- Elasticsearch Guide: other versions:
- What is Elasticsearch?
- What’s new in 7.10
- Getting started with Elasticsearch
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Setting JVM options
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- HTTP
- Index lifecycle management settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Monitoring settings
- Node
- Network settings
- Node query cache settings
- Search settings
- Security settings
- Shard request cache settings
- Snapshot lifecycle management settings
- Transforms settings
- Transport
- Thread pools
- Watcher settings
- Important Elasticsearch configuration
- Important System Configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Set up X-Pack
- Configuring X-Pack Java Clients
- Plugins
- Upgrade Elasticsearch
- Index modules
- Mapping
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Index templates
- Data streams
- Ingest node
- Search your data
- Query DSL
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Geo-distance
- Geohash grid
- Geotile grid
- Global
- Histogram
- IP range
- Missing
- Nested
- Parent
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Bucket aggregations
- EQL
- SQL access
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Data management
- ILM: Manage the index lifecycle
- Overview
- Concepts
- Automate rollover
- Manage Filebeat time-based indices
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Resolve lifecycle policy execution errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Monitor a cluster
- Frozen indices
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure a cluster
- Overview
- Configuring security
- User authentication
- Built-in users
- Internal users
- Token-based authentication services
- Realms
- Realm chains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Granting access to Stack Management features
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and index aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enabling audit logging
- Encrypting communications
- Restricting connections with IP filtering
- Cross cluster search, clients, and integrations
- Tutorial: Getting started with security
- Tutorial: Encrypting communications
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Watch for cluster and index events
- Command line tools
- How To
- Glossary of terms
- REST APIs
- API conventions
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Nodes reload secure settings
- Nodes stats
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Cross-cluster replication APIs
- Data stream APIs
- Document APIs
- Enrich APIs
- Graph explore API
- Index APIs
- Add index alias
- Analyze
- Clear cache
- Clone index
- Close index
- Create index
- Delete index
- Delete index alias
- Delete component template
- Delete index template
- Delete index template (legacy)
- Flush
- Force merge
- Freeze index
- Get component template
- Get field mapping
- Get index
- Get index alias
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Index alias exists
- Index exists
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- Open index
- Put index template
- Put index template (legacy)
- Put component template
- Put mapping
- Refresh
- Rollover index
- Shrink index
- Simulate index
- Simulate template
- Split index
- Synced flush
- Type exists
- Unfreeze index
- Update index alias
- Update index settings
- Resolve index
- List dangling indices
- Import dangling index
- Delete dangling index
- Index lifecycle management APIs
- Ingest APIs
- Info API
- Licensing APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Find file structure
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get machine learning info
- Get model snapshots
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Revert model snapshots
- Set upgrade mode
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Create trained models
- Update data frame analytics jobs
- Delete data frame analytics jobs
- Delete trained models
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Get trained models
- Get trained models stats
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Migration APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Search APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete users
- Disable users
- Enable users
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get token
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SSL certificate
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Migration guide
- Release notes
- Elasticsearch version 7.10.2
- Elasticsearch version 7.10.1
- Elasticsearch version 7.10.0
- Elasticsearch version 7.9.3
- Elasticsearch version 7.9.2
- Elasticsearch version 7.9.1
- Elasticsearch version 7.9.0
- Elasticsearch version 7.8.1
- Elasticsearch version 7.8.0
- Elasticsearch version 7.7.1
- Elasticsearch version 7.7.0
- Elasticsearch version 7.6.2
- Elasticsearch version 7.6.1
- Elasticsearch version 7.6.0
- Elasticsearch version 7.5.2
- Elasticsearch version 7.5.1
- Elasticsearch version 7.5.0
- Elasticsearch version 7.4.2
- Elasticsearch version 7.4.1
- Elasticsearch version 7.4.0
- Elasticsearch version 7.3.2
- Elasticsearch version 7.3.1
- Elasticsearch version 7.3.0
- Elasticsearch version 7.2.1
- Elasticsearch version 7.2.0
- Elasticsearch version 7.1.1
- Elasticsearch version 7.1.0
- Elasticsearch version 7.0.0
- Elasticsearch version 7.0.0-rc2
- Elasticsearch version 7.0.0-rc1
- Elasticsearch version 7.0.0-beta1
- Elasticsearch version 7.0.0-alpha2
- Elasticsearch version 7.0.0-alpha1
- Dependencies and versions
