Elastic Search: 웹사이트에 검색을 추가하세요
개요
Elastic Search 소개
Elastic Search에 대해 좀 더 숙지하시면서 Elastic Cloud를 통해 데이터를 수집하고 확인하는 방법에 대한 개요를 더 자세히 알아보세요.
데이터 온보딩
Elastic Search 빠른 시작
이 3개의 빠른 시작 동영상 시리즈에서는, 앱과 웹사이트를 위해 미리 조정된 정확도를 갖춘 현대적이고 자연스러운 검색 환경인 Elastic Search에 대해 알아보시게 됩니다. 설정, 데이터 수집, 검색 인터페이스 찾기, 필요에 따라 검색 엔진 분석 및 조정 작업을 얼마나 빨리 수행할 수 있는지 확인하세요. Elastic Search란 무엇인가, Elastic Search로 데이터 색인, 검색 분석 및 개선 등의 주제를 다루게 됩니다.
Elastic Cloud 계정 생성하기
14일 체험판으로 시작해 보세요. cloud.elastic.co에 접속하여 계정을 생성한 후에, 아래 단계를 따라 전 세계 50개 이상의 지원 리전 중 하나에서 Elastic 스택을 처음 시작하는 방법에 대해 알아보세요.
Edit setting(편집 설정)을 클릭하면 Google Cloud, Microsoft Azure, AWS 등 클라우드 서비스 제공자를 선택하실 수 있습니다. 클라우드 서비스 제공자를 선택하고 나면, 관련 리전을 선택하실 수 있게 됩니다. 다음으로, 몇 가지 하드웨어 프로파일 중에서 선택하여 필요에 따라 원하는 대로 배포를 사용자 정의할 수 있는 옵션이 있습니다. 또한 최신 버전의 Elastic이 이미 미리 선택되어 있습니다.
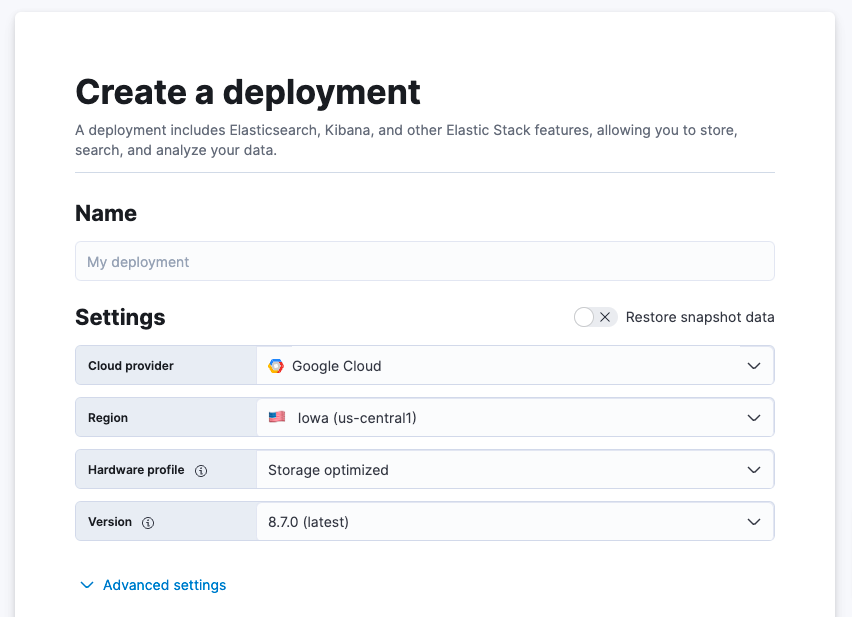
이 사용 사례의 경우, 4GB RAM 인스턴스가 필요합니다. 이를 생성하려면, Advanced settings(고급 설정)를 선택한 다음, 아래의 Enterprise Search 인스턴스로 스크롤하고 드롭다운을 선택하여 배포를 생성하기 전에 Size per zone(영역당 크기)을 4GB RAM으로 늘립니다. 이 작업을 완료한 후 Create deployment(배포 생성하기)를 선택하실 수 있습니다.
