- Elasticsearch Guide: other versions:
- What is Elasticsearch?
- What’s new in 7.10
- Getting started with Elasticsearch
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Setting JVM options
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- HTTP
- Index lifecycle management settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Monitoring settings
- Node
- Network settings
- Node query cache settings
- Search settings
- Security settings
- Shard request cache settings
- Snapshot lifecycle management settings
- Transforms settings
- Transport
- Thread pools
- Watcher settings
- Important Elasticsearch configuration
- Important System Configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Set up X-Pack
- Configuring X-Pack Java Clients
- Plugins
- Upgrade Elasticsearch
- Index modules
- Mapping
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Index templates
- Data streams
- Ingest node
- Search your data
- Query DSL
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Geo-distance
- Geohash grid
- Geotile grid
- Global
- Histogram
- IP range
- Missing
- Nested
- Parent
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Bucket aggregations
- EQL
- SQL access
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Data management
- ILM: Manage the index lifecycle
- Overview
- Concepts
- Automate rollover
- Manage Filebeat time-based indices
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Resolve lifecycle policy execution errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Monitor a cluster
- Frozen indices
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure a cluster
- Overview
- Configuring security
- User authentication
- Built-in users
- Internal users
- Token-based authentication services
- Realms
- Realm chains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Granting access to Stack Management features
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and index aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enabling audit logging
- Encrypting communications
- Restricting connections with IP filtering
- Cross cluster search, clients, and integrations
- Tutorial: Getting started with security
- Tutorial: Encrypting communications
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Watch for cluster and index events
- Command line tools
- How To
- Glossary of terms
- REST APIs
- API conventions
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Nodes reload secure settings
- Nodes stats
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Cross-cluster replication APIs
- Data stream APIs
- Document APIs
- Enrich APIs
- Graph explore API
- Index APIs
- Add index alias
- Analyze
- Clear cache
- Clone index
- Close index
- Create index
- Delete index
- Delete index alias
- Delete component template
- Delete index template
- Delete index template (legacy)
- Flush
- Force merge
- Freeze index
- Get component template
- Get field mapping
- Get index
- Get index alias
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Index alias exists
- Index exists
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- Open index
- Put index template
- Put index template (legacy)
- Put component template
- Put mapping
- Refresh
- Rollover index
- Shrink index
- Simulate index
- Simulate template
- Split index
- Synced flush
- Type exists
- Unfreeze index
- Update index alias
- Update index settings
- Resolve index
- List dangling indices
- Import dangling index
- Delete dangling index
- Index lifecycle management APIs
- Ingest APIs
- Info API
- Licensing APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Find file structure
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get machine learning info
- Get model snapshots
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Revert model snapshots
- Set upgrade mode
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Create trained models
- Update data frame analytics jobs
- Delete data frame analytics jobs
- Delete trained models
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Get trained models
- Get trained models stats
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Migration APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Search APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete users
- Disable users
- Enable users
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get token
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SSL certificate
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Migration guide
- Release notes
- Elasticsearch version 7.10.2
- Elasticsearch version 7.10.1
- Elasticsearch version 7.10.0
- Elasticsearch version 7.9.3
- Elasticsearch version 7.9.2
- Elasticsearch version 7.9.1
- Elasticsearch version 7.9.0
- Elasticsearch version 7.8.1
- Elasticsearch version 7.8.0
- Elasticsearch version 7.7.1
- Elasticsearch version 7.7.0
- Elasticsearch version 7.6.2
- Elasticsearch version 7.6.1
- Elasticsearch version 7.6.0
- Elasticsearch version 7.5.2
- Elasticsearch version 7.5.1
- Elasticsearch version 7.5.0
- Elasticsearch version 7.4.2
- Elasticsearch version 7.4.1
- Elasticsearch version 7.4.0
- Elasticsearch version 7.3.2
- Elasticsearch version 7.3.1
- Elasticsearch version 7.3.0
- Elasticsearch version 7.2.1
- Elasticsearch version 7.2.0
- Elasticsearch version 7.1.1
- Elasticsearch version 7.1.0
- Elasticsearch version 7.0.0
- Elasticsearch version 7.0.0-rc2
- Elasticsearch version 7.0.0-rc1
- Elasticsearch version 7.0.0-beta1
- Elasticsearch version 7.0.0-alpha2
- Elasticsearch version 7.0.0-alpha1
- Dependencies and versions
Cross-cluster replication
editCross-cluster replication
editWith cross-cluster replication, you can replicate indices across clusters to:
- Continue handling search requests in the event of a datacenter outage
- Prevent search volume from impacting indexing throughput
- Reduce search latency by processing search requests in geo-proximity to the user
Cross-cluster replication uses an active-passive model. You index to a leader index, and the data is replicated to one or more read-only follower indices. Before you can add a follower index to a cluster, you must configure the remote cluster that contains the leader index.