Rare terms aggregation
editRare terms aggregation
editA multi-bucket value source based aggregation which finds "rare" terms — terms that are at the long-tail
of the distribution and are not frequent. Conceptually, this is like a terms aggregation that is
sorted by _count ascending. As noted in the terms aggregation docs,
actually ordering a terms agg by count ascending has unbounded error. Instead, you should use the rare_terms
aggregation
Syntax
editA rare_terms aggregation looks like this in isolation:
{ "rare_terms": { "field": "the_field", "max_doc_count": 1 } }
Table 40. rare_terms Parameters
Parameter Name |
Description |
Required |
Default Value |
|
The field we wish to find rare terms in |
Required |
|
|
The maximum number of documents a term should appear in. |
Optional |
|
|
The precision of the internal CuckooFilters. Smaller precision leads to
better approximation, but higher memory usage. Cannot be smaller than |
Optional |
|
|
Terms that should be included in the aggregation |
Optional |
|
|
Terms that should be excluded from the aggregation |
Optional |
|
|
The value that should be used if a document does not have the field being aggregated |
Optional |
Example:
GET /_search { "aggs": { "genres": { "rare_terms": { "field": "genre" } } } }
Response:
{ ... "aggregations": { "genres": { "buckets": [ { "key": "swing", "doc_count": 1 } ] } } }
In this example, the only bucket that we see is the "swing" bucket, because it is the only term that appears in
one document. If we increase the max_doc_count to 2, we’ll see some more buckets:
GET /_search { "aggs": { "genres": { "rare_terms": { "field": "genre", "max_doc_count": 2 } } } }
This now shows the "jazz" term which has a doc_count of 2":
{ ... "aggregations": { "genres": { "buckets": [ { "key": "swing", "doc_count": 1 }, { "key": "jazz", "doc_count": 2 } ] } } }
Maximum document count
editThe max_doc_count parameter is used to control the upper bound of document counts that a term can have. There
is not a size limitation on the rare_terms agg like terms agg has. This means that terms
which match the max_doc_count criteria will be returned. The aggregation functions in this manner to avoid
the order-by-ascending issues that afflict the terms aggregation.
This does, however, mean that a large number of results can be returned if chosen incorrectly.
To limit the danger of this setting, the maximum max_doc_count is 100.
Max Bucket Limit
editThe Rare Terms aggregation is more liable to trip the search.max_buckets soft limit than other aggregations due
to how it works. The max_bucket soft-limit is evaluated on a per-shard basis while the aggregation is collecting
results. It is possible for a term to be "rare" on a shard but become "not rare" once all the shard results are
merged together. This means that individual shards tend to collect more buckets than are truly rare, because
they only have their own local view. This list is ultimately pruned to the correct, smaller list of rare
terms on the coordinating node… but a shard may have already tripped the max_buckets soft limit and aborted
the request.
When aggregating on fields that have potentially many "rare" terms, you may need to increase the max_buckets soft
limit. Alternatively, you might need to find a way to filter the results to return fewer rare values (smaller time
span, filter by category, etc), or re-evaluate your definition of "rare" (e.g. if something
appears 100,000 times, is it truly "rare"?)
Document counts are approximate
editThe naive way to determine the "rare" terms in a dataset is to place all the values in a map, incrementing counts
as each document is visited, then return the bottom n rows. This does not scale beyond even modestly sized data
sets. A sharded approach where only the "top n" values are retained from each shard (ala the terms aggregation)
fails because the long-tail nature of the problem means it is impossible to find the "top n" bottom values without
simply collecting all the values from all shards.
Instead, the Rare Terms aggregation uses a different approximate algorithm:
- Values are placed in a map the first time they are seen.
- Each addition occurrence of the term increments a counter in the map
-
If the counter > the
max_doc_countthreshold, the term is removed from the map and placed in a CuckooFilter - The CuckooFilter is consulted on each term. If the value is inside the filter, it is known to be above the threshold already and skipped.
After execution, the map of values is the map of "rare" terms under the max_doc_count threshold. This map and CuckooFilter
are then merged with all other shards. If there are terms that are greater than the threshold (or appear in
a different shard’s CuckooFilter) the term is removed from the merged list. The final map of values is returned
to the user as the "rare" terms.
CuckooFilters have the possibility of returning false positives (they can say a value exists in their collection when it actually does not). Since the CuckooFilter is being used to see if a term is over threshold, this means a false positive from the CuckooFilter will mistakenly say a value is common when it is not (and thus exclude it from it final list of buckets). Practically, this means the aggregations exhibits false-negative behavior since the filter is being used "in reverse" of how people generally think of approximate set membership sketches.
CuckooFilters are described in more detail in the paper:
Fan, Bin, et al. "Cuckoo filter: Practically better than bloom." Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies. ACM, 2014.