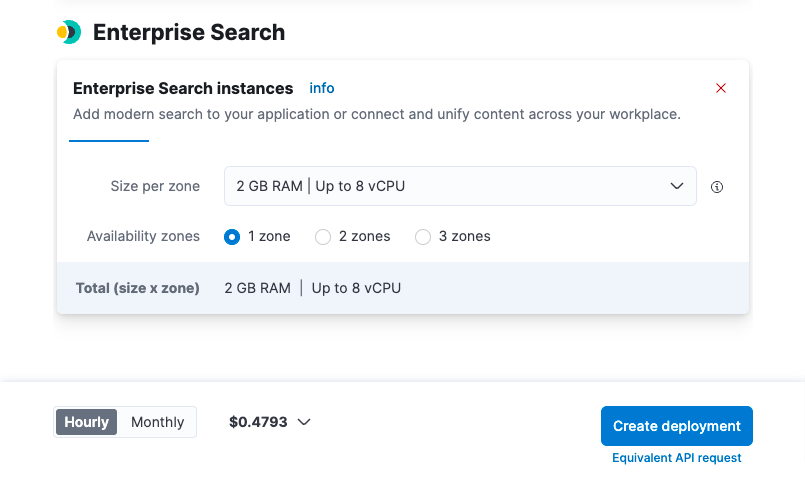
배포가 생성되는 동안, 사용자 이름과 비밀번호가 제공됩니다. 통합을 설치할 때 필요할 경우 이것을 복사하거나 다운로드해야 합니다.
Elastic Web Crawler를 사용하여 데이터 수집하기
배포를 생성했으므로, 이제 데이터를 Elastic으로 가져올 차례입니다. Elastic의 Web Crawler를 사용하여 이 작업을 해보겠습니다. 먼저, Add search to my website(내 웹사이트에 검색 추가) 타일을 선택합니다.