When the leader index receives writes, the follower indices pull changes from the leader index on the remote cluster. You can manually create follower indices, or configure auto-follow patterns to automatically create follower indices for new time series indices.
You configure cross-cluster replication clusters in a uni-directional or bi-directional setup:
- In a uni-directional configuration, one cluster contains only leader indices, and the other cluster contains only follower indices.
- In a bi-directional configuration, each cluster contains both leader and follower indices.
In a uni-directional configuration, the cluster containing follower indices must be running the same or newer version of Elasticsearch as the remote cluster. If newer, the versions must also be compatible as outlined in the following matrix.
Version compatibility matrix
Local cluster |
|||||||
Remote cluster |
5.0→5.5 |
5.6 |
6.0→6.6 |
6.7 |
6.8 |
7.0 |
7.1→7.x |
5.0→5.5 |
|
|
|
|
|
|
|
5.6 |
|
|
|
|
|
|
|
6.0→6.6 |
|
|
|
|
|
|
|
6.7 |
|
|
|
|
|
|
|
6.8 |
|
|
|
|
|
|
|
7.0 |
|
|
|
|
|
|
|
7.1→7.x |
|
|
|
|
|
|
|
Multi-cluster architectures
editUse cross-cluster replication to construct several multi-cluster architectures within the Elastic Stack:
- Disaster recovery in case a primary cluster fails, with a secondary cluster serving as a hot backup
- Data locality to maintain multiple copies of the dataset close to the application servers (and users), and reduce costly latency
- Centralized reporting for minimizing network traffic and latency in querying multiple geo-distributed Elasticsearch clusters, or for preventing search load from interfering with indexing by offloading search to a secondary cluster