Precision
editAlthough the internal CuckooFilter is approximate in nature, the false-negative rate can be controlled with a
precision parameter. This allows the user to trade more runtime memory for more accurate results.
The default precision is 0.001, and the smallest (e.g. most accurate and largest memory overhead) is 0.00001.
Below are some charts which demonstrate how the accuracy of the aggregation is affected by precision and number
of distinct terms.
The X-axis shows the number of distinct values the aggregation has seen, and the Y-axis shows the percent error.
Each line series represents one "rarity" condition (ranging from one rare item to 100,000 rare items). For example,
the orange "10" line means ten of the values were "rare" (doc_count == 1), out of 1-20m distinct values (where the
rest of the values had doc_count > 1)
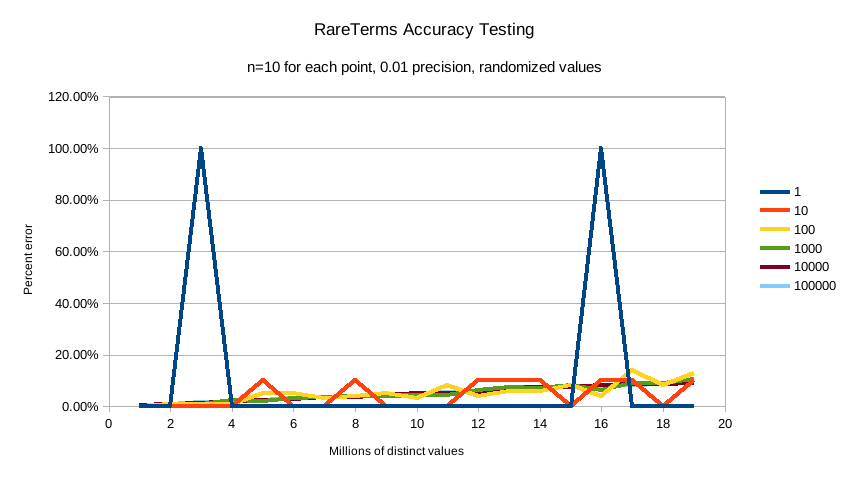
This first chart shows precision 0.01:
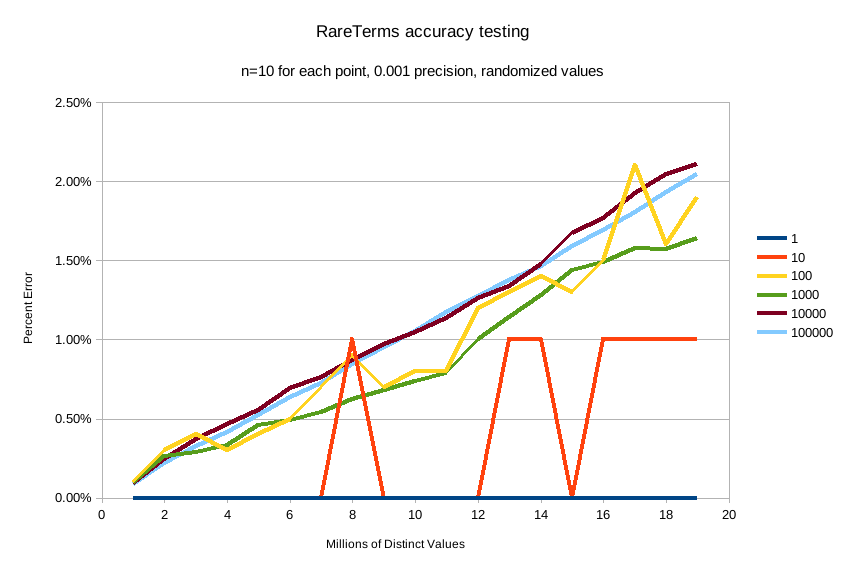
And precision 0.001 (the default):
And finally precision 0.0001:
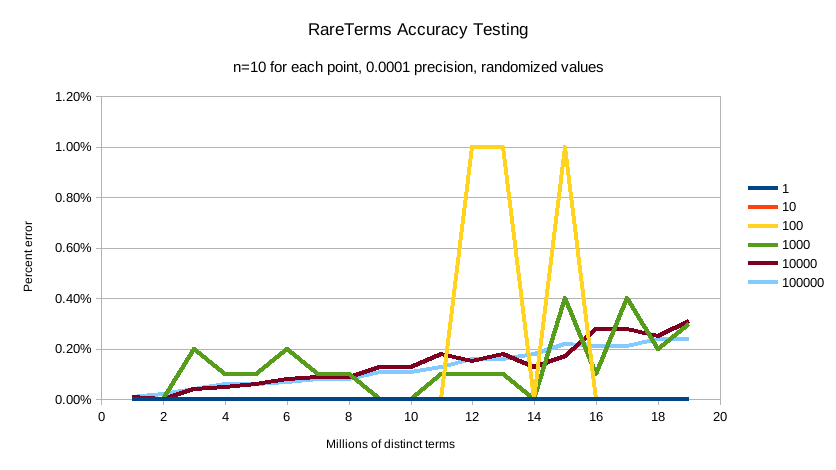
The default precision of 0.001 maintains an accuracy of < 2.5% for the tested conditions, and accuracy slowly
degrades in a controlled, linear fashion as the number of distinct values increases.