그런 다음, 나타나는 플라이휠에서 Start(시작)을 선택합니다.
웹 크롤러를 설정하려면, 이 가이드 투어를 확인하거나 아래 지침을 따르세요.
이제 인덱스를 생성합니다. 이 안내서의 목적을 위해, 저는 elastic.co 전체에서 블로그를 수집하겠습니다.
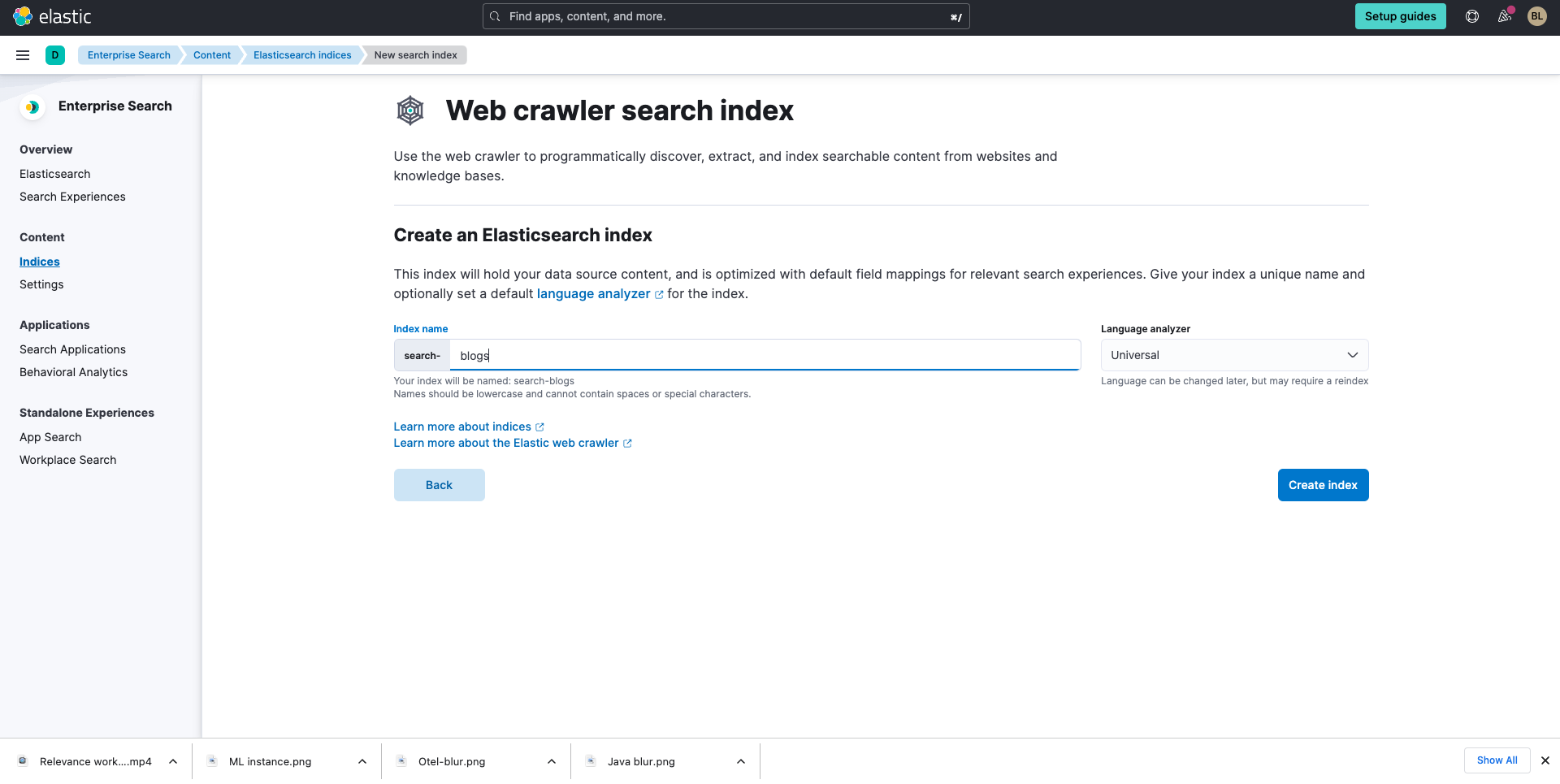
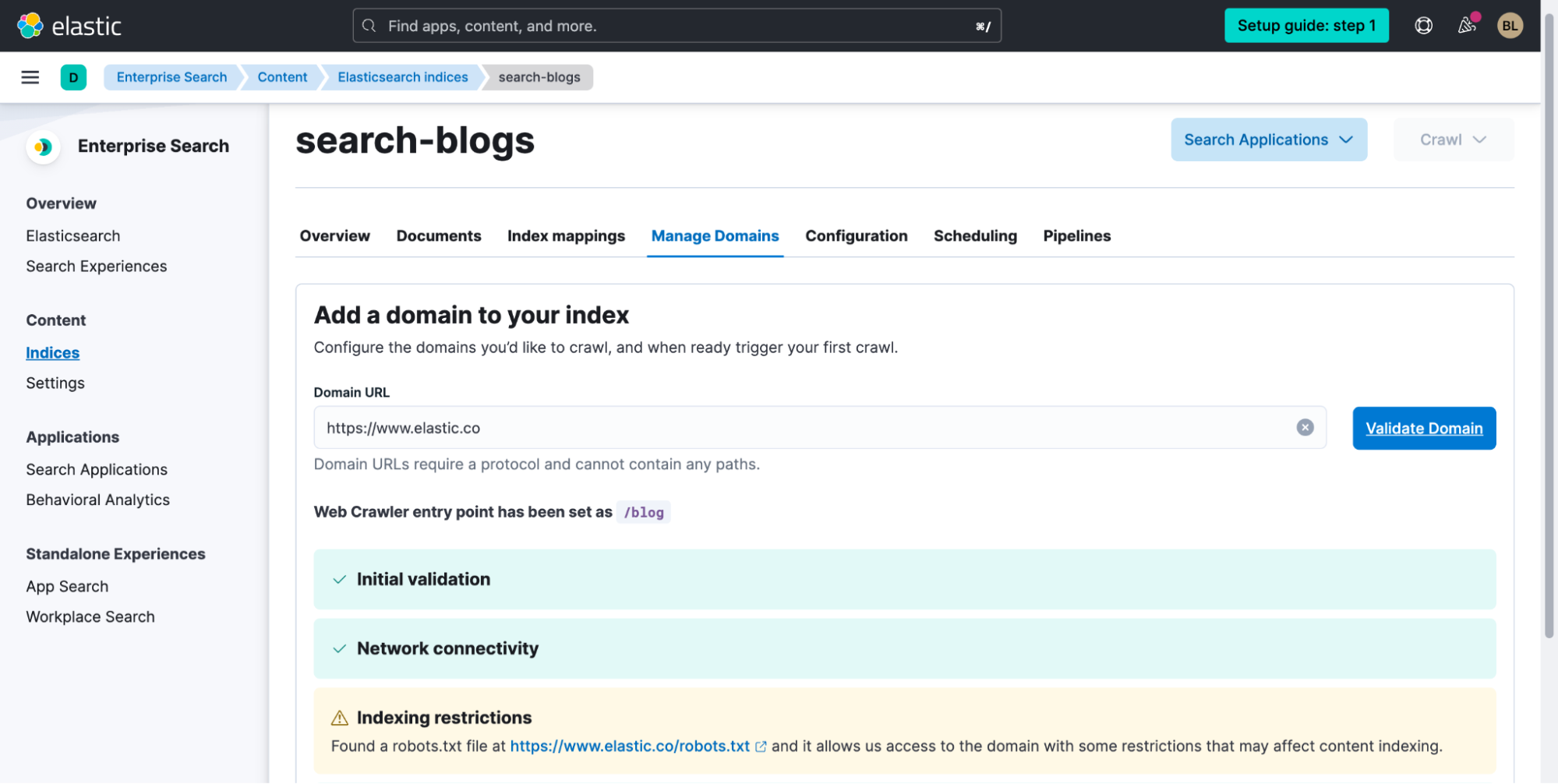