Watch the cross-cluster replication webinar to learn more about the following use cases. Then, set up cross-cluster replication on your local machine and work through the demo from the webinar.
Disaster recovery and high availability
editDisaster recovery provides your mission-critical applications with the tolerance to withstand datacenter or region outages. This use case is the most common deployment of cross-cluster replication. You can configure clusters in different architectures to support disaster recovery and high availability:
Single disaster recovery datacenter
editIn this configuration, data is replicated from the production datacenter to the disaster recovery datacenter. Because the follower indices replicate the leader index, your application can use the disaster recovery datacenter if the production datacenter is unavailable.

Multiple disaster recovery datacenters
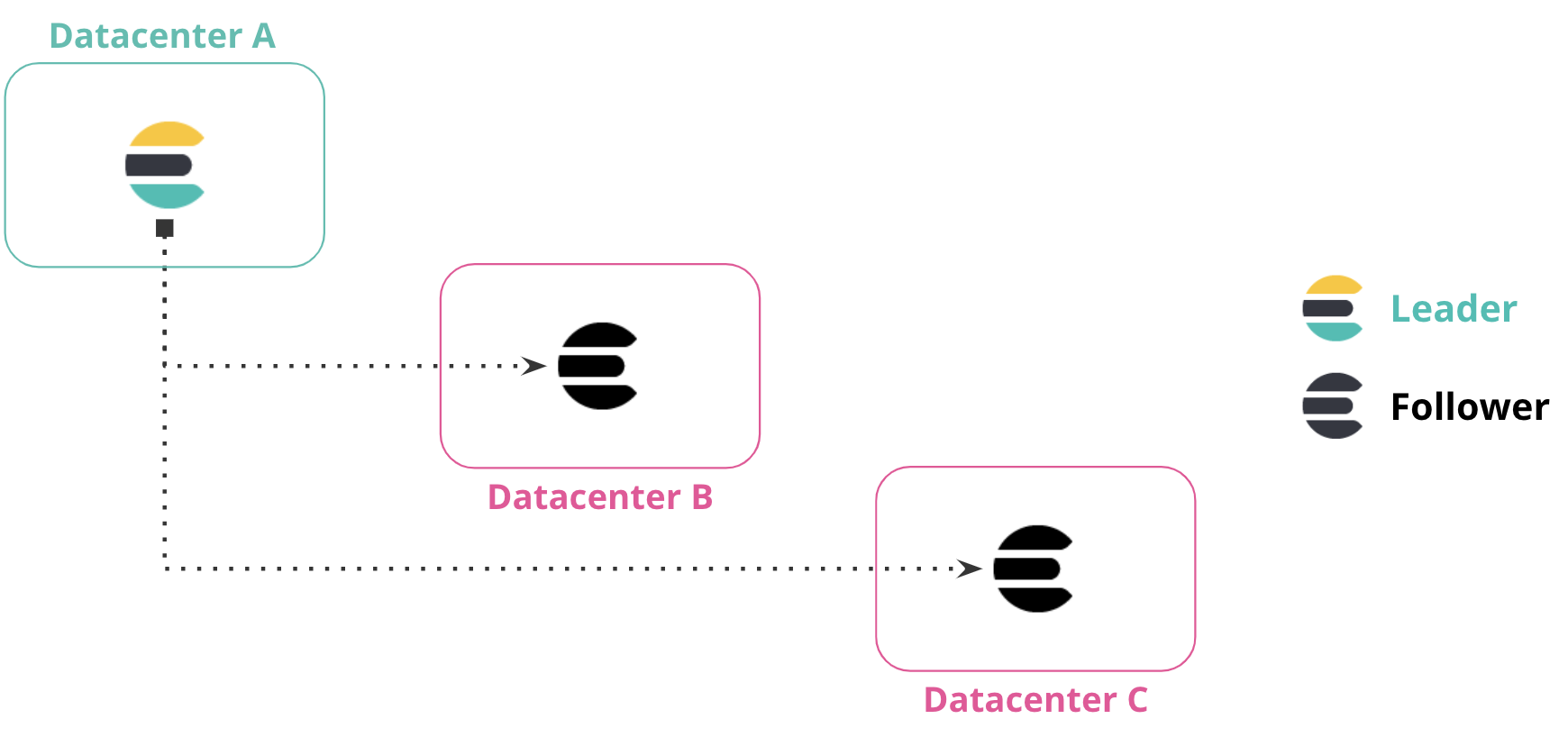
editYou can replicate data from one datacenter to multiple datacenters. This configuration provides both disaster recovery and high availability, ensuring that data is replicated in two datacenters if the primary datacenter is down or unavailable.
In the following diagram, data from Datacenter A is replicated to Datacenter B and Datacenter C, which both have a read-only copy of the leader index from Datacenter A.
Chained replication
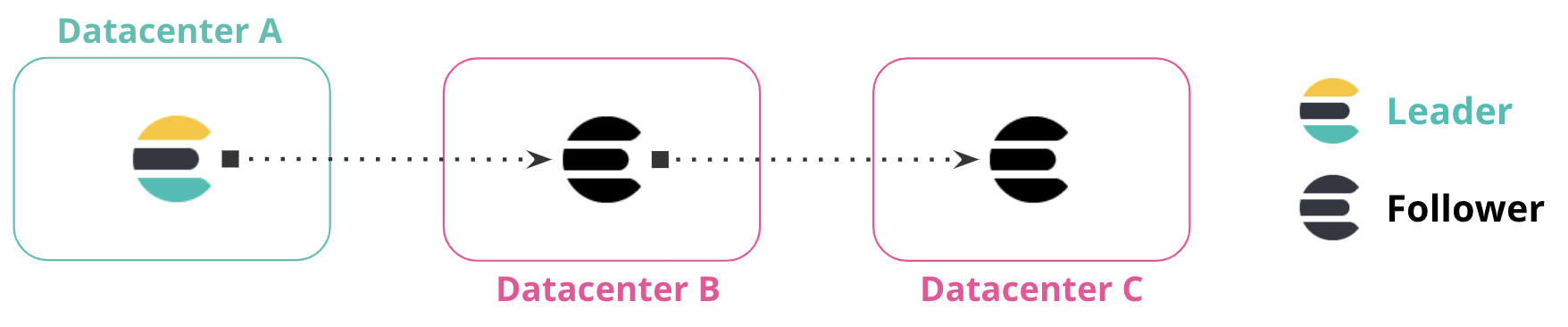
editYou can replicate data across multiple datacenters to form a replication chain. In the following diagram, Datacenter A contains the leader index. Datacenter B replicates data from Datacenter A, and Datacenter C replicates from the follower indices in Datacenter B. The connection between these datacenters forms a chained replication pattern.
