctx.metadata.color}} alert" } } } }
Inline templates and scripts
editTo define an inline template or script, you simply specify it directly in the
value of a field. For example, the following snippet configures the subject of
the email action using an inline template that references the color value in
the context metadata.
"actions" : { "email_notification" : { "email" : { "subject" : "{{ctx.metadata.color}} alert" } } } }
For a script, you simply specify the inline script as the value of the script
field. For example:
"condition" : { "script" : "return true" }
You can also explicitly specify the inline type by using a formal object definition as the field value. For example:
"actions" : { "email_notification" : { "email" : { "subject" : { "source" : "{{ctx.metadata.color}} alert" } } } }
The formal object definition for a script would be:
"condition" : { "script" : { "source": "return true" } }
Stored templates and scripts
editIf you store your templates and scripts, you can reference them by id.
To reference a stored script or template, you use the formal object definition
and specify its id in the id field. For example, the following snippet
references the email_notification_subject template:
{ ... "actions" : { "email_notification" : { "email" : { "subject" : { "id" : "email_notification_subject", "params" : { "color" : "red" } } } } } }
On this page