인덱스에 이름을 지정한 후 Create index(인덱스 생성)를 선택합니다. 다음으로, Validate Domain(도메인 유효성 검사)을 한 다음 Add domain(도메인 추가)을 합니다.
오른쪽 하단에서 도메인을 추가한 후 Edit(편집)을 선택하면 필요한 경우 하위 도메인을 추가할 수 있습니다.
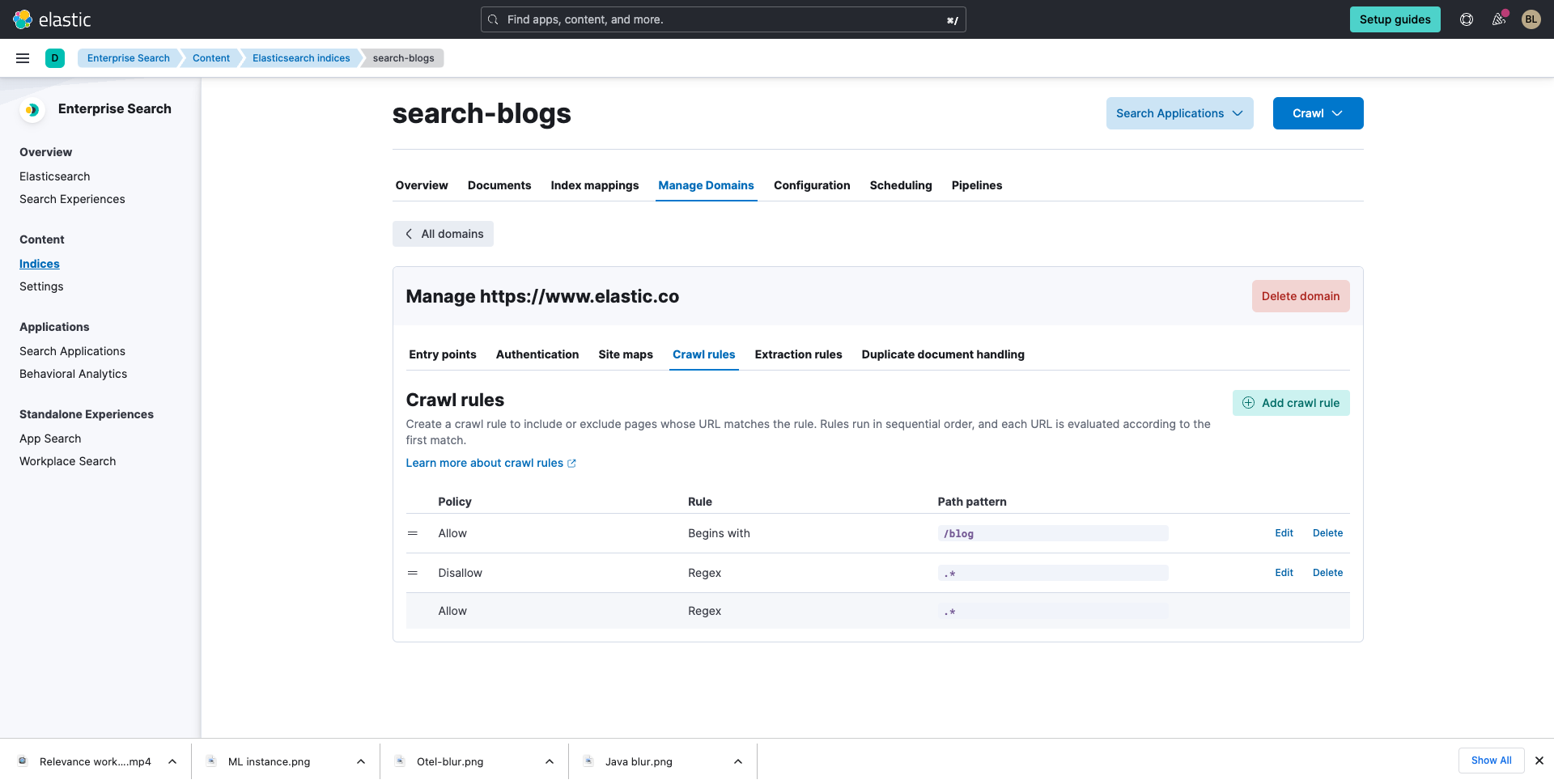
다음으로, Crawl rules(크롤링 규칙)를 선택하고 아래와 같이 크롤링 규칙을 추가합니다.*