Bi-directional replication
editIn a bi-directional replication setup, all clusters have access to view all data, and all clusters have an index to write to without manually implementing failover. Applications can write to the local index within each datacenter, and read across multiple indices for a global view of all information.
This configuration requires no manual intervention when a cluster or datacenter is unavailable. In the following diagram, if Datacenter A is unavailable, you can continue using Datacenter B without manual failover. When Datacenter A comes online, replication resumes between the clusters.
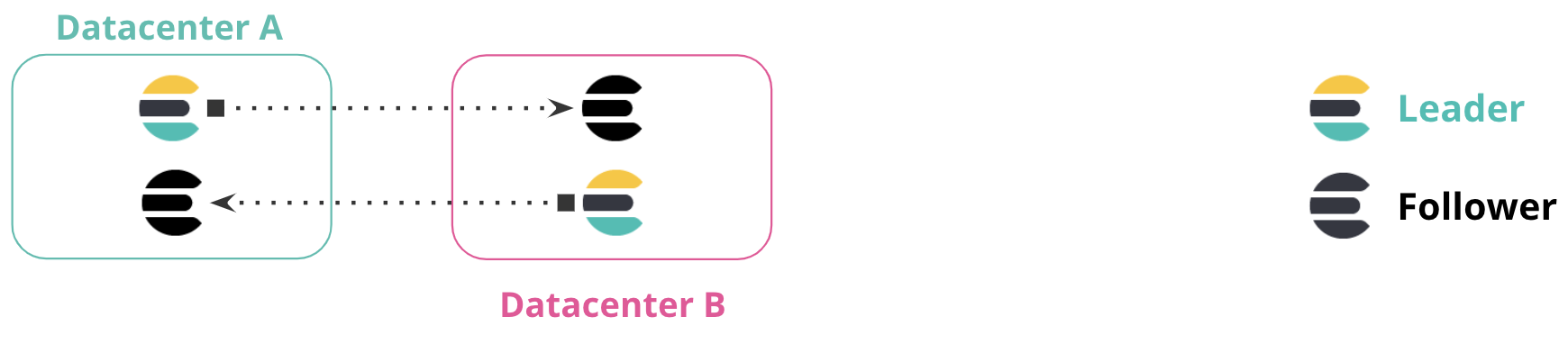
This configuration is useful for index-only workloads, where no updates to document values occur. In this configuration, documents indexed by Elasticsearch are immutable. Clients are located in each datacenter alongside the Elasticsearch cluster, and do not communicate with clusters in different datacenters.