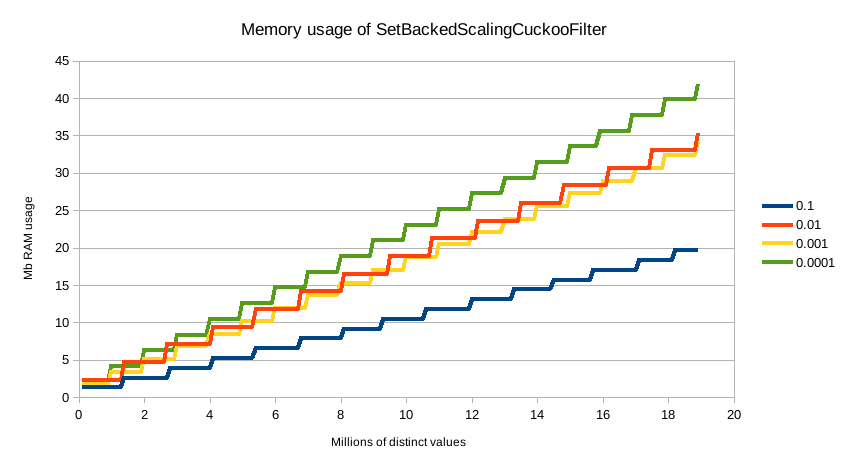
The default precision of 0.001 has a memory profile of 1.748⁻⁶ * n bytes, where n is the number
of distinct values the aggregation has seen (it can also be roughly eyeballed, e.g. 20 million unique values is about
30mb of memory). The memory usage is linear to the number of distinct values regardless of which precision is chosen,
the precision only affects the slope of the memory profile as seen in this chart:
For comparison, an equivalent terms aggregation at 20 million buckets would be roughly
20m * 69b == ~1.38gb (with 69 bytes being a very optimistic estimate of an empty bucket cost, far lower than what
the circuit breaker accounts for). So although the rare_terms agg is relatively heavy, it is still orders of
magnitude smaller than the equivalent terms aggregation
Filtering Values
editIt is possible to filter the values for which buckets will be created. This can be done using the include and
exclude parameters which are based on regular expression strings or arrays of exact values. Additionally,
include clauses can filter using partition expressions.
Filtering Values with regular expressions
editGET /_search { "aggs": { "genres": { "rare_terms": { "field": "genre", "include": "swi*", "exclude": "electro*" } } } }
In the above example, buckets will be created for all the tags that starts with swi, except those starting
with electro (so the tag swing will be aggregated but not electro_swing). The include regular expression will determine what
values are "allowed" to be aggregated, while the exclude determines the values that should not be aggregated. When
both are defined, the exclude has precedence, meaning, the include is evaluated first and only then the exclude.
The syntax is the same as regexp queries.
Filtering Values with exact values
editFor matching based on exact values the include and exclude parameters can simply take an array of
strings that represent the terms as they are found in the index:
GET /_search { "aggs": { "genres": { "rare_terms": { "field": "genre", "include": [ "swing", "rock" ], "exclude": [ "jazz" ] } } } }
Missing value
editThe missing parameter defines how documents that are missing a value should be treated.
By default they will be ignored but it is also possible to treat them as if they
had a value.
Nested, RareTerms, and scoring sub-aggregations
editThe RareTerms aggregation has to operate in breadth_first mode, since it needs to prune terms as doc count thresholds
are breached. This requirement means the RareTerms aggregation is incompatible with certain combinations of aggregations
that require depth_first. In particular, scoring sub-aggregations that are inside a nested force the entire aggregation tree to run
in depth_first mode. This will throw an exception since RareTerms is unable to process depth_first.
As a concrete example, if rare_terms aggregation is the child of a nested aggregation, and one of the child aggregations of rare_terms
needs document scores (like a top_hits aggregation), this will throw an exception.
On this page