Elasticsearch를 사용하여 데이터베이스에 연결하기
또 다른 옵션은 데이터베이스에서 콘텐츠를 추가하는 것입니다. 이를 위해 수집 방법으로 Use a connector(커넥터 사용)를 선택합니다.
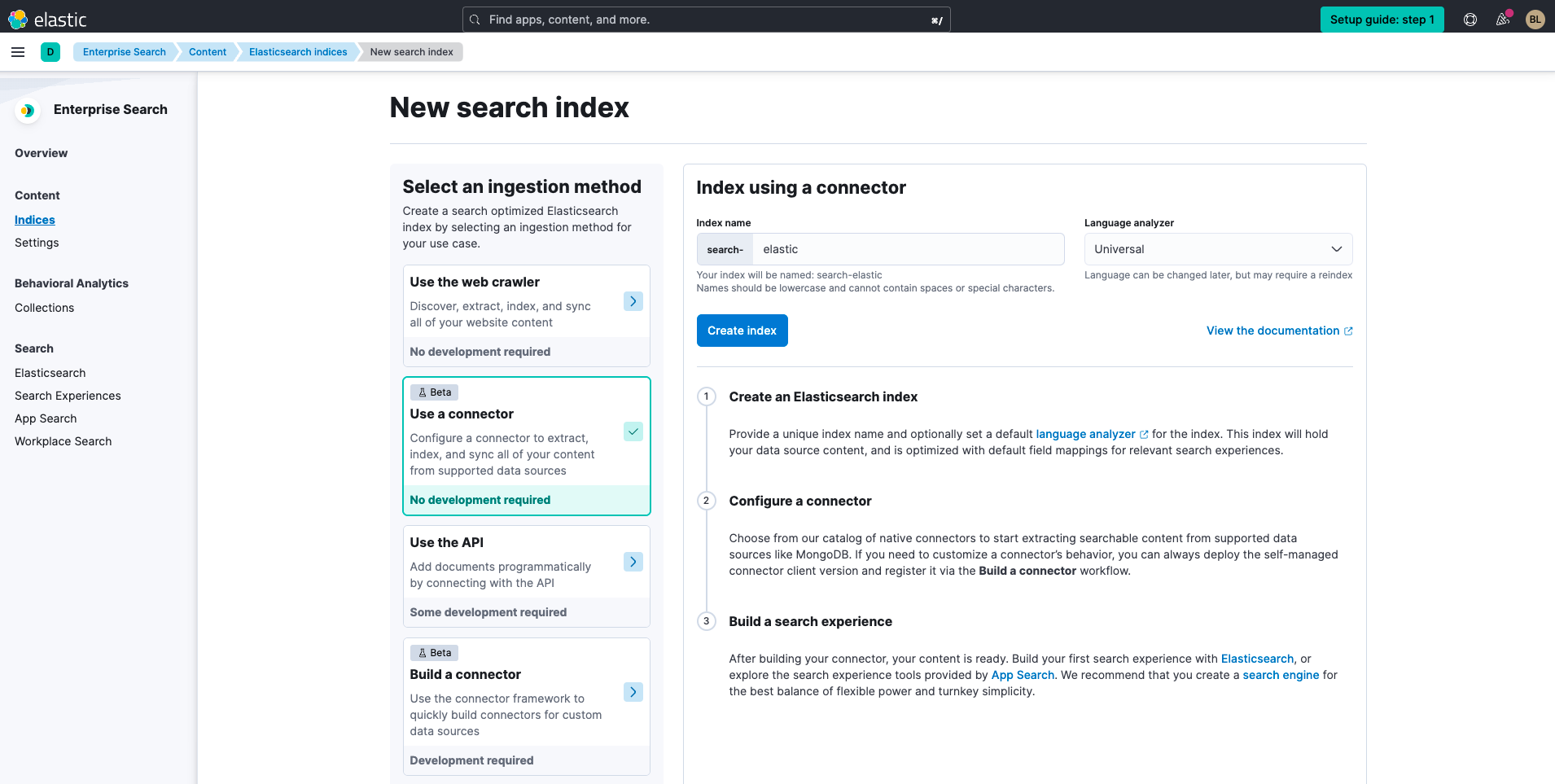
다음으로 MongoDB를 선택하고 MongoDB 커넥터의 구성에서 위에서 수집한 정보를 입력합니다. 