Data locality
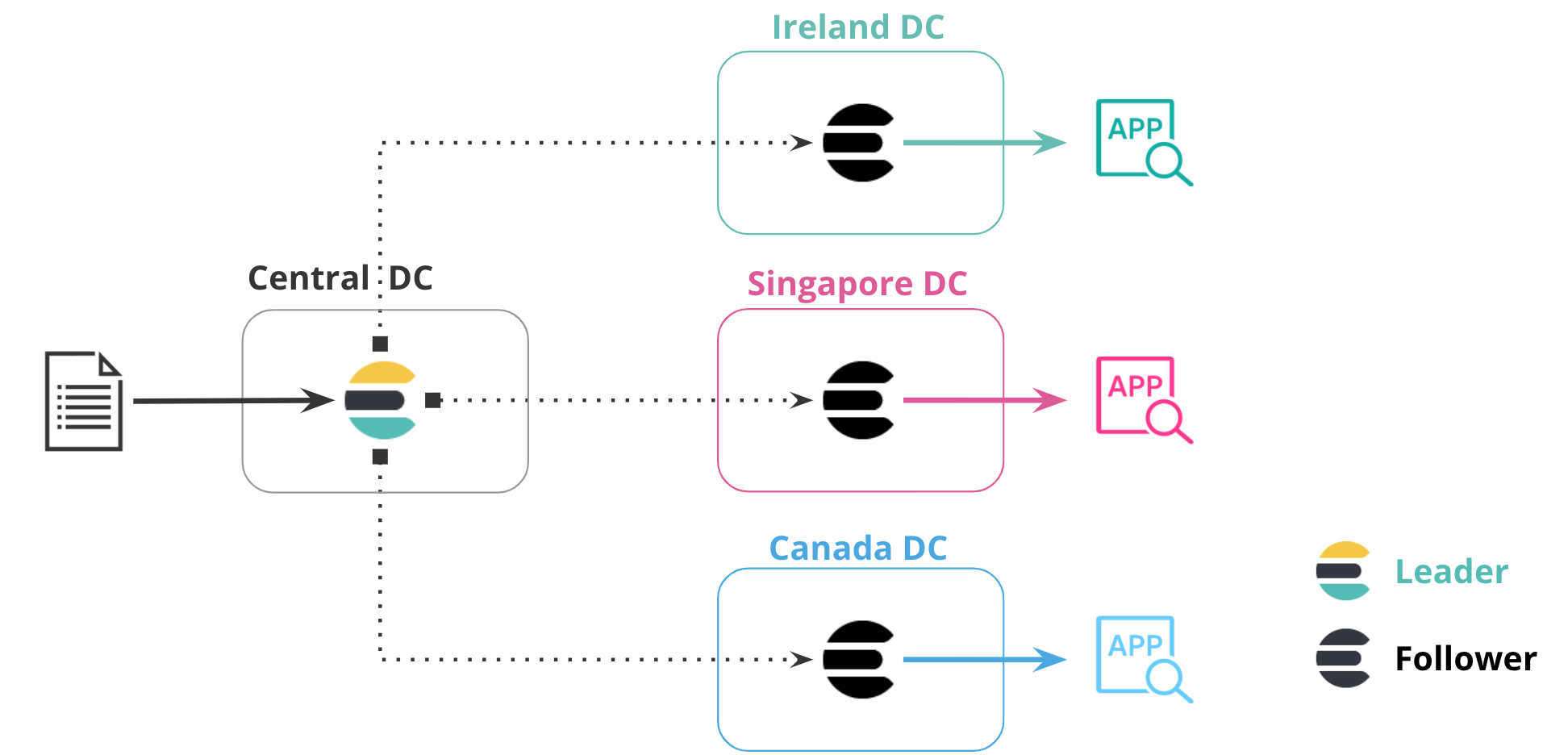
editBringing data closer to your users or application server can reduce latency and response time. This methodology also applies when replicating data in Elasticsearch. For example, you can replicate a product catalog or reference dataset to 20 or more datacenters around the world to minimize the distance between the data and the application server.
In the following diagram, data is replicated from one datacenter to three additional datacenters, each in their own region. The central datacenter contains the leader index, and the additional datacenters contain follower indices that replicate data in that particular region. This configuration puts data closer to the application accessing it.