지정된 특정 호스트에 대해 읽기를 강제할 이유가 없는 한 'Direct connection(직접 연결)'을 'false'로 설정해야 합니다(자세한 내용은 MongoDB connection guide(MongoDB 연결 가이드) 참조)
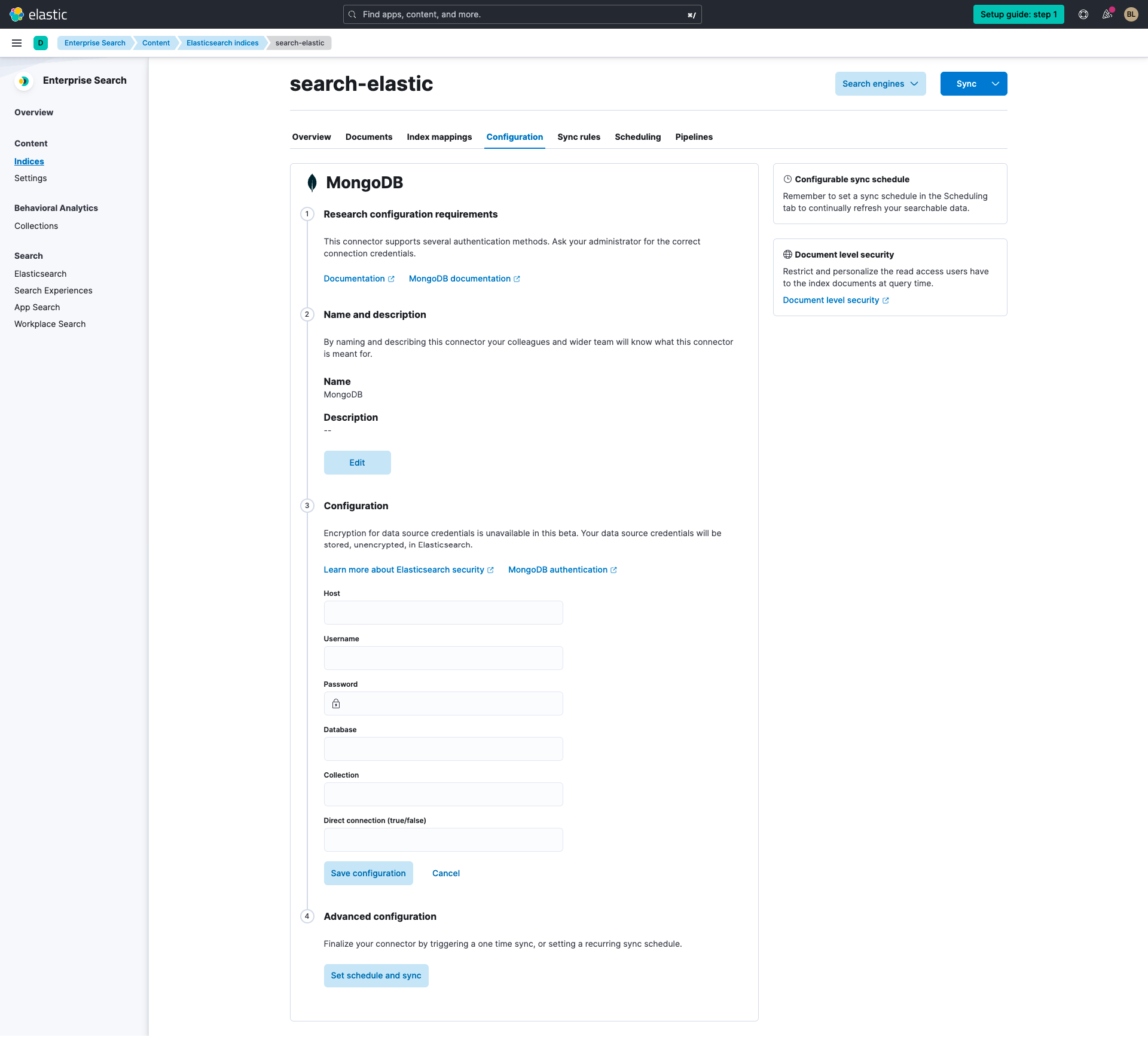
정보를 입력한 후 Scheduling(스케줄링) 탭을 선택하여 사용 사례에 대해 선호하는 데이터베이스 동기화 일정을 설정합니다. 예약 옵션을 구성한 후, Sync(동기화)를 클릭하여 프로세스를 완료합니다.