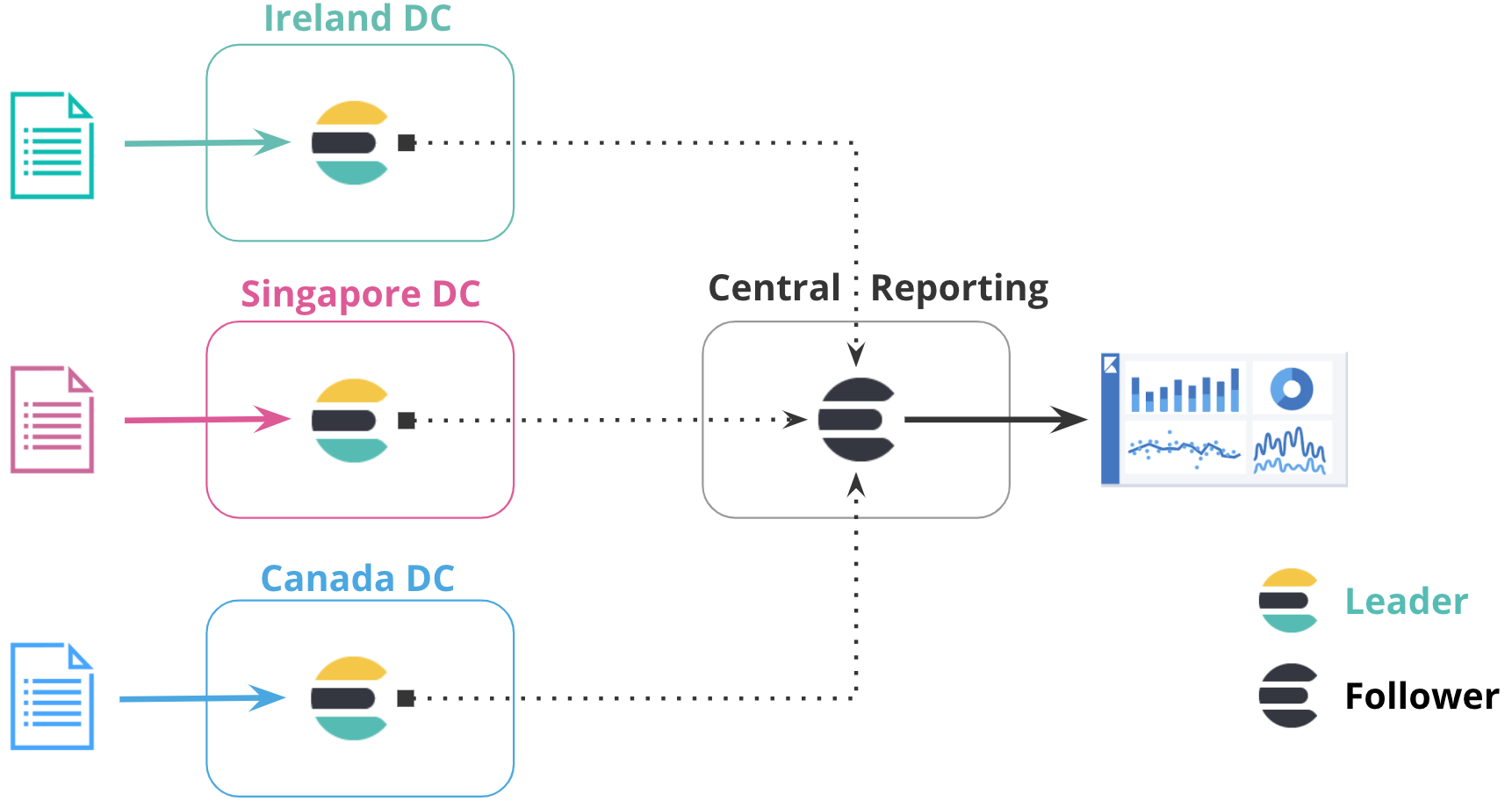
Centralized reporting
editUsing a centralized reporting cluster is useful when querying across a large network is inefficient. In this configuration, you replicate data from many smaller clusters to the centralized reporting cluster.
For example, a large global bank might have 100 Elasticsearch clusters around the world that are distributed across different regions for each bank branch. Using cross-cluster replication, the bank can replicate events from all 100 banks to a central cluster to analyze and aggregate events locally for reporting. Rather than maintaining a mirrored cluster, the bank can use cross-cluster replication to replicate specific indices.
In the following diagram, data from three datacenters in different regions is replicated to a centralized reporting cluster. This configuration enables you to copy data from regional hubs to a central cluster, where you can run all reports locally.
Replication mechanics
editAlthough you set up cross-cluster replication at the index level, Elasticsearch achieves replication at the shard level. When a follower index is created, each shard in that index pulls changes from its corresponding shard in the leader index, which means that a follower index has the same number of shards as its leader index. All operations on the leader are replicated by the follower, such as operations to create, update, or delete a document. These requests can be served from any copy of the leader shard (primary or replica).
When a follower shard sends a read request, the leader shard responds with any new operations, limited by the read parameters that you establish when configuring the follower index. If no new operations are available, the leader shard waits up to the configured timeout for new operations. If the timeout elapses, the leader shard responds to the follower shard that there are no new operations. The follower shard updates shard statistics and immediately sends another read request to the leader shard. This communication model ensures that network connections between the remote cluster and the local cluster are continually in use, avoiding forceful termination by an external source such as a firewall.
If a read request fails, the cause of the failure is inspected. If the cause of the failure is deemed to be recoverable (such as a network failure), the follower shard enters into a retry loop. Otherwise, the follower shard pauses until you resume it.
When a follower shard receives operations from the leader shard, it places those operations in a write buffer. The follower shard submits bulk write requests using operations from the write buffer. If the write buffer exceeds its configured limits, no additional read requests are sent. This configuration provides a back-pressure against read requests, allowing the follower shard to resume sending read requests when the write buffer is no longer full.
To manage how operations are replicated from the leader index, you can configure settings when creating the follower index.
The follower index automatically retrieves some updates applied to the leader index, while other updates are retrieved as needed:
Update type |
Automatic |
As needed |
Alias |
|
|
Mapping |
|
|
Settings |
|
|
For example, changing the number of replicas on the leader index is not replicated by the follower index, so that setting might not be retrieved.
You cannot manually modify a follower index’s mappings or aliases.
If you apply a non-dynamic settings change to the leader index that is needed by the follower index, the follower index closes itself, applies the settings update, and then re-opens itself. The follower index is unavailable for reads and cannot replicate writes during this cycle.
Initializing followers using remote recovery
editWhen you create a follower index, you cannot use it until it is fully initialized. The remote recovery process builds a new copy of a shard on a follower node by copying data from the primary shard in the leader cluster.
Elasticsearch uses this remote recovery process to bootstrap a follower index using the data from the leader index. This process provides the follower with a copy of the current state of the leader index, even if a complete history of changes is not available on the leader due to Lucene segment merging.
Remote recovery is a network intensive process that transfers all of the Lucene segment files from the leader cluster to the follower cluster. The follower requests that a recovery session be initiated on the primary shard in the leader cluster. The follower then requests file chunks concurrently from the leader. By default, the process concurrently requests five 1MB file chunks. This default behavior is designed to support leader and follower clusters with high network latency between them.
You can modify dynamic remote recovery settings to rate-limit the transmitted data and manage the resources consumed by remote recoveries.
Use the recovery API on the cluster containing the follower
index to obtain information about an in-progress remote recovery. Because Elasticsearch
implements remote recoveries using the
snapshot and restore infrastructure, running remote
recoveries are labelled as type snapshot in the recovery API.
Replicating a leader requires soft deletes
editCross-cluster replication works by replaying the history of individual write operations that were performed on the shards of the leader index. Elasticsearch needs to retain the history of these operations on the leader shards so that they can be pulled by the follower shard tasks. The underlying mechanism used to retain these operations is soft deletes.
A soft delete occurs whenever an existing document is deleted or updated. By retaining these soft deletes up to configurable limits, the history of operations can be retained on the leader shards and made available to the follower shard tasks as it replays the history of operations.
The index.soft_deletes.retention_lease.period setting defines the
maximum time to retain a shard history retention lease before it is
considered expired. This setting determines how long the cluster containing
your leader index can be offline, which is 12 hours by default. If a shard copy
recovers after its retention lease expires, then Elasticsearch will fall back to copying
the entire index, because it can no longer replay the missing history.
Soft deletes must be enabled for indices that you want to use as leader indices. Soft deletes are enabled by default on new indices created on or after Elasticsearch 7.0.0.
Cross-cluster replication cannot be used on existing indices created using Elasticsearch 7.0.0 or earlier, where soft deletes are disabled. You must reindex your data into a new index with soft deletes enabled.
Use cross-cluster replication
editThis following sections provide more information about how to configure and use cross-cluster replication:
On this page
- Multi-cluster architectures
- Disaster recovery and high availability
- Single disaster recovery datacenter
- Multiple disaster recovery datacenters
- Chained replication
- Bi-directional replication
- Data locality
- Centralized reporting
- Replication mechanics
- Initializing followers using remote recovery
- Replicating a leader requires soft deletes
- Use cross-cluster replication