Elastic과 협력하기
벡터 검색을 활용하여 검색 경험 구축
검색 경험의 일부로 벡터 검색 사용을 생각 중이신가요? Elastic에는 "밀집 벡터"(일명, k-최근접 유사 항목(kNN) 벡터 검색)와 Elastic의 Learned Sparse Encoder(ELSER) 같은 "희소 벡터", 이렇게 두 가지 형태의 벡터 검색이 있습니다.
희소 벡터 검색은 시작하기에 더 간단한 옵션입니다. Elastic은 시맨틱 검색을 위해 즉시 사용 가능한 모델인 Learned Sparse Encoder 모델을 제공합니다. 이 모델은 금융 데이터, 날씨 기록, 질문과 답변 등 다양한 데이터 세트에서 성능이 뛰어납니다. 이 모델은 추가적인 미세 조정 없이 도메인 전반에 걸쳐 높은 정확도를 제공하도록 구축되었습니다.
이 대화형 데모를 통해 Elastic의 텍스트 BM25 알고리즘에 대해 Elastic의 Learned Sparse Encoder 모델을 테스트할 때 검색 결과가 어떻게 더 정확한지 알아보세요.
또한 Elastic은 동영상, 이미지, 오디오 등 텍스트 이외의 비정형 데이터에 대한 유사성 검색을 구현하기 위해 k-최근접 유사 항목(kNN) 벡터도 지원합니다.
시맨틱 검색과 벡터 검색의 장점은 이러한 기술을 통해 고객이 검색 쿼리에서 직관적인 언어를 사용할 수 있다는 것입니다. 예를 들어, 부수입에 대한 회사 지침을 검색하려는 경우, 공식적인 HR 문서에서는 볼 수 없는 용어인 "부업(side hustle)"을 검색할 수 있습니다.
벡터 검색을 사용하여 시맨틱 검색 경험 구축을 시작하려면, 이 단계별 안내서를 살펴보세요.
데이터를 활용하여 검색 개선
검색 경험을 구축하고 실행한 후에는 어떻게 이를 개선할 수 있을까요? 행동 분석을 활용하여 웹사이트와 애플리케이션 전반에 걸친 사용자 참여를 분석하세요. 이 정보를 사용하여 검색 결과의 정확도를 높이고 콘텐츠에서 부족한 부분을 파악할 수 있습니다.
이 가이드 투어를 통해 행동 분석을 시작하는 방법을 알아보세요.
검색 준비를 이미 완료하고 한 단계 더 나아가려면, 검색 경험을 개인 맞춤화하는 데 대한 웨비나를 소개합니다.
또한 분석을 사용하여 검색 경험을 강화할 수 있는 방법에 대한 자세한 내용은 이 블로그를 확인하세요.
다음 단계
시간을 내셔서 Elastic Cloud를 통해 데이터베이스를 Elasticsearch에 연결해 주셔서 감사합니다. Elastic과 함께 하는 여정을 시작하면서, 환경 전체에 배포할 때 사용자로서 관리해야 하는 운영, 보안 및 데이터 구성 요소를 이해해야 합니다.